Die rasante Entwicklung großer Sprachmodelle hat die Welt der künstlichen Intelligenz nachhaltig verändert. Ein Verständnis der Kerntechnologien wie „Attention“ und „Transformers“ ist daher unumgänglich, um nicht nur die Funktionsweise dieser Modelle zu erfassen, sondern auch ihre Bedeutung und die Hintergründe ihrer Leistungsfähigkeit zu würdigen. Diese Konzepte sind oft mit abstrakten Fachbegriffen und komplexen mathematischen Formeln umhüllt, was Lernen und Verstehen erschwert. Dennoch birgt gerade das Begreifen dieser Technologien das Potenzial, das aktuelle und künftige Stimmungsbild der KI-Forschung mitzugestalten und das Innovationspotenzial im Bereich natürlicher Sprachverarbeitung zu fördern. Der Begriff „Attention“ ist in der Fachwelt spätestens seit der Veröffentlichung von Vaswani et al.
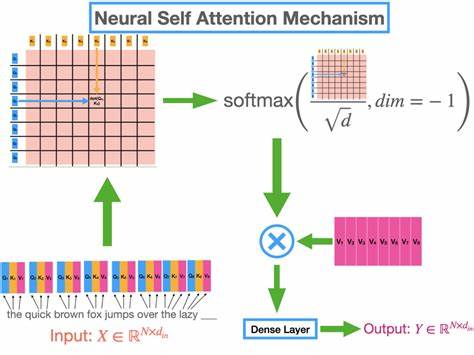
(2017) ein Schlüsselbegriff. Generell bezeichnet „Attention“ in großen Sprachmodellen einen Mechanismus, der Eingabedaten gewichtet, um relevante Informationen besser hervorzuheben. Trotz der Namensgleichheit hat diese Form von „Attention“ allerdings wenig mit menschlicher Aufmerksamkeitssteuerung zu tun, sondern ist eher eine mathematische Technik, die Ähnlichkeiten zwischen Datenpunkten greifbar macht. Grundlegend erinnert sie an Methoden der Kernel-Glättung, bei denen ein Kernelfunktion verwendet wird, um gewichtete Mittelwerte zu bilden und Datenpunkte gemäß ihrer Ähnlichkeit zu einem Referenzpunkt gewichtet einzubeziehen. Dieses Konzept lässt sich anschaulich erklären: Man besitzt eine Sammlung von Vektoren, die durch ähnliche Eigenschaften miteinander verbunden sind.
Um eine Vorhersage oder Klassifikation für einen neuen Datenpunkt zu treffen, wird geprüft, wie ähnlich dieser zu anderen Punkten in der Datenmenge ist – je ähnlicher, desto größer der Einfluss. Im Ergebnis entsteht ein gewichteter Durchschnitt, der die neue Eingabe bestmöglich repräsentiert. In den großen Sprachmodellen wird diese Ähnlichkeit durch sogenannte „Keys“, „Queries“ und „Values“ operationalisiert. Die „Query“ steht für das Eingabevektor, die „Keys“ beschreiben die gespeicherten Vektoren, und die „Values“ sind die Inhalte, von denen ein gewichteter Mittelwert ermittelt wird. „Self-Attention“ bedeutet dabei, dass die Werte oft direkt von den Eingabedaten abgeleitet sind, was eine dynamische, kontextabhängige Verarbeitung ermöglicht.
Wichtiger als die einfache „Attention“-Form ist allerdings das Konzept der „Multi-Headed Attention“. Hierbei werden mehrere solcher Kernelfunktionen parallel verwendet, wodurch verschiedene Aspekte der Eingabedaten simultan gewichtet werden können. Das Resultat ist eine zusätzliche Flexibilisierung bei der Verarbeitung, da unterschiedliche „Attention Heads“ verschiedene Muster in den Datenätzen identifizieren und kombinieren können. Dieses Mehr-Kopf-System trägt entscheidend zu der bemerkenswerten Leistung moderner Sprachmodelle bei. Im Kern fußt die Architektur großer Sprachmodelle auf sogenannten „Transformers“.
Sie sind eine Abstraktion und Weiterentwicklung der reinen Attention-Mechanismen und bestehen aus mehreren neuronalen Netzen, die durch Attention-Schichten verbunden sind. Ein Transformer führt schrittweise eine Abfolge von Transformationen der Eingabedaten durch: Zunächst werden die Textdaten in eine Abfolge von sogenannten Tokens getrennt, wobei diese Tokens dann in Vektoren (Embedding) umgewandelt werden. Anschließend werden Positionsinformationen hinzugefügt, um die Reihenfolge der Tokens zu berücksichtigen, da die reine Attention-Mechanik sequenzunabhängig arbeitet. Die Transformers arbeiten dann mit Layern, die mehrere Schritte kombinieren: Attention-Berechnung, Feedforward-Netzwerke zur nichtlinearen Verarbeitung und Normalisierungsschritte. Durch mehrere geschichtete Kombinationen (Stacks) dieser Layer werden die Eingabedaten iterativ verfeinert und um Kontextinformationen bereichert.
Am Ende jeder Transformer-Einheit steht die Produktion einer Wahrscheinlichkeitsverteilung über mögliche nachfolgende Tokens, aus der ein neues Wort oder Zeichen generiert wird. Ein fundamentaler Aspekt lässt sich durch die Betrachtung großer Sprachmodelle als Markov-Modelle verstehen. Trotz ihrer Komplexität sind sie letztlich spezielle endliche Reihenfolgemodelle mit begrenztem Kontextfenster. Das bedeutet, dass nur eine festgelegte Anzahl vorheriger Tokens als Kontext für die Vorhersage eines neuen Tokens berücksichtigt wird. Dieses Prinzip ist zwar technisch eine Einschränkung, doch die Fähigkeit zur geschickten Glättung und Interpolation komplexer Kontextinformationen führt dennoch zu erstaunlich naturgetreu erscheinenden Texten.
