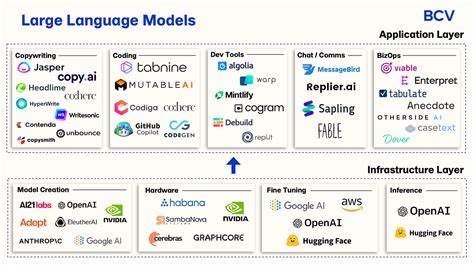
Große Sprachmodelle, kurz LLMs, haben das Potenzial, die Art und Weise grundlegend zu verändern, wie Software entwickelt, Produkte gestaltet und sogar Wissen verarbeitet wird. Doch eine zentrale Frage beschäftigt viele Entwickler, Forscher und Technologiebegeisterte: Warum sind die leistungsfähigsten LLMs weitgehend proprietär und mit hohen Nutzungskosten verbunden? Und wie beeinflusst das die Softwareindustrie und den freien Zugang zu Schlüsseltechnologien? Historisch gesehen war die Softwarewelt von Innovationen geprägt, die häufig als Open Source verfügbar gemacht wurden und so eine breite Gemeinschaft im Fortschrittsprozess einbanden. Technologien wie der Linux-Kernel, Git, PostgreSQL oder Kubernetes sind heute integraler Bestandteil der digitalen Infrastruktur und gleichzeitig frei zugänglich. Diese Offenheit förderte Innovation, Kooperation und den Ausbau von Wissen. Im Gegensatz dazu dominieren bei LLMs Unternehmen wie OpenAI, Anthropic oder Google mit ihren Modellen GPT, Claude oder Bard den Markt.
Ihre Systeme sind zwar beeindruckend leistungsstark, erfordern jedoch häufig eine kostenpflichtige Nutzung. Dieser Umstand wirft grundlegende Fragen zur Demokratisierung von Technologie, zur Transparenz der Modelle und zu den möglichen Abhängigkeiten auf. Für viele stellt sich die Situation so dar, dass eine Kerntechnologie, die künftig Teil des alltäglichen technologischen Fundaments werden könnte, nicht frei verfügbar ist. Dabei sind die Hürden bei der Entwicklung und dem Training von LLMs enorm: Es werden riesige Datenmengen benötigt, wofür oft enorme Rechenkapazitäten und damit auch finanzielle Ressourcen erforderlich sind. Diese Faktoren limitieren zudem oft die Entwicklung qualitativ hochwertiger Open-Source-Alternativen.
Zwar existieren Projekte, die versuchen, freie LLMs zu etablieren, und diese machen durchaus Fortschritte – dennoch sind sie hinsichtlich Leistungsfähigkeit und Skalierbarkeit meist noch hinter den proprietären Vorreitern zurück. Viele Softwareentwickler sehen in den proprietären LLMs praktische Werkzeuge, die ihre Effektivität steigern und neue Produktivitätsmaßstäbe setzen. Insbesondere im Vergleich zur kostenintensiven manuellen Programmierung scheinen die Modelle eine kostengünstige Alternative zu sein. Dennoch signalisiert diese Abhängigkeit von proprietären Modellen auch ein Risiko: Wenn zentrale Werkzeuge nur über kostenpflichtige APIs oder limitierte Cloud-Dienste zugänglich sind, entsteht eine Kontrolle über die technologische Infrastruktur in den Händen weniger Konzerne. Dies kann die Innovationsdynamik beeinflussen und möglicherweise zu einer monopolartigen Marktkonzentration führen.
Aus Sicht einiger Experten könnte sich der Markt ähnlich wie bei früheren Technologien entwickeln. Beispielsweise starteten Suchtechnologien einst als proprietäre Angebote, ehe Open-Source-Plattformen wie Elasticsearch den Markt breiteten und kostengünstige, selbst gehostete Lösungen anboten. Ein Szenario ist daher, dass LLMs künftig durch eine Mischung aus proprietären Hauptanbietern und robusten Open-Source-Alternativen ergänzt werden. Unternehmen könnten ihren Fokus auf umfassende Support-Dienstleistungen, maßgeschneiderte Features oder spezialisierte Enterprise-Lösungen legen, während Basisversionen als freie Software vorliegen. Allerdings stellt die Hardwarefrage eine bedeutende Herausforderung dar.
