Die Bedeutung von Cloud-Datenplattformen für Unternehmen wächst kontinuierlich, insbesondere im Bereich von Data Warehouses und Data Lakehouses. Dabei stellen Extract, Transform and Load (ETL)-Prozesse das Rückgrat für das Laden, Vorbereiten und Transformieren von Daten dar, die für die Analyse, Business Intelligence, Machine Learning und weitere Anwendungsfälle genutzt werden. Angesichts der enormen Investitionen, die Unternehmen täglich für Cloud-Dateninfrastrukturen tätigen, wird eine detaillierte Betrachtung der Preis-Leistungs-Verhältnisse immer entscheidender. Dabei fokussieren viele Standard-Benchmarking-Ansätze nicht ausreichend auf die realen Anforderungen heutiger ETL-Workloads, was in der Praxis zu erheblichen Kostenabweichungen führen kann. In den letzten Jahren hat sich die Landschaft cloudbasierter Datenplattformen massiv gewandelt.
Die Grenzen zwischen Data Warehouses und Data Lakehouses verschwimmen zunehmend, und neue Technologien wie offene Dateiformate und Streaming-Datenquellen prägen den Umgang mit Daten. Dies hat selbstverständlich Einfluss auf die Art und Weise, wie ETL-Benchmarks gestaltet werden müssen, um aussagekräftig zu sein. Besonders die Phase des Ladens (Load) in ETL-Pipelines wird häufig unterschätzt. Zahlreiche Benchmarking-Methoden konzentrieren sich vornehmlich auf die Extraktion und Transformation, ignorieren jedoch die tatsächlichen Belastungen und Kosten, die durch das Einfügen, Aktualisieren und Löschen von Daten entstehen. Dies ist insbesondere relevant, da moderne Data Lakehouses wie Apache Hudi, Delta Lake oder Apache Iceberg ausgefeilte Möglichkeiten für transaktionale Operationen bieten, die jedoch zusätzliche Rechenleistung erfordern.
Ein zentrales Problem beim Benchmarking heute ist die Tatsache, dass viele etablierte Standards wie TPC-DS oder TPC-DI nicht alle relevanten Aspekte der realen ETL-Arbeitslasten abbilden. Beispielsweise liefert TPC-DS zwar ein ausführliches und bewährtes Framework für Analyse- und Transformationsprozesse, vernachlässigt aber die Komplexität von inkrementellen Lade- und Updateprozessen, die in modernen Data Lakehouses gängig sind. Ebenso gehen die Belastungsmuster von Event-Daten, die maßgeblich für Streaming-Workloads sind, in den klassischeren Benchmarks oft unter. Die Verschiebung von Batch-Ladevorgängen hin zu Echtzeit- und inkrementellen Datenaktualisierungen erfordert Benchmarks, die nicht nur starre Einmal-Ladevorgänge simulieren, sondern auch die Datenmutabilität realistisch widerspiegeln. Unternehmen müssen in der Lage sein, zu bestimmen, wie oft Daten neu geschrieben oder aktualisiert werden, wie die Verteilung der Updates aussieht und wie sich Löschvorgänge im Datenbestand auswirken – alles Faktoren, die enormen Einfluss auf die Performance und letztendlich auf die Gesamtkosten haben.
Ein weiterer wesentlicher Aspekt ist die skalenmäßige Berücksichtigung von Event-Tabellen, welche mitunter die größte Datenmenge ausmachen können. Streaming-Daten und die damit verbundenen Anforderungen an niedrige Latenzzeiten lassen sich nicht effektiv durch herkömmliche OLAP-Benchmarking-Szenarien erfassen. Um Vorhersagen über Kosten und Performance treffen zu können, müssen Benchmarks daher auch diese ebenso geschäftskritischen Arbeitslasten abbilden. Moderne Benchmarks benötigen eine fein granulare Berücksichtigung von Konkurrenzen, also das gleichzeitige Bearbeiten verschiedener Prozesse, die den gleichen Datenbestand verändern oder abfragen. Beispielsweise können Hintergrundprozesse wie Compliance-gesteuerte Löschungen oder Backfill-Aufgaben starke Konkurrenz an Ressourcen erzeugen, was in Benchmarks oft nicht dargestellt wird, aber in Produktionsumgebungen maßgeblich für Engpässe und erhöhte Kosten sorgt.
Eines der ambitioniertesten Projekte zur Schließung dieser Lücken ist das Open-Source-Tool Lake Loader™, welches speziell darauf ausgelegt ist, reale Lade- und Änderungsmuster über Dimensionstabellen (DIM), Faktentabellen (FACT) und Event-Tabellen zu simulieren. Es unterscheidet sich grundlegend von bestehenden Tools, indem es verschiedene Update- und Löschmuster abbildet, Replikationen von Workloads über mehrere Runden zulässt und verschiedene Verteilungen (z. B. uniform, Zipfian) modelliert. Durch diesen Ansatz ermöglicht es Lake Loader, realitätsnahe Preis-Leistungs-Analysen auf Plattformen wie AWS EMR, Databricks und Snowflake durchzuführen.
