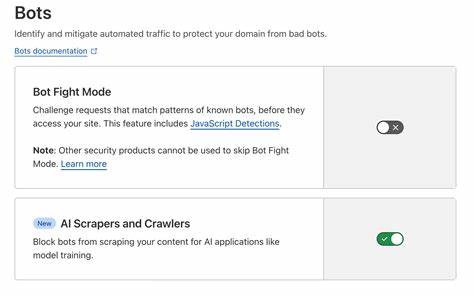
In der heutigen digitalen Welt stellen KI-basierte Scraper eine ernsthafte Herausforderung für Server-Administratoren dar. Diese automatisierten Bots durchforsten Websites in großem Umfang, um Daten zu extrahieren, und können so durch massiven Traffic den Server überlasten. Besonders problematisch ist es, wenn diese Scraper nicht nur einzelne IP-Adressen nutzen, sondern ganze IP-Blöcke, was die Abwehr deutlich erschwert. Die daraus entstehenden Lastspitzen können dazu führen, dass nicht nur die Website langsamer wird, sondern im schlimmsten Fall kompletter Serverausfall droht. Wenn zusätzlich automatisiert große Dateien, wie beispielsweise generierte Quellarchive, heruntergeladen werden, füllt sich der Speicherplatz schnell, was Kaskadeneffekte auf Serversysteme und Datenbanken hat.
Es wird deutlich, dass herkömmliche Schutzmechanismen oft nicht ausreichen, um diesen Angriffen effektiv zu begegnen. Ein erster Reflex ist häufig die Einbindung einer robots.txt-Datei, um unerwünschte Bots abzuwehren. Doch viele dieser KI-Scraper ignorieren diese Datei und agieren sehr resolut. Selbst populäre Suchmaschinen respektieren die robots.
txt zwar, aber schädliche Bots nicht. Eine weiterer Schutzansatz ist die Implementierung von Rate-Limitierungen. Dabei kann zum Beispiel die Middleware eines Reverse-Proxy-Servers wie Traefik eingesetzt werden, um Anfragen von einer einzelnen IP-Adresse oder IP-Blockade zu begrenzen. Dies führt dazu, dass die Bots nicht mehr unkontrolliert Anfragen in hoher Frequenz absetzen können. Allerdings zeigt sich in der Praxis häufig, dass Angreifer IP-Adressen in großem Umfang wechseln oder ganze /16-Netzwerke von großen Providern wie Alibaba nutzen.
Dadurch versagt die reine IP-basierte Beschränkung schnell ihre Wirkung und erschwert auch legitimen Nutzern den Zugang, wenn die Limits zu niedrig angesetzt sind. Daher müssen Rate-Limits sensibel kalibriert und gegebenenfalls dynamisch angepasst werden, um eine Balance zwischen Schutz und Nutzerfreundlichkeit zu gewährleisten. Ein zusätzliches Mittel ist die Nutzung von Captchas, die automatisierte Anfragen herausfiltern. Dabei wird jedoch oft die User Experience beeinträchtigt, da auch legitime Besucher plötzlich vor Herausforderungen stehen. Insbesondere wenn die Scraper sehr großflächig und aggressiv vorgehen, kann dies die Serverressourcen extrem beanspruchen.
Ein gravierendes Problem zeigte sich beispielsweise bei der automatischen Erstellung von ZIP-Archiven auf dem Server. Sobald diese von Scraper-Bots massenhaft heruntergeladen werden, füllt sich der verfügbare Speicherplatz rasant auf. Dies verursacht nicht nur Fehler im Filesystem, sondern führt auch zu einem Anstieg des Speicherverbrauchs, was schließlich zum Absturz von Diensten und zum Versagen von Datenbank-Operationen führen kann. In der Praxis stellte sich heraus, dass das bloße Aufräumen temporärer Dateien zwar kurzfristige Erleichterung schafft, aber keine nachhaltige Lösung bietet. Um solchen Angriffen längerfristig standzuhalten, ist die Kombination verschiedener Technologien entscheidend.
