Die rasante Entwicklung großer Sprachmodelle (LLMs) hat die Künstliche Intelligenz revolutioniert und eine Vielzahl von Anwendungen in den unterschiedlichsten Bereichen ermöglicht. Trotz ihrer Leistungsfähigkeit besteht jedoch eine zentrale Herausforderung darin, diese mächtigen Modelle für spezifische Aufgaben zu spezialisieren. Traditionell erfordert die Anpassung eines Modells an neue Anforderungen einen aufwändigen Prozess der Feinabstimmung, der oftmals große Mengen an Trainingsdaten und hohen Rechenaufwand benötigt. Genau hier setzt Text-to-LoRA (T2L) an – eine innovative Methode, die eine sofortige, dynamische Anpassung von Sprachmodellen durch natürliche Sprache ermöglicht. Text-to-LoRA erschafft eine neue Ära flexibler und zugänglicher KI-Anwendungen, bei denen Benutzer einfach eine Textbeschreibung eingeben, um ein Modell für verschiedenste Aufgaben anzupassen, ohne selbst in komplexe Feinabstimmung einzusteigen.
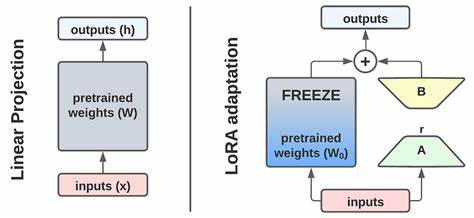
Das Fundament der Methode basiert auf der Kombination von zwei wegweisenden Konzepten: Low-Rank Adaptation (LoRA) und Hypernetzwerken. LoRA hat sich als effektive Technik etabliert, um die Anpassung großer Modelle durch das Einfügen kleiner, effizienzorientierter Adapter zu ermöglichen, wodurch der traditionelle Aufwand für die Neu-Trainierung drastisch verringert wird. Hypernetzwerke gehen einen Schritt weiter, indem sie Netzwerke schaffen, die die Gewichte anderer Modelle generieren können. Text-to-LoRA verschmilzt diese Ideen, indem es eine Hypernetzwerk-Architektur verwendet, die unmittelbar aus einer einfachen Textbeschreibung einen kompletten Satz von LoRA-Adaptern erzeugt. Der Clou des Systems liegt darin, dass es keinen eigenen Trainingsprozess für jede neue Aufgabe mehr braucht.
Stattdessen reicht ein natürlicher Sprachbefehl oder eine Beschreibung, der den gewünschten Aufgabenbereich definiert. Der T2L-Hypernetzwerk-Mechanismus verarbeitet dabei nicht nur die Aufgabenbeschreibung, sondern berücksichtigt auch die exakten Positionen im Basismodell, wie spezifische Layer und Modulteile, die angepasst werden sollen. Diese strukturierte Eingabe gewährleistet eine präzise und effiziente Adaptergenerierung in einem einzigen Durchlauf, wodurch der gesamte Vorgang enorm beschleunigt wird. Die Entwicklerinnen und Entwickler von Text-to-LoRA haben das Modell mit verschiedenen Strategien trainiert, um dessen Leistungsfähigkeit zu maximieren. Neben der Kompression bereits existierender LoRA-Adapter durch Rekonstruktionsverlust wurde eine besonders wirkungsvolle Methode verfolgt: das überwachte Fine-Tuning (Supervised Fine-Tuning, SFT).
Hierbei lernt das Hypernetzwerk, basierend auf einer großen Bandbreite unterschiedlichster Aufgaben, eigenständig sinnvolle Adapter zu erzeugen, die in Folge auch völlig neue, zuvor unbekannte Aufgaben meistern können. Dieses Prinzip eröffnet den Weg für echtes Null-Schuss-Lernen, bei dem Modelle unmittelbar und ohne weitere Beispiele angepasst werden können. Die praktischen Konsequenzen dieser Technologie sind vielseitig und tiefgreifend. Für Unternehmen und Entwickler bedeutet T2L eine erhebliche Einsparung an Ressourcen, da aufwändige Mehrfach-Trainings für individuelle Aufgaben entfallen. Die Fähigkeit, die Modellanpassung einfach durch eine textuelle Instruktion zu steuern, erweitert zudem die Zugänglichkeit für Nutzer ohne tiefgehende Machine-Learning-Kenntnisse.
