Die Entwicklung moderner Softwarelösungen hat mit dem Aufkommen von Software as a Service (SaaS) einen bedeutenden Wandel erfahren. Insbesondere die Multi-Tenant Datenarchitektur spielt dabei eine zentrale Rolle, da sie die Basis dafür bildet, wie mehrere Kunden, sogenannte Mieter oder Tenants, ihre Daten sicher und effizient innerhalb einer gemeinsamen Umgebung verwalten können. Daten sind für Unternehmen das wertvollste Gut, sie umfassen Kundeninformationen, Produktdetails, Mitarbeiterdaten und vieles mehr. Der sichere Umgang mit diesen Daten ist daher von höchster Priorität für SaaS-Anbieter, die ihren Kunden den Zugriff über das Internet ermöglichen. Gleichwohl müssen SaaS-Architekten einen Spagat meistern: Einerseits die geforderte Sicherheit und Isolierung der Daten der einzelnen Kunden, andererseits die Wirtschaftlichkeit und Skalierbarkeit der Lösung.
Multi-Tenant Datenarchitektur ist nicht nur ein technisches Thema, sondern auch ein entscheidender Faktor für Vertrauen zwischen dem Anbieter und seinen Kunden. Die wichtigste Herausforderung besteht darin, eine Balance zwischen Isolation und gemeinsamer Nutzung der Infrastruktur zu schaffen. Isolation garantiert, dass kein Tenant die Daten eines anderen einsehen oder verändern kann, während die gemeinsame Nutzung Ressourcen spart und Erfolgschancen durch Skaleneffekte bietet. Die Architektur für eine SaaS-Lösung bewegt sich hierbei auf einem Kontinuum zwischen vollständig isolierten Daten und komplett geteilten Daten im gleichen Speicher. Es existieren drei prominente Ansätze zur Organisation von Multi-Tenant Daten in SaaS-Anwendungen.
Die erste Möglichkeit besteht darin, dass jeder Tenant eine eigene, separate Datenbank erhält. Diese Herangehensweise gewährleistet die höchste Stufe an Datenisolation durch vollständige physische Trennung. Hier teilen sich zwar eventuell die Anwendung und die Rechenressourcen den Server, die Datenbanken jedoch sind streng voneinander getrennt. Dies erleichtert individuelle Datenmodellerweiterungen für einzelne Mieter und ermöglicht unkomplizierte Backups sowie Wiederherstellungen. Gleichzeitig verursacht diese Methode höhere Hardware- und Wartungskosten, da jede Datenbank eigenen Ressourcenbedarf bedeutet.
Aufgrund der begrenzten Anzahl Datenbanken, die ein Server gleichzeitig effizient handhaben kann, ist die Skalierbarkeit limitiert. Aus diesem Grund ist das Modell vor allem für Kunden mit besonders hohen Sicherheits- und Anpassungsanforderungen, beispielsweise im Finanz- oder Gesundheitssektor, geeignet. Der zweite Ansatz basiert auf einer gemeinsamen Datenbank, in der jeder Tenant eine eigene Schema-Struktur besitzt. Ein Schema kann als Sammlung von Tabellen verstanden werden, die logisch zusammengefasst werden und die jeweiligen Daten eines Tenants beinhalten. Dieses Verfahren verlangt, dass neue Tabellen für jeden Mieter innerhalb der bestehenden Datenbank erzeugt und ihn entsprechend zugeordnet werden.
Dadurch entsteht eine moderate Datenisolation, denn obwohl alle Daten in der selben Datenbank gespeichert sind, sind sie dennoch logisch voneinander getrennt. Dies bedeutet geringere Hardwarekosten und eine effizientere Nutzung von Ressourcen im Vergleich zum ersten Modell. Allerdings gestaltet sich die Wiederherstellung von Einzeltantendaten im Fehlerfall komplexer, da hier meist eine vollständige Wiederherstellung der gemeinsamen Datenbank nötig ist und anschließend nur die gewünschten Schema-Daten rückgespielt werden können. Dieses Modell eignet sich besonders für SaaS-Anwendungen mit einer begrenzten Anzahl an Tabellen für jeden Tenant und ist sinnvoll, wenn eine größere Anzahl Kunden bei vertretbaren Kosten unterstützt werden soll. Die dritte Variante zeichnet sich dadurch aus, dass alle Tenant-Daten in der gleichen Datenbank und in denselben Tabellen gespeichert werden.