CrowdSec ist eine interessante Option aus dem Bereich der Community-basierten Verteidigung. Mit dieser Software lassen sich IP-Adressen und IP-Blöcke, die sich verdächtig verhalten, automatisiert erkennen und blockieren. Leider zeigten sich in der Anwendung von CrowdSec Einschränkungen, da sich Angreifer häufig sehr schnell auf neue IP-Adressen verteilen und somit den Bann-Maßnahmen entgehen können. Zudem kann CrowdSec bei fehlerhaften Regeln auch legitime Nutzer behindern, was die Administration zusätzlich erschwert. Eine alternative Lösung, die speziell auf die Unterscheidung zwischen legitimen Nutzern und automatisierten Scrapers abzielt, ist der Einsatz von Tools wie go-away.
Dieses bietet die Möglichkeit, Anfragen anhand von Merkmalen wie TLS-Fingerprinting zu filtern, was die Identifikation von Bots erhöht und gleichzeitig echte Nutzer möglichst wenig einschränkt. Ein weiterer Vorteil von go-away ist, dass es in die bestehende Infrastruktur integriert werden kann, etwa durch Einbindung in Traefik. Damit lassen sich unerwünschte Zugriffe effizient herausfiltern, ohne die Serverperformance stark zu beeinträchtigen. Allerdings sind erweiterte Features wie HTTPS-Tracking nicht ohne Nebenwirkungen und erfordern sorgfältige Abwägung. Generell erfordert der Schutz vor KI-Scrapern eine mehrschichtige Strategie.
Ausschließlich IP-Blockierung oder einfache Regeln reichen selten aus. Vielmehr müssen Systeme dynamisch auf das Verhalten der Besucher reagieren und neue Muster analysieren können. Zudem ist es wichtig, Server-Logs kontinuierlich auszuwerten, um ungewöhnliche Anfragemuster frühzeitig zu erkennen und automatisierte Gegenmaßnahmen zu ergreifen. Ein weiterer Aspekt ist die Optimierung der Server-Infrastruktur. Wenn beispielsweise automatische Archiv-Erstellungen vermieden oder besser kontrolliert werden, reduziert sich die Angriffsfläche deutlich.
Auch das Anpassen der Timeouts und die Begrenzung gleichzeitig laufender Prozesse können wichtig sein, um die Auswirkungen eines Angriffs zu minimieren. Bei der Kommunikation mit Nutzern sollte Transparenz gewahrt bleiben, vor allem wenn temporär Maßnahmen wie Captchas oder IP-Banns den Zugang erschweren. Klare Hinweise und alternative Zugriffsmöglichkeiten helfen, Frust auf Seiten legitimer Besucher zu reduzieren. Langfristig lohnt es sich, zusätzliche Schutzmechanismen in die eigene Website zu integrieren. Dazu gehören etwa Web Application Firewalls (WAF), die speziell auf bekannte Angriffsmuster reagieren, und Content-Delivery-Networks (CDN), die den Traffic vorfiltern und lokal cachen können, um die Backend-Server zu entlasten.
Es ist auch empfehlenswert, sich über aktuelle Trends im Bereich Web-Security auf dem Laufenden zu halten und regelmäßig bestehende Schutzmaßnahmen zu evaluieren. Die Herausforderung, KI-Scraper abzuwehren, ist dynamisch und erfordert sowohl technische Kenntnisse als auch regelmäßige Pflege der Systeme. Ein Netzwerk von Community-basierten Diensten kann dabei unterstützen, indem es Erkenntnisse über neue Bedrohungen teilt und so die Reaktionsfähigkeit verbessert. Abschließend lässt sich festhalten, dass ein ganzheitlicher Sicherheitsansatz der effektivste Weg ist, um den reibungslosen Betrieb eines Servers trotz aggressiver KI-Scraper zu gewährleisten. Die Kombination aus intelligenten Filtern, dynamischen Rate-Limiting-Strategien und Nutzen moderner Tools sorgt dafür, dass sowohl legitime Nutzer optimal bedient werden als auch schädliche Bots vom Zugriff abgehalten sind.
Nur durch kontinuierliche Anpassung und Beobachtung der Serveraktivitäten können Ausfälle und Leistungseinbußen langfristig vermieden werden.