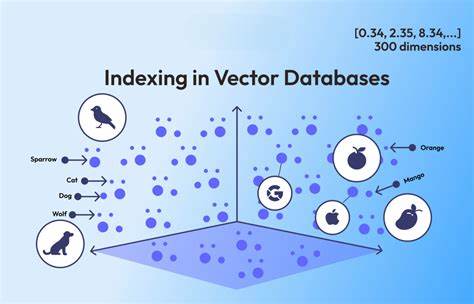
Im Zeitalter der Digitalisierung wachsen Datenmengen exponentiell und verlangen nach innovativen Wegen, diese effizient zu speichern und abzurufen. Überraschenderweise können manchmal Technologien aus völlig unterschiedlichen Bereichen zusammenwirken und zu unerwarteten Durchbrüchen führen. So geschah es, dass ich, während ich an Videokompression arbeitete, unbeabsichtigt eine Art Vektordatenbank geschaffen habe. Diese Erfahrung eröffnet spannende Perspektiven und wirft Fragen zu den Möglichkeiten moderner Datenverarbeitung auf. Videokompression ist eine Technologie, die hauptsächlich dazu dient, große Videodateien zu verkleinern, um Speicherplatz zu sparen und Übertragungszeiten zu minimieren.
Dabei werden redundante Informationen entfernt, und essenzielle Bilddaten so kodiert, dass die Qualität bestmöglich erhalten bleibt. Algorithmen wie H.264, VP9 oder AV1 analysieren Bildfolgen und speichern Veränderungen zwischen Frames anstelle jedes vollständigen Bildes. Während meiner Arbeit an einer neuen Kompressionsmethode fiel mir auf, dass die Art und Weise, wie aus den Videodaten verschiedene Merkmale extrahiert und gespeichert wurden, einer Vektorspeicherung glich. Vektordatenbanken hingegen sind Systeme, die Daten als Vektoren im mehrdimensionalen Raum organisieren.
Diese werden vor allem in der künstlichen Intelligenz und bei Suchsystemen genutzt, um Ähnlichkeiten zwischen Elementen zu erkennen, welche z.B. durch Algorithmusvergleiche in Empfehlungsdiensten verwendet werden. Durch Zufall fand ich heraus, dass die von mir generierten Kompressionsinformationen eigentlich eine Form von hochdimensionalen Vektoren darstellen, die Merkmale einzelner Videosegmente kodierten. Diese Vektoren konnten durch Abstandsberechnungen untereinander verglichen werden, was im Grunde einer Suche in einer Vektordatenbank entspricht.
Die Erkenntnis, dass Videokompressionsmethoden sich nahtlos für die Erstellung einer Vektorstruktur eignen, war ein Meilenstein. Technisch betrachtet werden bei der Videokompression oft Transformationen wie die diskrete Kosinustransformation (DCT) eingesetzt, um Bildinformationen in Frequenzkomponenten zu zerlegen. Diese Komponenten lassen sich als Zahlenreihen interpretieren, die wiederum in einem Vektorraum angeordnet werden können. Indem ich diese Daten in einer Datenbank sammelte und mit effizienten Suchalgorithmen versah, konnte ich die Inhalte anhand ihrer visuellen Ähnlichkeit abfragen. Diese Technologie hat weitreichende Anwendungen.
In der Videografie kann damit beispielsweise die Suche nach identischen oder ähnlichen Videoausschnitten enorm beschleunigt werden. Auch im Bereich der Überwachung oder im Marketing eröffnet sich die Möglichkeit, Inhalte automatisiert zu analysieren und zu klassifizieren. Neben der verbesserten Kompression bietet diese Kombination die Chance, Daten semantisch zu verarbeiten und dadurch neue Einsichten zu gewinnen. Allerdings birgt die Verschmelzung von Videokompression und Vektordatenbanken auch Herausforderungen. Die Datenmengen, die bei hochauflösenden Videos entstehen, sind riesig, sodass effiziente Indizierung und Suche technische Hürden setzen.
Die Balance zwischen Kompressionsrate und Suchgenauigkeit muss sorgsam austariert werden. Zudem sind Datenschutz und ethische Fragen im Umgang mit solchen Technologien von großer Bedeutung. Der nächste Schritt meiner Arbeit besteht darin, die Methode weiter zu verfeinern und auf weitere visuelle und audiovisuelle Datentypen anzuwenden. Dank moderner Machine-Learning-Modelle können die Vektorrepräsentationen noch aussagekräftiger gestaltet werden, was die Suche und Analyse weiter verbessert. Die Idee ist, Videokompression nicht nur als Mittel zur Datenreduktion zu sehen, sondern als integralen Bestandteil eines komplexen Datenmanagementsystems.



![New brain-spine interface tech in Shanghai helps paralyzed patients walk again [video]](/images/0A7F8529-2F17-403D-9C97-04BEBBA0E25B)

