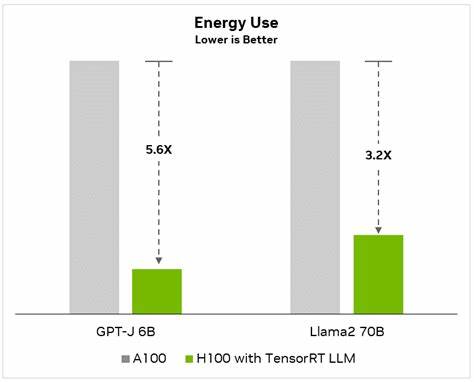
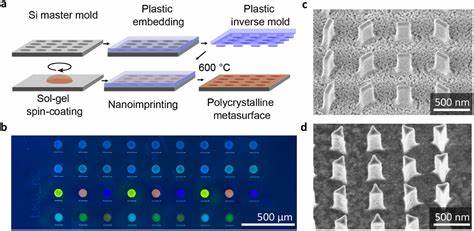
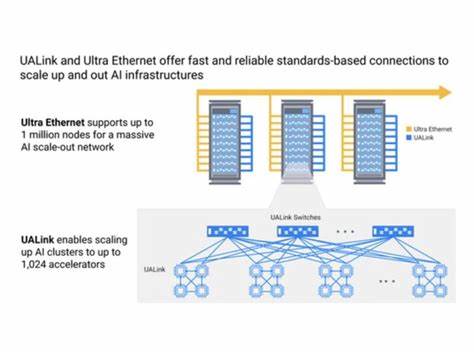
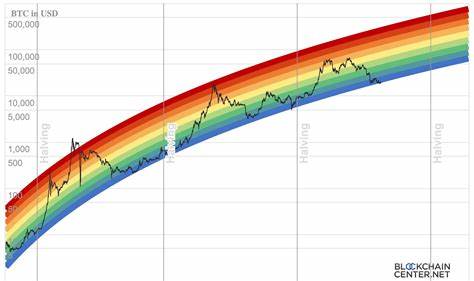
Die Entwicklung großer Sprachmodelle (Large Language Models, LLMs) hat in den letzten Jahren die Fähigkeit der künstlichen Intelligenz revolutioniert, natürliche Sprache zu verstehen und zu generieren. Trotz ihrer Leistungsfähigkeit bleiben viele Modelle jedoch statisch; sie können ihre internen Gewichte nicht autonom an neue Informationen oder spezifische Aufgaben anpassen. Hier setzt das Konzept der selbstanpassenden Sprachmodelle an, ein innovativer Ansatz, der es Sprachmodellen ermöglicht, durch eigene Lernprozesse ihre Fähigkeiten fortlaufend zu verbessern und zu erweitern. Selbstanpassende Sprachmodelle, wie das von Forschern am MIT entwickelte Framework SEAL, stellen eine neue Ära in der KI-Entwicklung dar. SEAL steht für „Self-Adapting Language Models“ und ermöglicht es dem Modell, eigenständig Daten für ein Feintuning zu generieren sowie Anweisungen zur Optimierung seiner Gewichte zu formulieren.
Das Besondere an SEAL ist, dass es nicht auf zusätzliche Module oder externe Hilfen angewiesen ist, sondern die Anpassung direkt durch die Generierung eigener „Self-Edits“ steuert. Diese Self-Edits enthalten Vorschläge wie die Umstrukturierung von Informationen, Definition von Trainingshyperparametern oder die Nutzung ergänzender Datenaugmentationen. Das zugrundeliegende Training von SEAL nutzt eine Kombination aus überwachten Feintuning-Methoden und einem neuartigen Verstärkungslernverfahren, um die Effektivität der generierten Self-Edits zu maximieren. In einer iterativen Schleife erzeugt das Modell unterschiedlichste Anpassungsvorschläge, wendet diese an, bewertet die anschließende Leistung bei einer Zielaufgabe und lernt aus den erfolgreichsten Anpassungen. Diese Methode trägt dazu bei, Gewichte dauerhaft so zu modifizieren, dass die Leistung stetig verbessert wird.
Die praktische Anwendung von SEAL zeigt sich besonders in zwei Bereichen: der Wissensintegration und dem Few-Shot-Lernen. Beim Wissensintegrations-Task erhält das Modell eine Passage mit Fakten, die es verinnerlichen soll. Ziel ist es, anschließend Fragen zu diesem neu hinzugefügten Wissen beantworten zu können, ohne auf den ursprünglichen Kontext zurückgreifen zu müssen. SEAL generiert hierfür intelligente, logisch abgeleitete Daten als Grundlage für das Feintuning. In Experimenten verbesserte sich die Genauigkeit der Fragebeantwortung durch SEAL nach mehreren Anpassungsrunden signifikant und übertraf dabei sogar Methoden, die auf rohen Passagen oder extern erzeugten synthetischen Daten basieren.
Im Bereich des Few-Shot-Lernens zeigt SEAL seine Fähigkeit, aus wenigen Beispielen eigenständig Trainingsdaten zu augmentieren und geeignete Hyperparameter für die Feinabstimmung auszuwählen. Auf einer vereinfachten Version des ARC-Benchmarks erreichte das Modell so eine beeindruckende Erfolgsquote, die herkömmliche In-Context-Learning-Methoden deutlich übertraf. Diese Leistung demonstriert, wie selbstgesteuerte Datenvorbereitung und adaptives Training das Modell befähigen, abstrakte Aufgaben mit wenig Vorwissen effizient zu bewältigen. Trotz der vielversprechenden Fortschritte bringt SEAL auch Herausforderungen mit sich. Eine wesentliche Limitierung ist das Risiko des katastrophalen Vergessens: Wiederholte selbstgesteuerte Anpassungen können frühere Lerninhalte überschreiben und somit das Wissen aus vorangegangenen Aufgaben mindern.
Die Suche nach Mechanismen wie Replay-Techniken, eingeschränkten Updates oder komplexeren Repräsentationsstrategien ist notwendig, um dieses Problem zu adressieren und eine nachhaltige Speicherung von Wissen zu gewährleisten. Die Zukunft selbstanpassender Sprachmodelle verspricht noch weitreichendere Entwicklungsmöglichkeiten. Zukünftige Systeme könnten nicht nur in der Lage sein, Gewichte zu verändern, sondern eigenständig zu entscheiden, wann und wie eine Anpassung sinnvoll ist – möglicherweise sogar während der laufenden Interaktion mit Nutzern. Dies würde es erlauben, temporäre Überlegungen und komplexe Gedankengänge direkt in dauerhafte Modellkapazitäten umzuwandeln. Ein solcher Fortschritt wäre ein großer Schritt hin zu wirklich agentenhaften KI-Systemen, die kontinuierlich lernen, reflektieren und sich verbessern.
Mit SEAL und ähnlichen Ansätzen nähert sich die KI-Welt dem Ziel immer intelligenterer und anpassungsfähigerer Sprachmodelle, die sich nicht nur auf vorab gelernte Daten verlassen, sondern agil auf neue Aufgaben, Informationen und Herausforderungen reagieren können. Dieser Paradigmenwechsel eröffnet spannende Möglichkeiten für Forschung, Anwendungen und die Art und Weise, wie wir in Zukunft mit KI-Systemen interagieren. Die Arbeit der Forscher vom MIT setzt dabei neue Maßstäbe und liefert einen wertvollen Beitrag zur Entwicklung von KI, die sich fortlaufend selbst verbessert – ein Meilenstein auf dem Weg zu wirklich intelligenten, selbstlernenden Maschinen.