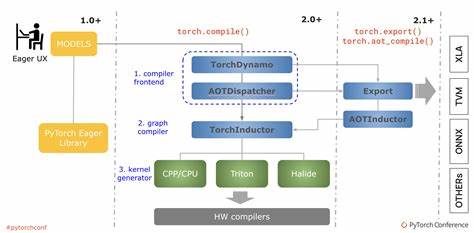
In der modernen Deep Learning-Entwicklung spielt PyTorch eine zentrale Rolle, insbesondere durch seine innovative torch.compile-Funktion, die darauf abzielt, die Performance von Modellen durch eine optimierte Kompilierung zu steigern. Ein wesentlicher Bestandteil dieses Prozesses sind die sogenannten "Guards". Diese spielen eine Schlüsselrolle darin, wie torch.compile die Ausführung sicherstellt, während gleichzeitig Flexibilität und Effizienz bewahrt werden.
Doch wie funktionieren diese Guards genau? Welche Kosten verursachen sie im Betrieb und welche Maßnahmen können Entwickler ergreifen, um sie zu optimieren? In diesem Beitrag wird ein umfassender Einblick in die Mechanismen der torch.compile Guards gegeben, ihre Auswirkungen auf die Performance erläutert und praktische Empfehlung für ihre optimale Nutzung geliefert. Zunächst ist es hilfreich, zu verstehen, was Guards überhaupt sind und warum sie in der Welt der Just-in-Time-Compiler (JIT) wie torch.compile gebraucht werden. Grundsätzlich dienen Guards als Sicherheitsprüfungen, die zur Laufzeit dafür sorgen, dass die Annahmen, auf denen die kompilierte Version eines Modells aufbaut, weiterhin gültig sind.
Da sich in dynamischen Frameworks wie PyTorch Modellparameter, Eingabegrößen oder andere Umgebungsbedingungen zwischen den Aufrufen ändern können, verhindern diese Guards inkorrekte oder sogar fehlerhafte Ausführungen. Ohne Guards wäre es riskant, ein Modell kompilieren zu lassen, da sich während der Laufzeit geänderte Bedingungen zu erheblichen Abweichungen in der Funktionsweise führen könnten. Beispielsweise kann eine Änderung der Eingabegröße oder eine Modifikation der Tensor-Typen zu Inkonsistenzen führen, wenn das Kompilat auf vordefinierten Annahmen beruht. Die Guards überwachen daher diese Bedingungen und aktivieren bei Bedarf eine Neudurchführung der Kompilierung oder einen Fallback auf den ursprünglichen interpretativen Modus. Im Kern sind Guards Bedingungsprüfungen, die vor der tatsächlichen Ausführung des kompilierten Modells stattfinden.
Sie überprüfen Parameter wie Eingabeformen (Shapes), Datentypen, bestimmte Konstanten im Modellgraphen oder den Zustand von Modulen und Operatoren. Wenn eine dieser Bedingungen nicht erfüllt wird, gilt der Guard als "gebrochen" und löst eine Neugenerierung der Ausführungseinheit aus. Dies stellt die Korrektheit und Stabilität während der Laufzeit sicher. Doch welche Kosten sind mit diesem Mechanismus verbunden? Guards erhöhen natürlich die Sicherheit, bringen jedoch auch Performance-Overhead in Form von zusätzlichen Laufzeitprüfungen mit sich. Jeder Guard wird im Vorfeld einer Operation ausgeführt, wodurch sich die Latenz leicht erhöht.
Zudem können Guard-Fehlausführungen ressourcenintensiv sein, da sie die wiederholte Kompilierung oder alternative Ausführungswege forcieren. Die Kosten sind dabei nicht nur auf Rechenzeit beschränkt. Memory-Overhead kann ebenfalls entstehen, da zur Laufzeit Zustände und Informationen zur Absicherung gespeichert und verglichen werden müssen. Besonders bei komplexen Modellen mit vielen dynamischen Aspekten und wechselnden Eingabegrößen vervielfachen sich die erforderlichen Guards, was das System belastet und die Vorteile der Kompilierung teilweise schmälert. Daher ist es entscheidend, die Verwendung von Guards nicht nur zu verstehen, sondern aktiv zu optimieren.
