Die Entwicklung großer Sprachmodelle hat in den letzten Jahren eine rasante Dynamik erfahren. Dabei spielt die Qualität und Transparenz der Trainingsdaten eine Schlüsselrolle. Vor rund viereinhalb Jahren revolutionierte EleutherAI mit der Veröffentlichung des Pile, einer 800 GB umfassenden, vielfältigen Textsammlung, die Landschaft der Sprachmodell-Datensätze. Pionierhaft war vor allem die Kombination aus kodiertem und natürlichem Sprachmaterial sowie die Integration bislang selten genutzter Quellen wie PubMed und StackExchange. Das Training auf etwa 300 Milliarden Tokens der GPT-2-Architektur setzte damals weltweit Maßstäbe in der Offenen KI-Forschung.
Mit der Veröffentlichung von GPT-Neo im Jahr 2021 wurde zudem das erste leistungsstarke Open-Source-Modell vorgestellt, das auf öffentlich zugänglichen Trainingsdaten basierte. Dieses Vorgehen lieferte einen wichtigen Beitrag für wissenschaftliche Reproduzierbarkeit und Transparenz. Die öffentliche Bereitstellung großer Trainingsdatensätze ist für die KI-Forschung essentiell. Ohne transparente Datenzugänge ist fundierte Arbeit zu Schlüsselthemen wie Gedächtnisreproduktion, Datenschutz, Datenkuratierung, Lernverläufen oder Fairness nicht möglich. Eine gemeinsame Datenbasis ermöglicht zudem kontrollierte Studien und direkte Vergleiche verschiedener Modellarchitekturen unter identischen Trainingsbedingungen.
Beispiele hierfür finden sich bei Projekten wie RWKV oder Mamba, die die Pile-Daten intelligent nutzten, um Leistung und Verhalten ihrer Modelle zu benchmarken. Somit wird nicht nur die Effizienz in der Forschung gesteigert, sondern auch das Risiko von Redundanzen vermieden. Darüber hinaus schafft eine transparente Datenoffenlegung Vertrauen in die Modellbewertungen, indem sie gegebenenfalls Datenlecks oder Überlappungen zwischen Trainings- und Testdaten aufdeckt. Trotz der erkennbaren Bedeutung offen zugänglicher Datensätze haben diverse rechtliche Konflikte in den letzten Jahren die Offenheit in der Branche deutlich eingeschränkt. Vergleichende Analysen zeigen, dass führende KI-Unternehmen wie OpenAI, Anthropic oder Google DeepMind zwischen 2020 und 2022 noch relativ umfassende Informationen zu ihren Trainingsdaten veröffentlichten.
Ab 2023 nahm die Transparenz dagegen ab – ein Trend, der dem Vertrauen und der Nachvollziehbarkeit der Modelle nicht zuträglich ist. Interessanterweise geben interne Quellen bei einigen Organisationen an, dass zunächst juristische Unsicherheiten die Veröffentlichung datenzentrierter Forschungsarbeiten erschweren. Während sich wenige Institutionen wie AI2, Hugging Face, Zyphra oder LLM360 dem Trend entgegenstellen, bleibt die Anzahl frei verfügbarer, großer Trainingsdatensätze deutlich hinter der Verbreitung fertig trainierter Modelle zurück. Offenheit ist mehr als nur ein Begriff – für Initiativen wie EleutherAI ist sie eine tief verwurzelte kulturelle Haltung. Daher hat die jüngste Veröffentlichung des Nachfolgers der Pile, des Common Pile v0.
