Künstliche Intelligenz und insbesondere große Sprachmodelle haben in den letzten Jahren enorme Fortschritte gemacht. Doch trotz zahlreicher Versprechen zu Geschwindigkeit, Effizienz und Intelligenz eines jeden neuen Modells stoßen Unternehmen rasch auf die Grenzen klassischer Benchmark-Tests. Benchmark-Scores mögen zwar eine erste Einschätzung geben, doch sie bilden längst nicht das vollständige Bild ab, wenn es darum geht, wie gut eine KI-Lösung in der realen Produktionsumgebung funktioniert. Wer sich ausschließlich auf Benchmarks verlässt, bleibt häufig hinter den tatsächlichen Anforderungen zurück und riskiert unerwartete Auswirkungen auf Kosten, Nutzererlebnis und technische Performance. Die wachsende Komplexität und Dynamik von KI-Anwendungen macht A/B-Tests zu einem unverzichtbaren Werkzeug bei der Evaluierung, Optimierung und Anpassung von Modellen im produktiven Einsatz.
Traditionelle Benchmarks verfügen über begrenzte Aussagekraft, weil sie festgelegte Aufgaben in künstlichen oder standardisierten Umgebungen testen, die von den realen Anwendungsszenarien oft stark abweichen. Ein Modell, das in einem Benchmark exzellent abschneidet, kann in einer bestimmten Unternehmenslösung dennoch unpassende, irrelevante oder fehlerhafte Ergebnisse liefern. Zudem sind Aspekte wie Latenz, Kosten pro Anfrage oder Ressourcenverbrauch oftmals nicht Teil der Bewertung, obwohl sie in produktiven Systemen eine große Rolle spielen. Zudem besagt das Goodhart'sche Gesetz, dass Metriken als Zielgrößen nicht mehr valide sind, sobald sie optimiert werden. Anbieter stimmen Modelle daher so ab, dass sie bei Benchmarks gut abschneiden – mitunter auf Kosten der realen Performance.
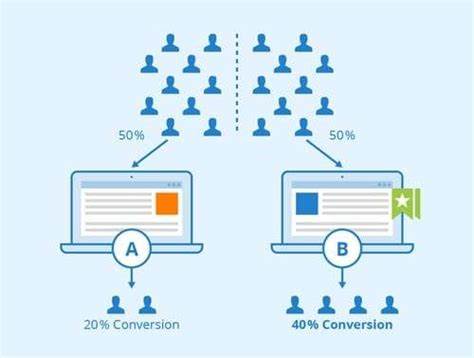
Dies zeigt sich etwa darin, dass ein KI-basierter Textgenerator zwar Zusammenfassungen sehr gut erstellen kann, aber bei komplexeren Eingaben langsam reagiert oder Nutzererwartungen nicht erfüllt. A/B-Testing ermöglicht hier einen entscheidenden Paradigmenwechsel. Statt sich auf theoretische Leistungswerte zu verlassen, werden verschiedene Modellvarianten oder Konfigurationen live und unter realen Bedingungen gegeneinander getestet. Dabei werden unterschiedliche Nutzergruppen jeweils mit unterschiedlichen Versionen bedient, um messbare Auswirkungen auf wirklich relevante Metriken zu ermitteln. Dieses Vorgehen erlaubt den direkten Vergleich von Genauigkeit, Latenz, Kosten, Nutzerzufriedenheit und anderen KPIs und erzeugt so eine solide Entscheidungsgrundlage für den produktiven Einsatz.
Zudem können unterperformante Varianten flexibel zurückgezogen oder angepasst werden, was Risiken minimiert und Innovationen beschleunigt. Die technische Umsetzung von parallelen Modellbereitstellungen ist heute dank spezieller Tools und Plattformen deutlich einfacher geworden. Moderne Feature-Flagging- und Experimentierplattformen ermöglichen eine gezielte und kontrollierte Verteilung der Nutzeranfragen auf verschiedene KI-Instanzen und liefern gleichzeitig umfangreiche Daten für die Auswertung. Lösungen wie GrowthBook, LangChain und Dagger bieten nicht nur eine einfache Integration, sondern auch Features wie Echtzeit-Tracking, Rollbacks und A/B-Test-Analysen. Die Möglichkeit einer inkrementellen Einführung durch langsames Hochskalieren des Traffic-Anteils ermöglicht zudem eine behutsame Validierung neuer Modellversionen.
