Die Welt des Hochleistungsrechnens (High-Performance Computing, HPC) steht heute vor einer bedeutenden Herausforderung, die Leistungsfähigkeit wissenschaftlicher Anwendungen stetig zu verbessern und gleichzeitig nachhaltige, energieeffiziente Lösungen zu gewährleisten. In diesem Kontext gewinnt die Beschleunigung von Fortran-Intrinsics durch spezialisierte Hardware wie die AMD AI Engines zunehmend an Bedeutung. Diese Entwicklung verspricht, wissenschaftliche Programme auf völlig neue Leistungsstufen zu heben, ohne dass Programmierer umfangreiche Änderungen am Code vornehmen müssen. Fortran, als eine der ältesten und immer noch vielgenutzten Programmiersprachen im Bereich des wissenschaftlichen Rechnens, hat sich über Jahrzehnte als robust und performant bewährt. Trotz des Aufkommens moderner Programmiersprachen stellt Fortran einen unverzichtbaren Standard für numerisch intensive Workloads dar.
Allerdings treten auch hier Herausforderungen auf, wenn es um die optimale Nutzung moderner Hardware geht. Traditionelle CPUs stoßen an Grenzen hinsichtlich Leistung und Energieeffizienz, was den Einsatz spezialisierter Beschleuniger unumgänglich macht. Die AMD AI Engines (AIEs), ein integraler Bestandteil der AMD Ryzen AI-CPUs, bieten eine innovative Architektur, die speziell auf parallele, rechenintensive Aufgaben ausgerichtet ist. Sie versprechen signifikante Vorteile im Hinblick auf Durchsatz und Energieverbrauch, doch die Herausforderung liegt in der praktikablen Programmierung solcher spezialisierter Einheiten. Entwickler müssen üblicherweise tiefe Hardwarekenntnisse besitzen, um das Potenzial dieser Einheiten auszuschöpfen, was Zeit und Ressourcen bindet und somit die breite Nutzung erschwert.
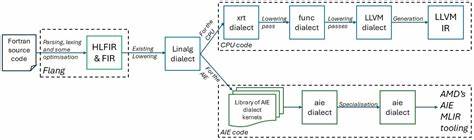
Hier setzt die jüngste Forschung und Entwicklung an, die eine nahtlose Beschleunigung von Fortran-Intrinsics durch die AMD AI Engines ermöglicht, ohne dass der Programmierer seinen ursprünglichen Code ändern muss. Die Lösung basiert auf der Integration fortschrittlicher Compiler-Technologien, insbesondere der Open-Source-Flang-Compiler-Infrastruktur in Kombination mit dem Multi-Level Intermediate Representation (MLIR) Ökosystem. Diese Werkzeuge erlauben es, Fortran-codebasierte lineare Algebra Operationen über Zwischendarstellungen automatisch in hardware-spezifische Instruktionen der AMD AI Engines zu übersetzen. Das Verfahren beginnt im Flang Compiler, der Fortran-Code in eine flexible, hardwareunabhängige Intermediate Representation übersetzt. Innerhalb des MLIR-Frameworks wird speziell der lineare Algebra-Dialekt genutzt, um mathematische Operationen auf einer abstrakten Ebene darzustellen.
Anschließend erfolgt ein gezieltes Herunterschreiben dieser High-Level-Operationen in AMD AIE-spezifische Dialekte, die direkt auf den AI Engines ausgeführt werden können. Dieser automatisierte Übersetzungsprozess eliminiert den bisher erforderlichen manuellen Optimierungsaufwand und erschließt intelligent die Leistungsfähigkeit der AI Engines für klassische wissenschaftliche Workloads. Die Vorteile dieser Herangehensweise sind vielfältig. Zum einen wird die Performance von rechenintensiven Fortran-Anwendungen deutlich erhöht, was in vielen Praxisbeispielen messbar ist. Die AI Engines profitieren dabei von ihrer parallelen Architektur und der spezialisierten Hardwarebeschleunigung, wodurch Rechenoperationen schneller und effizienter als auf herkömmlichen CPUs durchgeführt werden.
