Die fortschreitende Integration von künstlicher Intelligenz in Unternehmensanwendungen stellt Führungskräfte vor neue Herausforderungen. Insbesondere große Sprachmodelle (Large Language Models, LLMs) sind zwar beeindruckend, stoßen jedoch bei der Zuverlässigkeit und Aktualität von Daten an Grenzen. Hier bietet Retrieval-Augmented Generation, kurz RAG, eine leistungsstarke Architektur, die LLMs mit aktuellen und vertrauenswürdigen Informationsquellen verbindet. Der Einsatz von RAG-Systemen ermöglicht nicht nur eine deutlich verbesserte Genauigkeit der Antworten, sondern legt gleichzeitig einen soliden Grundstein für rechtskonforme und sichere KI-Anwendungen im Unternehmensumfeld. Zu Beginn jeder erfolgreichen RAG-Implementierung steht eine umfassende Analyse der Anforderungen.
Unternehmen müssen den Performancebedarf genau definieren: Wie schnell soll die Antwortzeit sein? Welche Durchsatzrate an Anfragen ist zu erwarten? Welches Genauigkeitsniveau wird als akzeptabel angesehen? Auch die Beschaffenheit der zugrundeliegenden Daten spielt eine entscheidende Rolle. Hierbei sind Volumen, Formatvielfalt und Aktualisierungsfrequenz wichtige Faktoren. Ebenso beeinflussen Budgetrestriktionen die Architekturwahl und die Technologien, die zum Einsatz kommen. Ein besonders kritischer Teil der RAG-Systeme ist die Datenaufnahme, der sogenannte Ingestion- beziehungsweise Aufbereitungspipeline. Sie bildet das Fundament, auf dem der gesamte Prozess aufbaut.
Rohdaten müssen aus vielfältigen Quellen wie PDFs, Webseiten, Datenbanken oder APIs zuverlässig extrahiert, bereinigt und sinnvoll segmentiert werden. Techniken zur Aufteilung der Inhalte – auch Chunking genannt – sollten so gewählt werden, dass der Kontext bestmöglich erhalten bleibt. Optimal sind meist segmentlängen zwischen 200 und 1000 Token mit Überlappungsbereichen, um Bruchstellen im Textfluss zu vermeiden. Zusätzlich erlaubt die Anreicherung der Segmente mit Metadaten, beispielsweise Quellinformationen oder Erstellungsdatum, die spätere Filterung und verbesserte Kontextualisierung. Nach der Datenvorbereitung werden die Textsegmente in Vektordarstellungen umgewandelt.
Dabei spielen Embeddings eine Schlüsselrolle, die semantische Bedeutungen in numerische Formate konvertieren. Hierbei ist die Wahl des Embedding-Modells entscheidend: Es sollte optimal auf die Domäne abgestimmt sein, performant arbeiten und die Kosten- sowie Infrastrukturvorgaben einhalten. Je nach Anwendungsfall bieten sich proprietäre Modelle wie OpenAI’s text-embedding-3-large an oder leistungsfähige Open-Source-Alternativen wie BGE-Large oder Ember-V1. In manchen Szenarien lohnt sich zudem die Feinabstimmung eigener Embedding-Modelle, um die Retrieval-Qualität deutlich zu steigern. Die Speicherung und das schnelle Abrufen der Daten erfolgt in sogenannten Vektordatenbanken.
Hier existieren managed Services wie Pinecone, die einfache und skalierbare Lösungen bieten, oder Self-Hosting-Lösungen wie Weaviate, Milvus oder Qdrant, die ausgefeilte Unterstützung für komplexe Filterung und hybride Suche ermöglichen. Die Indexierungstechnik, zum Beispiel HNSW (Hierarchical Navigable Small World Graphs), lässt sich mittels Parameteroptimierung hinsichtlich Genauigkeit und Geschwindigkeit feinjustieren. Dabei ist ein ausgewogenes Verhältnis zwischen Suchtreffsicherheit und Speicher-/Verarbeitungsaufwand essenziell. Der Herzstückprozess des RAG-Systems bildet die Retrieval-Mechanik: Sie übersetzt Benutzeranfragen in relevante Dokumentfragmente, die als Kontext für die anschließende Generierung dienen. Während einfache Systeme rein auf Ähnlichkeitssuche mittels Vektorvergleich basieren, kommt in professionellen Umgebungen immer häufiger eine hybride Suche zum Einsatz.
Dabei werden dichte Vektorretrievals mit klassischen Schlüsselwort-Suchalgorithmen kombiniert und später durch Re-Ranking-Verfahren optimiert. Zudem verbessern Techniken wie LLM-gestützte Query-Erweiterungen oder Umformungen die Treffergenauigkeit erheblich, insbesondere bei fachspezifischer Terminologie. Für die Antwortgenerierung ist eine durchdachte Integration der kontextualisierten Daten entscheidend. Die abgefragten Dokumente werden in eine angepasste Eingabe geschickt, die das Sprachmodell präzise anweist, nur auf den bereitgestellten Informationen zu basieren und diese zu zitieren. Die sorgfältige Gestaltung des Prompts beeinflusst sowohl die Genauigkeit als auch die Verlässlichkeit des Outputs.