Bei manchen Szenarien ist der Wechsel zwischen verschiedenen Modellen nicht immer praktikabel oder gewünscht. In solchen Fällen stellt das gezielte Optimieren von Prompts eine wertvolle Alternative dar. Mit variierenden Formulierungen, Strukturierungen oder Anweisungen kann die Qualität und Relevanz der generierten Antworten effektiv verbessert werden. Ähnlich wie bei Modellen lassen sich unterschiedliche Prompt-Varianten im A/B-Test live gegeneinander prüfen, um das optimale Ergebnis zu identifizieren. Die Fähigkeit, Modell-Inputs agil an die Anforderungen anzupassen, schafft zusätzlich Spielraum für kontinuierliche Verbesserungen.
Zur Durchführung erfolgreicher A/B-Tests bei KI-Modellen ist es entscheidend, methodisch strukturiert vorzugehen. Die Nutzergruppen sollten zufällig zugewiesen werden, um Verzerrungen auszuschließen, und es empfiehlt sich, pro Testlauf nur eine Variable zu ändern – sei es ein Modell, ein Parameterwert oder eine Prompt-Version. Weiterhin ist eine schrittweise Erhöhung des Test-Volumens sinnvoll, um mögliche negative Effekte frühzeitig zu erkennen und bei Bedarf gegenzusteuern. Solche Maßnahmen gewährleisten valide und reproduzierbare Testergebnisse. Zudem ist es wichtig, aussagekräftige und umfassende Metriken zu erfassen, die verschiedene Dimensionen abdecken: technische Performance (wie Antwortzeit und Durchsatz), Nutzerinteraktion (beispielsweise Gesprächslänge oder Wiederholungsanfragen), Antwortqualität (beurteilbar durch menschliche Bewertungen) sowie Kostenaspekte (etwa Tokenverbrauch oder Rechenressourcen).
Über reine technische Kennzahlen hinaus sollten auch die geschäftlichen Zielgrößen im Fokus stehen. Metriken wie Nutzerbindung, Konversionsraten oder Umsatzsteigerungen geben wertvolle Hinweise, ob ein KI-System wirklich zur Wertschöpfung beiträgt. Die Kombination aus klassischen KPIs und AI-spezifischen Messgrößen erlaubt eine ganzheitliche Bewertung, die spätere Fehlinvestitionen minimiert. Eine statistisch fundierte Auswertung stellt sicher, dass beobachtete Verbesserungen nicht zufällig, sondern tatsächlich signifikant sind. Außerdem gilt es, die praktische Relevanz der Ergebnisse einzuschätzen und Kosten-Nutzen-Aspekte zu berücksichtigen, bevor Entscheidungen getroffen werden.
Praxisbeispiele verdeutlichen den Nutzen solcher A/B-Tests eindringlich. Ein Chatbot-Entwicklungsteam konnte durch einen Vergleich zwischen einem herkömmlichen und einem auf Belohnungsmodellen basierenden Ansatz die durchschnittliche Gesprächsdauer um 70 % erhöhen und zugleich die Nutzerbindungsrate um 30 % steigern. In einem anderen Fall verhalf ein lokaler Nachbarschaftsdienst mit KI-generierten E-Mail-Betreffzeilen, basierend auf iterativ verfeinerten Belohnungsfunktionen, zu einem spürbaren Anstieg der Klickraten und der aktiven Nutzerzahl. Beide Fälle zeigen, dass sich Investitionen in derart strukturierte Evaluierung und stetige Optimierung langfristig auszahlen. Das zentrale Fazit lautet daher: Benchmark-Werte alleine reichen keineswegs aus, um den langfristigen Erfolg von KI-Modellen in produktiven Umgebungen sicherzustellen.
Realistisch gestaltete A/B-Test-Programme bilden die Grundlage, um sowohl Qualität als auch Wirtschaftlichkeit laufend zu überprüfen und zu maximieren. Selbst kleine Anpassungen an Modellen, Parametern oder Prompts können große Veränderungen in der Nutzererfahrung und den Betriebskosten bewirken. Die Nutzung von Feature-Flags beim Rollout gewährleistet dabei Sicherheit und Flexibilität. Angesichts der rasanten Innovationszyklen in der KI-Welt ist es zudem essenziell, die Teststrategien kontinuierlich weiterzuentwickeln und an neue Erkenntnisse anzupassen. Für Unternehmen, die die Effektivität ihrer KI-Anwendungen steigern möchten, ist jetzt der optimale Zeitpunkt, A/B-Testing als festen Bestandteil des Entwicklungs- und Betriebsprozesses zu etablieren.
Mit einer datenbasierten, iterativen Herangehensweise lassen sich Fehlinvestitionen vermeiden, Nutzerzufriedenheit erhöhen und Wettbewerbsvorteile ausbauen. So verwandelt sich KI von einer spannenden Technologie in einem stabilen, wertvollen Geschäftstreiber. Die Zukunft der Künstlichen Intelligenz liegt nicht mehr nur in der Theorie, sond ern in der messbaren, praxisnahen Performance im täglichen Einsatz.