Vorstellbar sind personalisierte KI-Assistenten, die sich durch einfache Kommunikation live auf individuelle Bedürfnisse einstellen. Ebenso können Entwicklerplattformen von der Möglichkeit profitieren, neue KI-Fähigkeiten nicht mehr klassisch zu programmieren, sondern durch gezielte Beschreibung in menschlicher Sprache zu integrieren. Die Forschungsergebnisse zu Text-to-LoRA wurden mit verschiedenen Basis-Language-Models, darunter Modelle von Mistral, Meta und Google, durchgeführt. Dabei stellte sich heraus, dass die SFT-Trainingsmethode nicht nur die Qualität der generierten Adapter auf unbekannte Aufgaben verbessert, sondern auch die Leistung gegenüber gängigen Baselines wie Mehrfach-LoRA oder In-Context-Lernen signifikant übertrifft. Insbesondere das T2L-L Modell, mit der höchsten Parameterausstattung, verzeichnete eine deutliche Steigerung der Benchmark-Leistungen im Vergleich zur Ausgangsbasis.
Ein weiterer bemerkenswerter Vorteil von Text-to-LoRA ist die Komprimierungsfähigkeit. Die Methode ist in der Lage, große Sammlungen zuvor trainierter LoRA-Adapter in einem einzigen Hypernetzwerk zu bündeln und damit Speicher- und Rechenressourcen einzusparen. Diese Effizienz entsteht nicht nur durch die Reduktion der Parameteranzahl, sondern auch durch die Regularisierung, die im Trainingsprozess implementiert ist und Überanpassung vermeidet. Nicht zu vernachlässigen sind die Limitationen und Herausforderungen, die noch offen sind. Die Qualität der Eingabetextbeschreibung beeinflusst maßgeblich die Effektivität der Modellanpassung.
Vage oder schlecht formulierte Beschreibungen können die Performance mindern. Zudem besteht derzeit noch eine Leistungslücke zwischen den sofort generierten Adaptern und den in separaten Trainingsprozessen optimierten Gold-Standard-Adaptern. Dennoch zeigen die aktuellen Ergebnisse ein großes Potenzial, das über weitere Forschung kontinuierlich ausgeschöpft werden kann. Zukunftsperspektiven eröffnen zahlreiche spannende Forschungsfragen. So könnte eine Modelltransferierung erfolgen, bei der ein auf kleinen Modellen trainiertes T2L-Hypernetzwerk für größere Sprachmodelle genutzt wird.
Ebenso denkbar ist eine Erweiterung der Technologie hin zu anderen Anpassungsmechanismen, etwa durch direkte Modulation von Modellaktivierungen statt der klassischen Parameteranpassung. Diese Entwicklungen würden den Anwendungsbereich deutlich verbreitern und die Anpassungsfähigkeit von KI-Systemen noch weiter verbessern. Text-to-LoRA stellt somit einen bedeutenden Schritt auf dem Weg zu einer dynamischen, flexiblen KI dar, die sich intuitiv per Sprache steuern lässt. Es ermöglicht, dass die Anpassung großer Modelle keine domänenspezifische Expertise mehr erfordert, sondern durch einfache natürliche Anweisungen möglich wird. Dieser Paradigmenwechsel birgt das Potenzial, KI-Anwendungen grundlegend zu verändern – hin zu Systemen, die nicht nur leistungsstark, sondern auch zugänglich und benutzerfreundlich sind.
Für die Praxis bedeutet dies tiefgreifende Veränderungen: Firmen können schneller auf Marktanforderungen reagieren, Entwickler können innovativere Anwendungen schaffen und Endnutzer profitieren von personalisierten, bedarfsorientierten KI-Lösungen. Text-to-LoRA zeigt, wie die Symbiose aus menschlicher Sprache und maschinellem Lernen die Barrieren zur Individualisierung großer KI-Modelle revolutioniert und somit einen neuen Standard für Adaptivität und Effizienz setzt. Insgesamt ist Text-to-LoRA nicht nur ein technisches Konzept, sondern ein Meilenstein auf dem Weg zu einer ganz neuen Dimension des Umgangs mit künstlicher Intelligenz. Es bringt die Vision näher, KI-Systeme über präzise, unkomplizierte Kommunikation anzupassen und eröffnet damit vielfältige Chancen für Forschung, Entwicklung und den breiten Einsatz intelligenter Systeme in der realen Welt.