Diese Architektur ermöglicht es den Modellen, sehr unterschiedliche Texteigenschaften zu erfassen, jedoch stößt sie an Grenzen, wenn es um die Wiedergabe langanhaltender Abhängigkeiten oder komplexer Regelwerke geht, die nicht durch lokale Kontextfenster erfasst werden können. Auch der Umstand, dass alle Parameter – Eingabe-Embeddings, Gewichtungsmatrizen und Attention-Matrizen – während des Trainings gemeinsam gelernt werden, führt zu einer Vielzahl symmetrischer Lösungen und erschwert die direkte Interpretation der gelernten Werte. Das Zusammenspiel von Attention und Transformers wird daher oft als eine besonders elegante Möglichkeit gesehen, langreichweitige Zusammenhänge in Texten zu modellieren. Die Fähigkeit, unterschiedliche Aufmerksamkeitsschwerpunkte durch mehrere Attention-Heads gleichzeitig zu berücksichtigen, verleiht der Architektur ihre Flexibilität und Stärke. Die feedforward-Netzwerke innerhalb der Transformer sorgen darüber hinaus dafür, dass komplexe, nicht-lineare Abhängigkeiten abgebildet werden, die über einfache gewichtete Mittelwerte hinausgehen.
Ein weiterer spannender Diskussionspunkt ist die Tatsache, dass große Sprachmodelle trotz ihrer Komplexität letztlich auf bekannten statistischen Prinzipien beruhen. Sie sind in gewisser Hinsicht erweiterte Markov-Modelle mit ausgeklügelten Glättungsmechanismen. Dies zeigt, dass gerade das Zusammenspiel aus bewährten mathematischen Methoden und innovativer neuronaler Architektur den heutigen Leistungsstand ermöglicht. Dennoch sind diese Modelle keine Universalprinzipien der Sprache. Sie können niemals die gesamte Bandbreite menschlicher Sprachfähigkeit und Bedeutungsvielfalt vollständig erfassen, vor allem, da sie keinen expliziten persistenten Zustand oder Weltmodell besitzen.
Was die praktischen Anwendungen betrifft, so ist der Einsatz solcher Modelle mittlerweile breit gefächert. Von automatischer Übersetzung über Textgenerierung bis hin zu komplexen Dialogsystemen gewinnen Modelle auf Basis von Attention und Transformers zunehmend an Bedeutung. Dabei hat sich gezeigt, dass insbesondere das Training auf großem Textkorpus und die Skalierung der Modelle entscheidend sind, damit sie neue Fähigkeiten, sogenannte Emergenz-Effekte, zeigen können, die bei kleineren Modellen nicht auftreten. Trotz aller Fortschritte bleiben aber auch kritische Fragen bestehen. Die Interpretierbarkeit der Modelle ist sehr eingeschränkt, und das Konzept von „Aufmerksamkeit“ wird oft missverstanden oder fehlinterpretiert.
Auch die Tatsache, dass in vielen Fällen die Trainingsdaten schlecht dokumentiert sind und teils nicht ausreichend skaliert oder geprüft wurden, erschwert eine klare wissenschaftliche Einordnung. Zudem bergen die Modelle Risiken, etwa durch Halluzinationen, inkorrekte Schlussfolgerungen oder die Reproduktion gesellschaftlicher Vorurteile, die in den Trainingsdaten vorhanden sind. Die Forschung arbeitet derzeit intensiv daran, diese Schwächen zu adressieren. Verbesserte Trainingstechniken, neue Architekturvarianten und Methoden zur Unsicherheitsquantifizierung sollen zur Steigerung der Modellzuverlässigkeit beitragen. In diesem Zusammenhang ist auch das Thema „Soft Prompts“ interessant, bei dem Eingaben nicht nur als Textsequenzen, sondern als lernbare Vektoren aufgefasst werden, was eine elegantere und effektivere Kontrolle ermöglicht.
Die Zukunft großer Sprachmodelle und neuronaler Architekturen wie Transformers ist vielversprechend. Neue Ansätze, wie etwa State-Space-Modelle oder hybride Architekturen, die persistente Zustände modellieren können, könnten langfristig dazu führen, dass die Modelle noch besser in der Lage sind, komplexe Sprachstrukturen, Themenwechsel und tiefere Bedeutungszusammenhänge zu erfassen. Gleichzeitig bleibt es wichtig, die technologischen Fortschritte kritisch zu begleiten und ethische wie gesellschaftliche Auswirkungen zu beachten. Zusammenfassend lässt sich festhalten, dass das Verständnis von Attention und Transformers den Schlüssel bildet, um die wahre Funktionsweise großer Sprachmodelle zu durchdringen. Hinter der scheinbaren Komplexität offenbaren sich vertraute statistische Techniken in neuem Gewand, deren Kombination mit leistungsfähiger Rechenkapazität und umfangreichen Datensätzen die beeindruckenden Fähigkeiten heutiger KI-Systeme erklärt.
Für Entwickler, Forschende und Anwender von künstlicher Intelligenz ist es daher essenziell, sich mit diesen Grundlagen auseinanderzusetzen, um fundierte und verantwortungsbewusste Innovationen gestalten zu können.