Die Welt der wissenschaftlichen Forschung verändert sich rasant, nicht zuletzt aufgrund der rasanten Fortschritte im Bereich der künstlichen Intelligenz. Forschungsarbeiten werden immer zahlreicher und komplexer, wodurch Forscher und Studenten vor der Herausforderung stehen, relevante Informationen in kurzer Zeit zu erfassen und zu verarbeiten. Hier setzt der Einsatz eines KI-gesteuerten, eventbasierten Agenten an, der speziell als Forschungsassistent von Grund auf entwickelt wurde. Solch ein System unterstützt bei der Verarbeitung von Forschungsarbeiten, Extraktion von Wissen, der Visualisierung von Zusammenhängen und noch vielem mehr. Die Kombination von smarter Technologie mit einer modular aufgebauten Event-Driven-Architektur ermöglicht einen völlig neuen Ansatz in der wissenschaftlichen Arbeit und Wissensführerschaft.
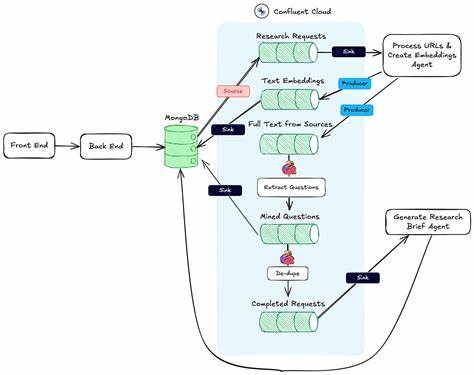
Der Kern eines solchen Forschungsassistenten basiert auf einer Event-Driven-Architektur, die es erlaubt, einzelne Arbeitsschritte als voneinander unabhängige Bausteine zu konzipieren. Diese Komponenten kommunizieren über definierte Ereignisse miteinander, was eine hohe Flexibilität, Skalierbarkeit und Wartbarkeit gewährleistet. Jede wichtige Aktion im Workflow, zum Beispiel das Hochladen eines wissenschaftlichen Papers, löst ein Event aus, das andere Module anstößt und so eine automatisierte, effiziente Verarbeitungskette entsteht. Basierend auf dieser Architektur arbeitet der Agent nicht linear, sondern reagiert dynamisch und umfassend auf die verschiedensten Inputs und Bearbeitungsschritte. Die Verarbeitung der wissenschaftlichen Literatur erfolgt durch Integration leistungsfähiger KI-Modelle, wie dem Google Gemini 2.
5 Pro. Diese Modelle sind in der Lage, Texte aus komplexen Forschungspapieren zu verstehen, zu strukturieren und intelligent auszuwerten. Zum Einsatz kommen dabei fortschrittliche NLP-Techniken (Natural Language Processing), die eine automatisierte Extraktion essentieller Informationen gewährleisten. Dabei werden nicht nur einfache Zusammenfassungen generiert, sondern tiefergehende Inhalte wie zentrale Konzepte, Fachterminologie und bedeutende Forschungsergebnisse identifiziert und beschrieben. Ein weiterer bedeutender Vorteil der KI-gesteuerten Lösung ist die Fähigkeit, die Forschung in einen ganzheitlichen Kontext einzuordnen.
Durch systematische Analyse verwandter Arbeiten und Einbettung der aktuellen Forschungsergebnisse in den bestehenden wissenschaftlichen Diskurs werden Bedeutung und Innovation transparent gemacht. Das System erkennt Zusammenhänge zwischen unterschiedlichen Publikationen und schafft damit ein umfassendes Forschungsnetzwerk. Die daraus entstehende Wissensgraphstruktur stellt die Verknüpfungen von Konzepten, Methoden und Ergebnissen anschaulich dar und bietet Forschern eine interaktive Möglichkeit, neue Perspektiven zu gewinnen. Die semantische Analyse durch den Agenten eröffnet zudem Einblicke in bisher unerforschte Felder. Indem der Assistent mögliche Forschungslücken ermittelt, unterstützt er Forscher dabei, gezielt neue Fragestellungen und innovative Projekte zu initiieren.
Diese Identifikation von ungenutztem Potenzial ist für die wissenschaftliche Innovation von entscheidender Bedeutung und stellt einen klaren Vorteil gegenüber herkömmlichen Recherchemethoden dar. Effizienzsteigerungen sind durch automatisierte Erstellung von Berichten und Codebeispielen möglich. Der Forschungsassistent generiert nicht nur übersichtliche, strukturierte Zusammenfassungen im Markdown-Format für eine bessere Lesbarkeit, sondern erstellt zudem praktische Code-Implementierungen, die auf den analysierten Forschungsergebnissen basieren. So werden theoretische Erkenntnisse unmittelbar anwendungsnah aufbereitet, was vor allem für Studierende und angewandte Wissenschaft von großem Nutzen ist. Die Integration von Internetrecherchen ermöglicht gezielte Empfehlungen weiterführender Literatur.