Da große Sprachmodelle jedoch tokenbegrenzt sind, müssen Strategien zur Kontextfensterverwaltung implementiert werden. Dazu gehören das Priorisieren relevanter Segmente, das Komprimieren weniger wichtiger Inhalte durch automatische Zusammenfassungen und das Führen von Kontext-Pipelines, die den Informationsgehalt über mehrere Anfragen hinweg bewahren. Die Auswahl des Generierungsmodells hängt von den Anforderungen an Genauigkeit, Latenz und Budget ab. Während proprietäre Frontier-Modelle wie GPT-4 oder Claude 3 die höchste Leistungsfähigkeit bieten, gibt es zunehmend hochentwickelte Open-Source-Modelle mit guter Performance und Kostenkontrolle. Kleinere spezialisierte Modelle sind hingegen ideal für latenzkritische oder Ressourcenbeschränkte Umgebungen.
Für spezielle Anwendungsfälle bietet sich außerdem das Training oder Feintuning von Modellen an, um beim Wissenserwerb und der Domänengenauigkeit bessere Resultate zu erzielen. Ein erfolgreichen Einsatz des kompletten Systems garantiert erst die kontinuierliche Überwachung und Optimierung. Ein umfassendes Monitoring berücksichtigt Latenzen einzelner Komponenten, Anfragevolumen, Fehlerraten und Ressourcenverbrauch. Ebenso wichtig ist die Qualitätsbewertung von Retrieval-Ergebnissen und generierten Antworten anhand von standardisierten Metriken. Dazu zählen unter anderem Präzision, Recall, Factuality- und Hallucination-Raten.
Moderne Ansätze arbeiten mit LLM-basierten automatische Bewertungen und Kombinationen aus humaner und maschineller Evaluation. Ein kritischer Faktor bei der produktionsreifen Nutzung von RAG-Systemen ist die Sicherheit und Governance. Die Implementierung von fein granularen Zugriffskontrollen, etwa Row-Level Security, stellt sicher, dass Anwender nur auf autorisierte Inhalte zugreifen können. Hier werden Metadaten-basierte Filter, rollenbasierte Zugriffsrechte sowie Ende-zu-Ende-Verschlüsselung kombiniert, um Datenschutz und Compliance zu gewährleisten. Die konsequente Nachverfolgung von Datenherkunft und Antwortlineage ist unerlässlich, um Auditfähigkeit bei regulatorischen Anforderungen zu garantieren.
Betriebliche Zuverlässigkeit ist nicht zuletzt durch geeignete Disaster Recovery Konzepte sicherzustellen. Multi-Region-Deployment, automatisierte Snapshot-Backups und regelmäßige Wiederherstellungstests verhindern Datenverluste und gewährleisten hohe Verfügbarkeit. Modellversionierung und kontrollierte Rollbacks minimieren Risiken bei Updates von embeddings oder Sprachmodellen. Die Kostenstruktur von RAG-Lösungen setzt sich aus mehreren Komponenten zusammen. API-Nutzung für Embeddings und Generierung, Speicher- und Verarbeitungsressourcen im Vector Store, Infrastrukturkosten sowie Entwicklungs- und Betriebsaufwand müssen genau kalkuliert werden.
Effiziente Strategien wie Batch-Verarbeitung, Caching, Kontextoptimierung und Modell-Hybride helfen, TCO zu verringern und ermöglichen Skalierung mit Planbarkeit. Je nach Unternehmensgröße und Marktreife des Produkts empfiehlt sich ein abgestuftes Implementierungskonzept. Kleine Teams profitieren von Managed Services und einem Fokus auf Kernfunktionalitäten, während reifere Organisationen verstärkt hybride Lösungen mit eigenen Custom-Komponenten einsetzen und eine klare Aufgabenteilung zwischen Teams etablieren. Für stark regulierte oder hochskalierende Anwendungen sind maßgeschneiderte RAG-Pipelines mit robusten Sicherheits- und Compliancevorkehrungen unverzichtbar. Innovative Techniken wie Retrieval-Augmented Fine-Tuning (RAFT) forschen daran, Retrieve- und Generierungsprozesse noch tiefer zu verschmelzen und so die Robustheit gegenüber irrelevanten Dokumenten zu erhöhen.
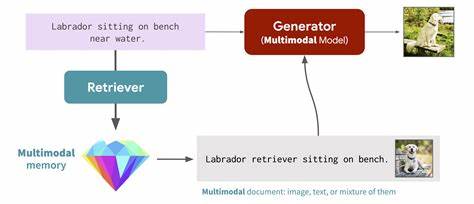
Auch Multimodale RAG-Modelle oder agentenbasierte Systeme, die selbst strategische Entscheidungen treffen, zeigen großes Potenzial für künftige Entwicklungsschritte. Grundsätzlich können Unternehmen durch den Einsatz produktionsreifer RAG-Systeme die Grenzen klassischer LLM-Anwendungen überwinden. Die Kombination aus aktuellem Wissen, skalierbarer Infrastruktur, umfangreichen Sicherheitsmechanismen und fundierter Evaluierung ermöglicht den Aufbau vertrauenswürdiger KI-Lösungen mit hohem Mehrwert. RAG wird so zu einem zentralen Baustein moderner KI-getriebener Anwendungsszenarien im Enterprise-Umfeld.