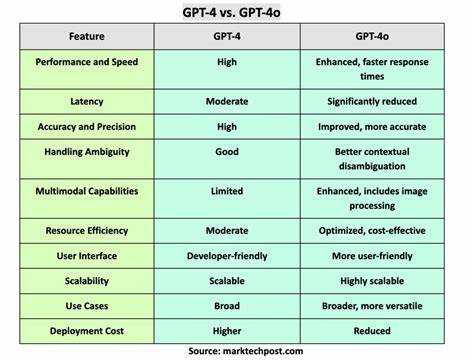
Künstliche Intelligenz hat in den letzten Jahren bemerkenswerte Fortschritte gemacht, besonders im Bereich der natürlichen Sprachverarbeitung und der automatischen Code-Generierung. OpenAI hat mit Modellen wie GPT-4 zahlreiche Möglichkeiten eröffnet, Entwicklern beim Programmieren und technischen Schreiben zu unterstützen. Jedoch zeigen sich bei neueren Versionen wie GPT-4o gewisse Einschränkungen, speziell wenn es darum geht, extrem präzise oder strikte Programmier-Prompts zu verarbeiten. Im Vergleich dazu bietet GPT-4-turbo eine robustere Performance und eine zuverlässigere Einhaltung von Code-Strukturen unter anspruchsvollen Bedingungen. Die Analyse dieses Verhaltens ist entscheidend für Entwickler, die auf eine konsistente und genaue Reaktion bei der Code-Generierung angewiesen sind.
GPT-4o ist ein neueres Modell, das in bestimmten Bereichen eine interessante Weiterentwicklung darstellt. Trotzdem offenbaren sich bei komplexen und strikt formulierten Eingaben Probleme, die sich besonders bei der Formatierung und Einhaltung von Code-Konventionen zeigen. Hierbei bricht das Modell häufig die gewohnte Struktur, erzeugt inkonsistente Einrückungen oder verändert wichtige syntaktische Elemente, wodurch der resultierende Code weniger zuverlässig und schwer wartbar wird. Im Gegensatz dazu gelingt es GPT-4-turbo, die Struktur der Eingabe besser zu bewahren und präziser auf die Anforderungen des Entwicklers einzugehen. Der Hauptgrund für die Schwierigkeiten von GPT-4o liegt in den internen Trainingsdaten und im Algorithmusdesign.
Offenbar hat die Architektur von GPT-4o eine höhere Toleranz für Variationen in der Befehlsausführung, was in kreativeren Szenarien von Vorteil sein kann, jedoch bei strikten Codeaufgaben zu ungewollten Abweichungen führt. Diese Flexibilität wirkt sich negativ auf die Reproduzierbarkeit von Ergebnisn aus, was für professionelle Softwareentwickler problematisch ist. Sie benötigen vor allem Konsistenz, vorhersagbares Verhalten und Einhaltung der genauen Vorgaben, damit sie Code direkt einsetzen oder weiterverarbeiten können. Ein weiterer signifikanter Aspekt ist das sogenannte Prompt-Engineering. Während GPT-4-turbo eine klare und deterministische Antwort auf spezifisch formulierte Anforderungen gibt, zeigt GPT-4o eine Tendenz, Prompts freier zu interpretieren.
Das führt häufig zu einer Diversifizierung des Outputs, was zwar manchmal innovativ sein kann, aber in der professionellen Softwareentwicklung oft zu Fehlern und zusätzlichen Nacharbeiten führt. Diese Unterschiede machen sich besonders bemerkbar, wenn komplexere Codeabschnitte verlangt werden oder die Programmiersprache besonders anspruchsvoll in ihrer Syntax ist. Die Entwickler-Community hat die Probleme von GPT-4o bereits eingehend dokumentiert. Der GitHub Repository „gpt4o-regression-report“ von Ryan (@chapman4444) liefert umfangreiche Informationen über Regressionen und Rückschritte im Verhalten von GPT-4o gegenüber GPT-4-turbo. Dieses Projekt hilft dabei, Fehlerquellen zu identifizieren und gibt wertvolle Einblicke in mangelnde Prompt-Obedience, Formatierungsprobleme und logische Inkonsistenzen.
Die systematische Untersuchung und das Sammeln von Erfahrungsberichten ermöglichen es Anwendern und OpenAI selbst, Schwachstellen zu erkennen und an Korrekturen zu arbeiten. Aus Sicht der SEO und technikaffinen Nutzer ist es wichtig zu verstehen, warum sich manche KI-Modelle trotz äußerer Versionsfortschritte in gewissen Situationen verschlechtern können. Die Erwartungshaltung an ein neues Modell ist meist, dass es „besser“ oder zumindest „gleich gut“ ist wie seine Vorgänger. Doch in der Praxis führen Anpassungen im Training, Optimierungen für spezifische Anwendungsfälle oder Veränderungen im Datenmix auch zu regressiven Effekten. GPT-4o zeigt exemplarisch, dass bei der Entwicklung von KI nicht nur die „Feature-Höhe“ zählt, sondern auch die Ausstattung mit Verlässlichkeit, Präzision und der Fähigkeit, strikte Instruktionen zuverlässig umzusetzen.
Für technische Autoren, Entwicklerteams und technologische Dienstleister ist es essenziell, diese Unterschiede bei der Modellwahl zu berücksichtigen. Wer GPT-4o in automatisierten Workflows einsetzt, sollte zusätzliche Kontrollmechanismen einbauen oder alternative Lösungen prüfen, wenn die Einhaltung von Code-Stilen und Syntax zwingend notwendig sind. In Szenarien mit strengem Qualitätsanspruch ist GPT-4-turbo nach wie vor die empfehlenswerte Wahl. Zudem zeigt die Situation auch, wie wichtig Nutzer-Feedback und offene Community-Dokumentation sind, um die Entwicklung und Feinjustierung von KI-Systemen nachhaltig zu unterstützen. Transparenz über Probleme und deren systematische Erfassung ermöglichen es Softwareherstellern wie OpenAI, gezielte Updates zu planen und die Modelle in Folgeversionen zu verbessern.
Es gilt, einen guten Kompromiss zwischen Kreativität und Disziplin im Code-Output zu finden, um die vielfältigen Ansprüche der Anwender zufriedenstellend abzudecken. Zusammenfassend lässt sich sagen, dass GPT-4o in Bezug auf die Einhaltung strenger Programmier-Prompts deutliche Schwächen aufweist, die sich in gebrochener Code-Struktur und Formatierungsabweichungen manifestieren. Im Vergleich ist GPT-4-turbo stabiler und zuverlässiger, wenn es um präzise und reproduzierbare Codeausgaben geht. Diese Erkenntnis sollten Nutzer bei der Integration der KI in technische Projekte und Softwareentwicklungsprozesse beachten. Während GPT-4o für explorative, flexible Wirkungen geeignet sein mag, bleibt GPT-4-turbo die bevorzugte Option für präzise und strikte Programmier-Anwendungen.
Die kontinuierliche Analyse und das Feedback aus der Community werden langfristig dazu beitragen, die Leistungsfähigkeit aller Modelle zu optimieren und Fehlentwicklungen entgegenzuwirken.