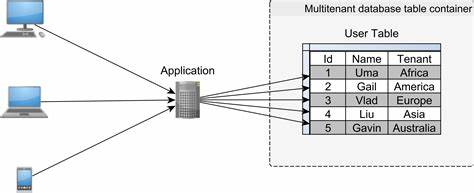
Jede Datenzeile enthält eine Tenant-ID, die den Datensatz eindeutig einem Mieter zuordnet. Während dies die kostengünstigste Lösung ist, da sich so eine Datenbank auf sehr viele Kunden ausdehnen lässt, bringt sie den höchsten Entwicklungsaufwand mit sich. Sicherheit muss hier besonders gründlich gestaltet werden, um sicherzustellen, dass kein Tenant unbeabsichtigt oder durch Angriffe Zugriff auf fremde Daten erhält. Dazu dienen Mechanismen wie SQL-Views mit speziell gefilterten Zugriffsrechten oder umfassende Verschlüsselung. Sollte es zu einem Datenverlust kommen, erschwert die geteilte Tabelle die Wiederherstellung, da nur einzelne Datensätze entfernt und ersetzt werden können, was bei großen Datenmengen die Performance negativ beeinflussen kann.
Dieses Modell empfiehlt sich für Anwendungen mit sehr vielen Kunden, bei denen eine kompromissbereite Sicherheitsstrategie und geringe Kosten im Vordergrund stehen. Die Entscheidung für einen der beschriebenen Ansätze hängt maßgeblich von wirtschaftlichen, sicherheitstechnischen, regulatorischen und technischen Faktoren ab. Anwendungen mit geteilten Datenstrukturen erfordern einen größeren Entwicklungsaufwand anfangs, amortisieren sich aber durch geringere Betriebskosten und eine bessere Skalierbarkeit langfristig. Wenn beispielsweise ein Unternehmen eine schnelle Markteinführung benötigt oder begrenzte Entwicklungskapazitäten hat, kann die isolierte Variante eine sinnvolle Wahl sein. Ebenso prägen die Anzahl der zu erwartenden Tenants, das Datenvolumen je Tenant und deren Nutzungsverhalten die Auswahl.
Unternehmen, die hohe Anforderungen an Datensicherheit und Datenintegrität stellen, bevorzugen meist isolierte Modelle, während SaaS-Anbieter mit großem Skalierungsbedarf oft einen geteilten Ansatz wählen. Besondere Aufmerksamkeit verdienen auch regulatorische Auflagen, die in manchen Branchen eine physische Trennung von Daten vorschreiben können. Die Sicherheit in einer Multi-Tenant Datenarchitektur ist ein komplexes und vielschichtiges Thema. Es gilt, das Prinzip der „Verteidigung in der Tiefe“ zu verfolgen, das mehrere Sicherungsebenen integriert. Dazu zählen neben den klassischen Zugangsbeschränkungen auch verschlüsselte Datenhaltung und filternde Mechanismen, die nur den Zugriff auf zulässige Daten erlauben.
Ein besonders effektives Mittel ist die Kombination von Datenbankzugriffsmodellen, bei denen das System sowohl mit der Identität des Tenant als auch mit der des einzelnen Endanwenders operiert. Diese Hybridlösung erlaubt es, den Zugriff granular zu steuern, ohne die Übersichtlichkeit und Verwaltbarkeit zu verlieren. Datenbanksicherheit umfasst das gezielte Erteilen von Zugriffsrechten über Berechtigungslisten, die Einschränkung von Sichtbarkeiten durch SQL-Views und den Einsatz robuster Verschlüsselungsverfahren für sensible Datenbereiche. Verschlüsselung wird in SaaS-Architekturen oftmals in einem mehrstufigen Verfahren realisiert, bei dem ein symmetrischer Schlüssel für die eigentliche Datenverschlüsselung genutzt und dieser Schlüssel wiederum mit einem asymmetrischen Schlüssel verschlüsselt wird. Dies erhöht den Schutz der sensiblen Informationen deutlich, ohne die Alltagsperformance zu stark zu beeinträchtigen.