Zum anderen resultiert aus der Energieeffizienz der AI Engines eine reduzierte Leistungsaufnahme, was einen wichtigen Beitrag zu nachhaltigem HPC leistet. Ein weiterer zentraler Vorteil liegt in der Nutzerfreundlichkeit. Wissenschaftler und Entwickler können weiterhin mit bekannten Fortran-Intrinsics arbeiten, die automatisch bei der Kompilierung für die AI Engines optimiert werden. Dies beseitigt die häufige Barriere, die durch das Erlernen neuer Programmiermodelle oder Hardware-spezifischer Programmiertechniken entsteht. Die Nutzung vertrauter Werkzeuge und Sprachen in Kombination mit modernster Hardware bietet somit eine ideale Verbindung von Innovation und Praktikabilität.
Aus technischer Sicht zeigt sich auch, dass die Kombination aus Flang und MLIR eine zukunftsfähige Grundlage für weitere Optimierungen und Hardware-Integrationen bildet. Die modulare Architektur des MLIR-Frameworks ermöglicht es, weitere Dialekte und Target-Backends zu implementieren, was eine flexible Anpassung an neue Hardwaregenerationen und Beschleuniger erlaubt. Im Zusammenhang mit AMDs Investitionen in die AI Engine-Technologie eröffnet sich somit ein enormes Potenzial für langfristige Entwicklungen im HPC-Sektor. Darüber hinaus spiegelt diese Innovation auch den Trend in der Rechnerarchitektur wider, der immer stärker in Richtung heterogener Systeme mit spezialisierten Verarbeitungseinheiten geht. Die Zeiten monolithischer CPUs neigen sich dem Ende zu, während AI Engines, GPUs, FPGAs und andere Beschleuniger zunehmend zentrale Rollen einnehmen.
Die Fähigkeit, softwareseitig nahtlos zwischen diesen Architekturen zu vermitteln, wird zum entscheidenden Erfolgsfaktor. In vielen Bereichen wissenschaftlicher Forschung wie Klimamodelle, Strömungssimulationen, Materialwissenschaften oder numerische Methoden profitieren Anwender direkt von der Beschleunigung durch AI Engines. Bereits kleinere Leistungsverbesserungen können Forschungsschleifen verkürzen, Kosten senken und neue wissenschaftliche Fragestellungen erst praktikabel machen. Dabei spielt auch die Energieeffizienz eine Rolle für die Gesamtbetriebskosten und die ökologische Nachhaltigkeit großer Rechenzentren. Die Integration der automatischen Fortran-Beschleunigung in bestehende Compiler-Infrastrukturen trägt zudem zur Demokratisierung von HPC-Technologie bei.
Institutionen, die bisher keine großen Ressourcen in hardware-spezifische Optimierungen stecken konnten, erhalten Zugang zu leistungsfähigen Systemen, ohne ihre Arbeitsweise grundlegend ändern zu müssen. Dies fördert eine breitere Akzeptanz und Nutzung moderner Beschleunigertechnik. Nicht zuletzt zeigt die Kooperation zwischen akademischer Forschung und industriellen Partnern wie AMD, wie Innovationskraft und technische Expertise gebündelt werden kann. Die Veröffentlichung auf arXiv unterstreicht den offenen Zugang zu wichtigen Forschungsergebnissen und stärkt den kollaborativen Fortschritt in diesem essentiellen Technologiefeld. Zusammengefasst markiert die nahtlose Beschleunigung von Fortran-Intrinsics mittels AMD AI Engines einen bedeutenden Meilenstein für das Hochleistungsrechnen.
Die Verbindung aus bewährter Programmiersprache, moderner Compiler-Technologie und spezialisierter Hardware schafft eine effektive Lösung, die Leistung und Effizienz steigert und zugleich die Benutzerfreundlichkeit wahrt. Für die Zukunft zeichnen sich weitere Fortschritte ab, die das Potenzial haben, die wissenschaftliche Computergemeinschaft nachhaltig zu verändern und neue Möglichkeiten in Forschung und Entwicklung zu eröffnen.