Ein wichtiger Ansatzpunkt ist die Statik im Modell zu erhöhen, das heißt, möglichst viele Eingabeparameter und Module auf konstante, vorhersehbare Werte zu reduzieren. Dies führt zu weniger und einfacheren Guards und senkt deren Kosten. Darüber hinaus lässt sich mit gezielter Modellgestaltung und Codeoptimierungen der Bedarf an Guards einschränken. Beispielsweise können Eingabedaten vorab standardisiert werden, um unterschiedliche Formen zu vermeiden oder Typkonversionen bereits im Vorfeld des Kompilats stattfinden zu lassen. Auf diese Weise verringert sich die Wahrscheinlichkeit von Guard-Fehlausführungen.
Ein weiterer Weg besteht darin, Guards explizit zu beeinflussen, indem Entwickler das torch.compile-Interface effizient einsetzen. PyTorch erlaubt etwa das Setzen von Strategien oder Optionen, um die Sensitivität der Guards gegenüber bestimmten Parametern anzupassen. Durch das Deaktivieren weniger relevanter Guards können Performancegewinne erzielt werden, wenn dabei die korrekte Funktion gewährleistet bleibt. Es lohnt sich auch, Profiling-Werkzeuge zu verwenden, um das Verhalten der Guards im Einsatz zu analysieren.
Durch gezieltes Monitoring lässt sich identifizieren, welche Guards besonders oft ausgelöst werden oder hohe Kosten verursachen. Basierend auf diesen Erkenntnissen können gezielte Anpassungen am Modell oder der Pipeline erfolgen. Schließlich ist der fachliche Austausch in der Entwickler-Community sowie das Studium neuer Veröffentlichungen zur torch.compile und den Guards hilfreich. Da die Technologie kontinuierlich weiterentwickelt wird, öffnen sich neue Möglichkeiten für Optimierungen, die über reine Code-Verbesserungen hinausgehen.
Zusammenfassend lässt sich sagen, dass die Guards eine unverzichtbare Komponente für die Sicherheit und Flexibilität von torch.compile darstellen. Sie ermöglichen es, dynamische Modelle effizient zu kompilieren, ohne die Korrektheit zu gefährden. Gleichzeitig stellen sie einen Overhead in der Laufzeit dar, der bei besonders dynamischen oder komplexen Modellen spürbar wird. Durch ein tiefgreifendes Verständnis der Guard-Mechanismen und der bewussten Gestaltung und Optimierung von Modellen sowie Eingabedaten kann dieser Overhead reduziert werden.
Entwickler profitieren so von einer besseren Performance und gleichzeitig gesicherter Stabilität. Die kontinuierliche Auseinandersetzung mit neuen Features und Analysewerkzeugen rund um torch.compile ist hierbei essenziell. Die Zukunft verspricht weitere Verbesserungen bei der Implementierung und Nutzung von Guards. Insbesondere durch intelligente Heuristiken oder Machine-Learning-basierte Steuerungsmechanismen könnten Guards in Zukunft noch effizienter gestaltet werden, was die Leistungsfähigkeit von PyTorch weiter steigert und den Weg für eine breitere Anwendung von Kompilierter KI-Modelle ebnet.
Bis dahin bleibt es eine spannende Herausforderung für Entwickler, die Potentiale der torch.compile Guards voll auszuschöpfen und maßgeschneiderte Lösungen für ihre individuellen Modelle zu entwickeln.






![What Gallium does to an Aluminium bat [video]](/images/D9920C95-9875-4723-A2A6-1DB25CE8F8BA)