RSS-Feeds sind ein bewährtes Mittel, um aktuelle Inhalte aus verschiedensten Quellen zeitsparend zu sammeln und zu verarbeiten. Journalistinnen, Blogger und Entwickler vertrauen seit Jahren auf Feedparser-Tools, um RSS und verwandte Feed-Formate auszulesen. Doch trotz der Popularität existierender Bibliotheken zeigen sich immer wieder Herausforderungen: Manche Feeds werden nicht korrekt geparst, Inhalte wie CDATA bleiben unbeachtet, und bei gleichzeitiger Nutzung in asynchronen oder Multithreading-Umgebungen können Fehler und Warnungen auftauchen. Genau hier setzt BruteFeedParser an – ein Programmierwerkzeug, das das Parsen von Feeds mit einer unkonventionellen Herangehensweise angreift und als robustere Alternative etabliert werden will. Die Entstehung von BruteFeedParser basiert auf einem simplen aber effektiven Gedanken: Wenn konventionelle Feedparser versagen, dann muss man einfach mutiger an die Sache herangehen.
Anstatt den gängigen XML-Standards mit äußerster Genauigkeit zu generieren, verfolgt BruteFeedParser eine brute-force-Methode, die kompromisslos versucht, aus selbst schwierigsten und unkonventionellen Feed-Daten das Wesentliche herauszuziehen. Dabei wird bewusst auf strikte Standardkonformität verzichtet – mit dem Wissen, dass viele Feeds in freier Wildbahn von offiziellen Spezifikationen abweichen, ob nun durch schlechte Implementierungen, proprietäre Erweiterungen oder einfach veraltete Formate. Das Resultat ist ein Werkzeug, das gerade in unübersichtlichen Situationen besser funktioniert als etablierte Lösungen. Die Installation gestaltet sich denkbar einfach über den Python-Paketmanager pip. Ein einfaches Kommando genügt, um BruteFeedParser im eigenen Projekt zu verwenden und direkt mit der Feed-Analyse zu starten.
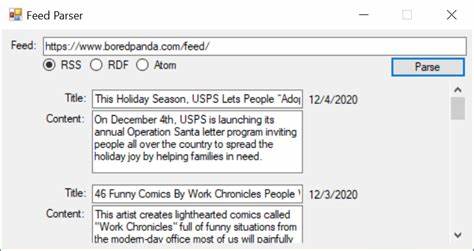
Der Aufruf der Parsing-Funktion ist direkt: Man übergibt den rohen Feed-Text an BruteFeedParser.parse() und erhält als Antwort ein Analyseobjekt mit den extrahierten Einträgen, Metadaten und Bildern, falls welche vorhanden sind. Besonders hervorzuheben ist die jüngste Erweiterung der Bibliothek, die es ermöglicht, Bilder, die innerhalb der Inhalte eingebettet sind, zu erkennen und extrahieren – ein Feature, das viele Feedparser so nicht oder nur eingeschränkt anbieten. Dadurch wird beispielsweise das Präsentieren von Artikeln mit zugehörigen Grafiken in Leser-Apps oder Webseiten erheblich erleichtert. Doch BruteFeedParser überzeugt nicht nur technikseitig mit seinem Ansatz.
Die Entwickler hinter dem Tool präsentieren den Parser mit einer ordentlichen Portion Humor und einer gewissen Selbstironie. Die Dokumentation ist gespickt mit witzigen Warnungen und humorvollen Anmerkungen, die auf die kompromisslose Brutalität des Programmcodes hinweisen. Solche Kommentare lockern nicht nur den technischen Alltag auf, sondern zeigen auch, dass hier bewusst eine pragmatische, experimentierfreudige Lösung entsteht, die keine Scheu hat vor langen Debatten über XML-Spezifikationen oder semantische Details. Gerade für Entwickler, die häufig mit nicht standardkonformen Feeds kämpfen, bietet sich BruteFeedParser als ein hilfreiches Werkzeug an, das sich auch für asynchrone Verarbeitung oder Multithreading eignet, ohne dabei in Fehler zu laufen – ein Schwachpunkt vieler anderer Parser. Die Entscheidung, bewusst keinerlei feste Standards verpflichtend zu implementieren, öffnet den Spielraum für eine höhere Fehlertoleranz und flexible Anwendung.
Besonders in Situationen, in denen es primär darum geht, möglichst viele Feeds schnell und zuverlässig zu verarbeiten – beispielsweise bei aggregierten News-Diensten, Social-Media-Streamern oder Datenanalysen – kann BruteFeedParser entscheidende Vorteile bringen. Natürlich sollte man sich auch der Grenzen bewusst sein. Die Lockere Handhabung von formalen Spezifikationen bedeutet, dass das Ergebnis gelegentlich etwas roh oder inkonsistent sein kann. Wer strikte Validierung, präzise XML-Compliance oder besonders geschliffene Metadaten benötigt, wird weiterhin auf konventionelle Tools zurückgreifen wollen. Doch gerade diese Abgrenzung macht BruteFeedParser zum idealen Werkzeug für den robusten Workhorse-Einsatz, der vor allem mit ungewöhnlichen oder realen Feeds umgehen kann, wo andere Bibliotheken versagen.
Die quelloffene Natur unter der GPL-3.0-Lizenz erlaubt es Entwicklern, den Quellcode eingehend zu studieren, eigene Optimierungen vorzunehmen und das Tool flexibel in diverse Projekte einzubinden. Trotz des geringen Verbreitungsgrades hat BruteFeedParser bereits Aufmerksamkeit auf Plattformen wie GitHub und Hacker News erregt, insbesondere unter Python-Enthusiasten, die nach unkomplizierten, pragmatischen Lösungen suchen. Die Kombination aus spielerischer Selbstironie und technischer Zuverlässigkeit macht es zu einem spannenden Beispiel dafür, wie Software nicht nur effizient, sondern auch mit einem gewissen Augenzwinkern gebaut werden kann. Für alle, die regelmäßig mit RSS-Feeds, Atom- oder RDF-Daten arbeiten und gelegentlich an die Grenzen etablierter Parsing-Bibliotheken stoßen, lohnt sich der Blick auf BruteFeedParser.
Er bietet eine praktische Alternative und zeigt außerdem auf amüsante Weise, dass die Softwareentwicklung auch mal mutig, unkonventionell und „brute-force“ sein darf, ohne den Spaß an der Technik zu verlieren. Wer also einen robusten Python-Parser sucht, der selbst knifflige Feeds zuverlässig ausliest und dabei unkompliziert sowie flexibel eingesetzt werden kann, sollte BruteFeedParser definitiv ausprobieren und in seine Tool-Sammlung aufnehmen. So entsteht ein leichter Zugang zu RSS-Daten auch in schwierigsten Situationen, während gleichzeitig der Alltag mit einer guten Portion Humor entschärft wird – und genau das schätzen viele Anwender heute an neuen Open-Source-Projekten.