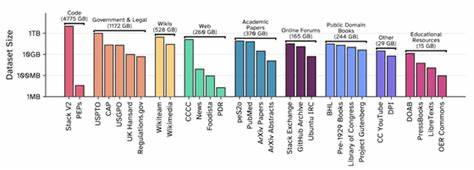
1, hohe Aufmerksamkeit erfahren. In mehrjähriger, akribischer Arbeit entstand ein Datensatz von erstaunlichen acht Terabyte zusammengesetzt aus Texten, die entweder gemeinfrei sind oder unter besonders offenen Lizenzen stehen. Die Zusammenarbeit mit angesehenen Forschungseinrichtungen wie der Universität Toronto, dem Vector Institute, dem Allen Institute for AI, MIT, CMU und weiteren unterstreicht die Bedeutung und das breite Interesse an einem solch umfangreichen, offenen Korpus. Ein zentrales Anliegen dieses Projekts war die Konzentration auf offene Lizenzen. Deren Auswahl erforderte intensive juristische Beratung, um sicherzustellen, dass sämtliche Daten rechtlich unbedenklich für das Training von Sprachmodellen genutzt werden können.
Dabei orientierten sich die Projektverantwortlichen an dem Open License Definition Framework der Open Knowledge Foundation und nahmen auch Copyleft-Lizenzen wie Share-Alike in ihre Kriterien auf. Der Zweck dahinter ist es, dass jede Person die Rechte erhält, das Material frei zu nutzen, zu studieren, zu modifizieren und weiterzugeben – unabhängig vom jeweiligen Anwendungszweck. Dies ist gerade im Bereich der KI wichtig, da viele gängige Open-Lizenzen den Umgang mit maschinellen Lernverfahren heute noch nicht explizit regeln. Die Bestimmung der zugrundeliegenden Lizenz eines einzelnen Werks erwies sich als weitaus komplexer als erwartet. Automatisierte Tools zur Lizenzidentifikation sind noch nicht hinreichend zuverlässig, weshalb man bei Common Pile stark auf verifizierte Metadaten und manuelle Evaluation angewiesen war.
Eine Ausnahme bildet der Programmiercode-Bereich, wo dank bewährter Werkzeuge der Software Heritage Foundation und des BigCode-Projekts ein sauber lizenzierter Teil des Stack v2 Repertoires aufgenommen werden konnte, der insbesondere für ML-Forschende von hohem Interesse ist. Bei gemeinfreien Werken stellt sich das Problem der Lizenzfrage nochmal anders dar, da Gemeinfreiheit per Definition kein Lizenzstatus ist, sondern vielmehr das Ablaufdatum oder die Abwesenheit von Copyright bedeutet. Diese Situation ist länderabhängig und oft schwer eindeutig belegbar. Institutionen, die gemeinfreie Werke bereitstellen, sollten solche Daten idealerweise mit maschinenlesbaren Public Domain Markern versehen. Der Common Pile setzt viele dieser Hinweise um, hat jedoch festgestellt, dass eine solche Kennzeichnung bei nur einem Bruchteil der Werke explizit vorhanden ist und oftmals nur auf Sammlungs- oder Website-Ebene kommuniziert wird – so etwa bei der digitalen US-Regierungsbibliothek GovInfo.
Im Zuge der Entstehung dieses Datensatzes wurden auch neue Standards, Tools und Pipelines für die Extraktion und Identifikation von Lizenzen geschaffen und bereits teilweise veröffentlicht. Bestandteile dieses Ökosystems werden von der Community sicher zunehmend Eingang in weitere Projekte finden. Ein besonderes Ereignis war das Dataset Convening im Juni 2024, das Mozilla gemeinsam mit EleutherAI veranstaltete. Dort kamen Expertinnen und Experten aus Open-Source-Startups, gemeinnützigen Forschungslabors und zivilgesellschaftlichen Organisationen zusammen, um Best Practices für offene Daten in KI-Anwendungen zu diskutieren, was in einer wissenschaftlichen Abhandlung mündete. EleutherAI stellt die bisher entstandenen Werkzeuge zum Aufbau des Common Pile auf Github bereit und kooperiert mit Mozilla bei der Entwicklung von Hilfsmitteln wie Docling zur Dokumentenumwandlung und Whisper zur Audio-Transkription.