Die Analyse realer Nutzungsdaten von Data Lakehouse-Anwendern zeigt, dass Mutabilität – also Updates und Löschvorgänge – etwa 50 Prozent der Schreiboperationen ausmacht. Die Art der Updates ist dabei für die Performance relevant: Dimensionstabellen leiden unter gleichmäßigen, zufälligen Updates, was häufig zu hohen Rewrite-Kosten führt. Faktentabellen zeigen eine Zipf-Verteilung bei den Updates, wobei aktuelle Partitionen stärker betroffen sind, während ältere partiell nachbearbeitet werden. Event-Tabellen hingegen sind größtenteils append-only, mit vereinzelt notwendigen Löschungen zur Einhaltung von Datenschutzrichtlinien. Benchmarking mit einem Fokus auf reine SQL-Ausführungen und anfängliche Ladezyklen reicht daher nicht aus, um realistische Einsichten in die Kostenstruktur von ETL-Prozessen zu geben.
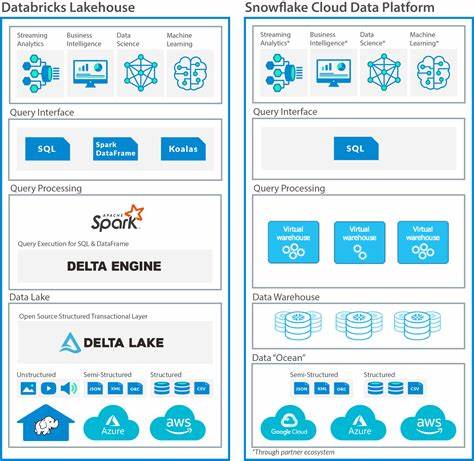
Die Arbeitslasten der heutigen Welt verlangen, dass Benchmarks alle Phasen des ETL-Prozesses mit differenzierten Musterungen abbilden, inklusive inkrementeller Extraktion, variabler Transformationskomplexität, differenzierter Ladeprozesse und paralleler Workflows. Im Vergleich der drei großen Cloud-Plattformen AWS EMR, Snowflake und Databricks zeigt sich, dass unterschiedliche Systeme ihre Stärken in verschiedenen Bereichen haben. AWS EMR punktet vor allem in flexiblen Spark-basierten Workloads und der Möglichkeit, Open-Source-Formate tief zu integrieren. Snowflake glänzt durch elegante Skalierbarkeit und einfache Handhabung mit Cloud Data Warehouses, trotz einiger Limitationen bei hochmutablen Daten. Databricks hingegen kombiniert die Vorteile von Spark mit optimiertem Photon-Execution-Engine, was insbesondere bei der Transformation Schlagkraft verleiht.
Ein umfassender Vergleich muss deshalb sowohl den ET-Anteil (Extraction und Transformation) sehr genau messen, als auch die L-Phase intensiv bewerten. Die Nutzung von Lake Loader in Kombination mit TPC-DS zur Messung der ET-Phase empfiehlt sich als pragmatischer Ansatz, der auf bewährten Standards aufbaut, aber gleichzeitig die entscheidenden L-Ladeaspekte realistisch simuliert. Die Bereitschaft der Anbieter, auch ungewöhnliche Lastmuster, inklusive hoher Update- und Löschraten in unterschiedlich verteilten Datenvolumina, abzubilden, wird immer mehr zum entscheidenden Differenzierungsmerkmal. Somit können Unternehmen ihre Cloud-Ausgaben besser kontrollieren und ETL-Pipelines so gestalten, dass sie Performance und Kosten in Einklang bringen. Neben der reinen Performance und Skalierbarkeit muss auch das Pricing-Modell der Plattformen herangezogen werden.
Pay-per-Use Modelle bei Cloud-Plattformen bieten zwar eine transparente Abrechnung, können aber bei ineffizienter Nutzung schnell hohe Kosten verursachen. Ein fein justiertes Benchmarking, das sowohl qualitative als auch quantitative Aspekte mit einbezieht, hilft, unerwartete Kostenfallen zu vermeiden. Es ist zudem davon auszugehen, dass die Weiterentwicklung von Benchmarks für ETL-Workloads sich auch in Zukunft stark an der Entwicklung von Open-Source-Werkzeugen und Community-Standards orientieren wird. Das Ziel ist eine bessere Replizierbarkeit, Vergleichbarkeit und vor allem eine praxisorientierte Relevanz, die die komplexen Realitäten von Datenmutation, Event-Streaming und gleichzeitiger Prozesskonkurrenz abbildet. Fazit: Unternehmen, die ihre ETL-Workloads auf Cloud-basierten Data Warehouses oder Lakehouses betreiben, müssen heute viel differenzierter vorgehen, wenn es darum geht, ihre Plattformen zu bewerten.
Ein enges Schließen der Lücke zwischen realen ETL-Arbeitslasten und Benchmarking-Tools ist entscheidend, um sowohl technische als auch wirtschaftliche Vorteile zu erzielen. Mit Werkzeugen wie Lake Loader und der Kombination aus traditionellen Benchmarks und realitätsnahen Lastsimulationen lassen sich fundierte Entscheidungen treffen, die langfristig zu Kosteneinsparungen und optimiertem Betrieb führen. Die Zukunft von ETL-Benchmarking wird durch genaue Modellierung realer Arbeitslasten, flexible Transformationen und detailreiche Metriken geprägt sein, um den Anforderungen moderner Data-Architekturen gerecht zu werden.