Neben der Sicherheit muss die Datenarchitektur auch flexibel genug sein, um sich an die individuellen Anforderungen unterschiedlicher Kunden anzupassen. Viele Unternehmen benötigen Erweiterungsmöglichkeiten, die über das standardisierte Datenmodell hinausgehen. Für solche Fälle gibt es verschiedene Muster, um Anpassungen und Erweiterungen zu ermöglichen. So kann eine feste Anzahl von „Preallocated Fields“ implementiert werden, die von Mietern genutzt und durch Metadaten entsprechend eingestuft werden können. Dies gelingt durch einheitliche Datentypisierung, meist auf String-Basis, ergänzt durch Validierungsregeln auf Applikationsebene.
Für noch flexiblere Erweiterungen bietet sich das Konzept von Name-Value-Paars an, bei dem kundenspezifische Felder dynamisch in separaten Tabellen abgelegt und über Metadaten verwaltet werden. Diese Entkopplung erlaubt eine praktisch unbegrenzte Anzahl benutzerspezifischer Felder. Allerdings steigt damit die Komplexität bei Abfragen, Indizierung und Verwaltungsoperationen, was sich auf Performanz und Entwicklungsaufwand auswirken kann. Schließlich gibt es die Möglichkeit, für einzelne Kunden eigene, angepasste Datenmodelle durch zusätzliche Spalten in dedizierten Tabellen bereitzustellen – dies ist jedoch den separaten Datenbank- oder Schema-basierten Ansätzen vorbehalten. Schließlich spielt Skalierbarkeit eine entscheidende Rolle in SaaS-Architekturen.
Da tausende oder gar Millionen von Nutzern gleichzeitig auf die Systeme zugreifen, müssen Datenbanken erweiterbar sein, ohne dass dies negative Auswirkungen auf die Performance hat. Skalierung lässt sich sowohl vertikal – durch Upgrade auf leistungsfähiger Hardware – als auch horizontal – durch Verteilung von Datenlast auf mehrere Server – umsetzen. Replikation und Partitionierung sind dabei zentrale Technologien. Für geteilte Datenbanken bietet sich Tenant-basierte horizontale Partitionierung an. Hierbei wird die Datenbank nach Tenant-IDs auf mehrere Datenbankserver verteilt, um Belastungsspitzen zu minimieren und Speicherkapazitäten besser zu nutzen.
Wichtig ist eine intelligente Zuweisung, die Last und Datenvolumen der einzelnen Tenants berücksichtigt, um eine möglichst optimale Verteilung zu erreichen. Dies erfordert kontinuierliche Überwachung und regelmäßige Anpassungen, wenn sich die Nutzungsmuster verändern. Falls ein einzelner Tenant sehr große Datenmengen verwendet oder viele Nutzer gleichzeitig aufwendet, besteht die Möglichkeit, diesen Kunden auf eine eigene dedizierte Datenbank auszulagern. Diese einzelne Datenbank kann dann eigenständig skaliert werden, unter anderem durch vertikale Erweiterungen oder feingliedrige Partitionierung des Datenbestands. Abschließend lässt sich festhalten, dass die Wahl der geeigneten Multi-Tenant Datenarchitektur essentiell für den Erfolg von SaaS-Lösungen ist.
Die verschiedenen Ansätze bieten unterschiedliche Vor- und Nachteile hinsichtlich Sicherheit, Kosten, Skalierbarkeit und Flexibilität. Zudem sind Investitionen in durchdachte Sicherheitsmechanismen und erweiterbare Datenmodelle unabdingbar, um Kundenvertrauen aufzubauen und individuell auf Geschäftsanforderungen einzugehen. Im Zuge der fortschreitenden Digitalisierung und steigender Cloud-Nutzung wird die Bedeutung der Multi-Tenant Datenarchitektur weiter zunehmen, sodass Entwickler und Architekten diesem Thema verstärkte Aufmerksamkeit schenken sollten.