Diese Technologien eröffnen neue Möglichkeiten, um historische und kulturelle Inhalte qualitativ hochwertig aufzubereiten und in offene Datenbestände einzubringen. Ein besonders vielversprechender Bereich für weitere Entwicklungen ist die Zusammenarbeit mit kulturellen Einrichtungen wie Bibliotheken, Museen und Archiven. Bereits jetzt enthält der Common Pile hunderte tausend gemeinfreie Bücher, die von Institutionen wie der Library of Congress und dem Internet Archive digitalisiert wurden. Diese Digitalisierung beruht jedoch oftmals auf veralteter OCR-Technologie. Der Einsatz moderner, offener OCR-Modelle wie Docling oder Surya verspricht eine deutliche Steigerung der Textqualität.
Ebenso bieten moderne Transkriptionsmodelle wie Whisper Chancen, Audio- und Video-Inhalte besser zugänglich zu machen. Die Vision ist eine nachhaltige Symbiose zwischen der Open-Source-KI-Community und kulturellen Erbe-Sektoren, um den öffentlichen Zugang zu hochwertigen, offenen Daten beständig zu vergrößern. Ein weiterer kritischer Punkt bei der Diskussion um offene Datensätze ist die Befürchtung, dass Modelle, die nur mit offen lizenziertem Text trainiert wurden, schlechtere Leistungen erbringen könnten als solche mit Zugang zu nicht offen zugänglichen Daten. Um dieser Sorge entgegenzutreten, wurde mit den Comma v0.1 Modellen eine Serie von Sprachmodellen mit sieben Milliarden Parametern gebaut und auf einem Dataset mit einer Trillion beziehungsweise zwei Trillionen Tokens trainiert.
Die Ergebnisse zeigen, dass diese Modelle mit anderen führenden Sprachmodellen ähnlicher Größe und Trainingsdauer gut konkurrieren können, trotz der Einschränkung auf offenes Datenmaterial. In detaillierten Vergleichsstudien schnitten die Comma-Modelle gegenüber Modellen, die auf unterschiedlichen geöffneten oder nicht lizenzierten Datensätzen trainiert wurden, durchweg vorteilhaft ab oder lagen zumindest auf gleichem Niveau. Allerdings gibt es noch eine gewisse Lücke zum Datensatz FineWeb, dessen Ausgangsbasis deutlich größer und auf Qualität gefilterter ist. Dieses Ergebnis ist jedoch kein Hinweis auf eine grundsätzliche Überlegenheit unlizenzierter Daten, sondern eher eine Folge des größeren Volumens und der strikteren Aufbereitung bei FineWeb. Mit zunehmender Verfügbarkeit und besserer Kuratierung offener Daten dürften sich diese Unterschiede in Zukunft verringern.
Der Name Common Pile v0.1 ist bewusst als ein klares Signal für den Beginn eines ambitionierten Projekts gewählt. Statt einem fertigen Endprodukt stellt er den ersten Schritt auf dem Weg zu größeren und noch besser kuratierten offenen Datenkollektionen dar. Die Entwicklerinnen und Entwickler planen, verstärkt bislang schwer nutzbare, offen lizenzierte Quellen zu erschließen und den freien Wissensschatz kontinuierlich auszubauen. Darüber hinaus liegt ein Fokus zukünftig darauf, auch offen lizenziertes Post-Training-Material zu integrieren, damit sich die Comma-Modelle an individuelle Anwendungsfälle noch besser anpassen lassen.
Die Veröffentlichung von Common Pile v0.1 markiert somit nicht nur einen wichtigen Fortschritt bei der Bereitstellung großer, transparenter und rechtlich unbedenklicher Datensätze für die KI-Forschung, sondern kann auch als nachhaltiger Impulsgeber verstanden werden. Er fördert die offene Wissenschaft, stärkt die demokratische Zugänglichkeit zu leistungsfähigen KI-Technologien und ebnet den Weg für eine vielfältige, innovative und verantwortungsvolle KI-Zukunft. Im Spannungsfeld zwischen Datenschutz, Urheberrecht und technologischem Fortschritt bietet der Common Pile eine zukunftsfähige Antwort, die Wissenschaft und Gesellschaft gleichermaßen zugutekommt.