Die Trainings- und Betriebskosten großer Sprachmodelle sind enorm und treiben viele davon ab, eigene Instanzen zu hosten. Dies fördert Modelle, die auf Cloud-Dienste angewiesen sind und somit wieder bei einem zentralisierten Anbieter landen. Dennoch gibt es Enthusiasten und kleine Gemeinschaften, die versuchen, mit erschwinglicher Hardware selbst Modelle mit mehreren Milliarden Parametern zu betreiben. Dabei wird Geschwindigkeit oft gegen Autonomie abgewogen. Diese Ansätze zeigen, dass auch dezentralere Nutzung möglich ist, wenn auch mit Kompromissen.
Interessanterweise erinnert die gegenwärtige Situation an die Entwicklung von CAD-Software, die lange von hochpreisigen proprietären Programmen dominiert wurde. Mittlerweile gibt es zwar kostenlose Alternativen, doch die Top-Tools sind immer noch hauptsächlich nicht-open-source. Auch bei Schach-Engines konnte sich mit Stockfish ein freies Modell an die Spitze setzen. Viele hoffen, dass sich im Bereich der LLMs eine ähnliche Dynamik entwickelt: Ein Open-Source-Modell erreicht irgendwann vergleichbare Qualität und verlagert den Markt zugunsten offener Lösungen. Auch wenn manche den Standpunkt vertreten, offene Modelle seien deutlich weniger fähig, zeigen fortschreitende Entwicklungen das Potenzial, diesen Abstand zu schließen.
Einige argumentieren, dass die Kernkomponente eines LLMs letztlich die Qualität der Trainingsdaten und -prozesse ist. Deren Erhebung, Aufbereitung und finanzielle Aufwände lassen sich nur schwer demokratisieren, was ein natürliches Hindernis für freie Modelle darstellt. Dennoch konnten viele Open-Source-Projekte durch Crowd-Sourcing oder alternative Datensammlungen bereits beachtliche Fortschritte erzielen. Die historische Betrachtung zeigt, dass viele Schlüsseltechnologien zunächst proprietär waren, bevor sie sich öffneten oder durch offene Standards und Lösungen ergänzt wurden. Menschliche Gesellschaften neigen dazu, leistungsfähige Werkzeuge zugänglicher zu machen, sobald diese eine kritische Masse erreicht.
So entstanden nach langem Ringen viele öffentliche Infrastrukturen, von Netzprotokollen bis hin zu Open-Source-Bibliotheken. Die Zukunft der LLMs könnte entweder einen ähnlichen Weg gehen oder in einer besonders proprietären Umgebung verharren, in der Nutzer an Zahlungsströme gebunden sind. Für Entwickler, die aus Prinzip Offenheit und Kollaboration schätzen, wirft das Fragen auf, wie die Abhängigkeiten zu proprietären Modellen künftig gesteuert werden, wie Datenschutz und Transparenz gesichert werden können und wie Innovationskraft dezentral erhalten bleibt. Auf der anderen Seite zeigt der Markt, dass Nutzer pragmatisch agieren. Die Leistungsfähigkeit der Werkzeuge steht für viele im Vordergrund, selbst wenn dies eine kostenpflichtige Nutzung bedeutet.
Zudem gibt es neben den großen Anbietern bereits eine Vielzahl spezialisierter Projekte, die mit Nischenlösungen und eigenständigen Modellen ebenfalls produktiv sind. Letztlich stellt sich die Frage, wie sich der Softwareentwicklungsmarkt und die KI-Landschaft verändern, wenn LLMs unerlässlich werden. Werden offene Modelle irgendwann Leistungsniveaus erreichen, die proprietäre Systeme überflüssig machen? Oder verbleibt das Ökosystem dauerhaft gemischt? Entscheidend ist, ob die Community und Unternehmen genug Kraft und Ressourcen bündeln, um Open-Source-Alternativen zu stärken. Nur so können die Risiken einer Monopolstellung gemindert und der freie Zugang zu Schlüsseltechnologien gesichert werden. Die Diskussion um proprietäre versus offene LLMs spiegelt zudem größere gesellschaftliche Fragen wider: Wem gehört Wissen? Wie viel Kontrolle geben wir Unternehmen über Technologien, auf die wir täglich bauen? Und wie gestalten wir die Balance zwischen Innovation, Kommerzialisierung und Gemeinwohl? In jedem Fall wird die Entwicklung der großen Sprachmodelle unsere Zukunft prägen – und zwar in technischer, wirtschaftlicher und ethischer Hinsicht.
Die Herausforderungen sind komplex, doch die Chancen ebenso groß. Nur durch ein Bewusstsein für mögliche Konsequenzen und eine aktive Mitgestaltung kann eine zukunftsfähige KI-Landschaft entstehen, die alle Beteiligten langfristig unterstützt.