Das System verknüpft die internen Erkenntnisse mit extern verfügbaren Ressourcen und schlägt relevante, aktuelle Forschungsarbeiten vor. Dadurch bleibt der Nutzer stets auf dem neuesten Stand der Forschung und kann seine wissenschaftlichen Erkenntnisse kontinuierlich erweitern. Diese Funktion sorgt für eine dynamische Ergänzung des eigenen Wissensbestands und erhöht die Wettbewerbsfähigkeit der Arbeit. Technisch gesehen bietet das eventgesteuerte Modell zahlreiche Vorteile gegenüber klassischen monolithischen Anwendungen. Die einzelnen Schritte wie Text-Extraktion, Analyse, Wissensgraph-Erstellung und Berichtsgenerierung sind klar gegliedert und modular.
Das erleichtert nicht nur die Wartung und Erweiterung der Anwendung, sondern erlaubt auch die parallele Verarbeitung und schnellere Reaktionszeiten. Zudem sind „No-Operation“-Module in der Pipeline eingebunden, die als Kontrollpunkte fungieren können und die Integration von menschlicher Überprüfung oder Monitoring ohne Einfluss auf den eigentlichen Workflow ermöglichen. Die Speicherung der resultierenden Daten erfolgt in einem persistenten Format, aktuell als JSON-Datei, welche den Wissensgraphen und die abgeleiteten Informationen ablegt. Dies gewährleistet die dauerhafte Verfügbarkeit der Inhalte über API-Endpunkte und unterstützt die Wiederverwendbarkeit und Austauschbarkeit innerhalb verschiedenster Systeme. Zukünftige Entwicklungen planen hier auch die Integration spezialisierter Datenbanken wie Neo4j oder MongoDB, um die Skalierbarkeit bei wachsendem Datenvolumen und komplexeren Abfragen sicherzustellen.
Die Anwenderfreundlichkeit der Lösung wurde durch die Bereitstellung einer intuitiven Weboberfläche deutlich erhöht. Über ein einfaches Frontend können Forschungspapiere hochgeladen, die Fortschritte des Analyseprozesses verfolgt und die generierten Ergebnisse inklusive des Wissensgraphen sowie detaillierter Berichte eingesehen werden. Damit spricht das System gleichermaßen Forschende, Studierende und wissenschaftliche Institutionen an und erleichtert den Zugang zu komplexen KI-gestützten Analyseverfahren. Die Entwicklung solcher KI-gestützter Forschungsassistenten eröffnet nicht nur innovative Anwendungsmöglichkeiten in der Literaturrecherche, sondern führt auch zu einem Paradigmenwechsel in der wissenschaftlichen Prozessgestaltung. Automatisierte Verarbeitung, intelligente Kontextualisierung und direkte Nutzbarmachung der gewonnenen Erkenntnisse verbessern die Qualität, Geschwindigkeit und Tiefe der Forschung erheblich.
Forscher werden entlastet, wenn sie schnell die wichtigsten Informationen erhalten und sich auf die kreative und methodische Weiterentwicklung ihrer Disziplin konzentrieren können. Darüber hinaus ermöglichen solche Systeme eine bessere Vernetzung und Kollaboration in der Wissenschaftscommunity. Durch den interaktiven Wissensgraphen entsteht eine transparente Übersicht über das Forschungsfeld, die bislang isolierte Ergebnisse verknüpft und so neue Ideen und gemeinsame Projekte fördert. Dies wirkt sich langfristig positiv auf den Fortschritt in verschiedenen Fachgebieten aus und bringt einen Mehrwert für die gesamte Gesellschaft. Zukünftige Erweiterungen setzen auf noch tiefere Integration von PDF-Verarbeitungstechnologien, um wissenschaftliche Dokumente auch vollständig automatisiert zu durchsuchen und auszuwerten.
Echtzeit-Updates über Websocket-Protokolle in der Benutzeroberfläche könnten sofortige Reaktionen auf neue Daten ermöglichen. Zudem sind Authentifizierungsmechanismen geplant, um personalisierte Zugriffe und Rechteverwaltung zu unterstützen, was vor allem für Institutionen wichtig ist. Multimodale Analysen, die neben Texten auch Bilder, Tabellen und Formeln einbeziehen, sowie mehrsprachige Unterstützung erweitern den praktischen Einsatz in der global vernetzten Forschung. Neben den technischen Innovationen wird auch die beobachtbare KI-Generierung von generiertem Code-Output und die direkte Beantwortung wissenschaftlicher Fragestellungen immer wichtiger. Die automatisierte Erstellung von Implementierungsbeispielen bietet Anwendern die Möglichkeit, Theorie und Praxis schnell zu verbinden.