Die rasante Entwicklung der künstlichen Intelligenz (KI) hat zu immer leistungsfähigeren Modellen geführt, deren Rechenbedarf exponentiell gewachsen ist. Herkömmliche zentrale Systeme stoßen dabei an Grenzen, insbesondere wenn es darum geht, Modelle in Echtzeit und mit akzeptabler Latenz für viele Anwender bereitzustellen. Genau an dieser Stelle gewinnen Peer-to-Peer (P2P) dezentrale Inferenzsysteme zunehmend an Bedeutung. Sie versprechen eine neue Ära, in der jeder mit handelsüblicher Hardware und Internetzugang zum Teil einer globalen, verteilten KI-Infrastruktur werden kann. Diese verteilte und offene Herangehensweise könnte das Fundament für eine demokratisierte und skalierbare KI-Landschaft werden.
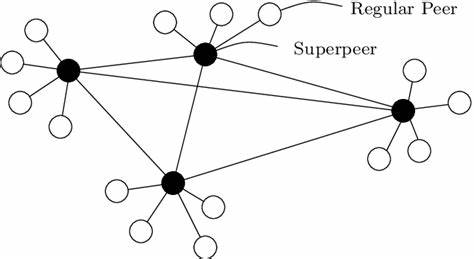
Peer-to-Peer dezentrale Inferenz bedeutet, dass die Ausführung der KI-Modelle nicht in einem einzigen Rechenzentrum, sondern auf vielen unabhängigen Geräten weltweit stattfindet. Fast jeder Arbeitsplatzrechner, jede Gamer-GPU oder jeder kleinere Server kann so zum Teil eines großen Netzwerks werden, in dem gemeinsam komplexe KI-Modelle berechnet werden. Das zentrale Ziel ist es, die enormen Rechenleistungen der künstlichen Intelligenz über ein Netzwerk von heterogenen Konsumentenressourcen nutzbar zu machen – mit dem Anspruch, Latenzen von etwa 100 Millisekunden und mehr unter den realen Bedingungen der öffentlichen Internetinfrastruktur zu meistern. Die Technik dahinter ist alles andere als trivial, da sie sich mit mehreren komplexen Herausforderungen auseinandersetzen muss. Die heterogene Zusammensetzung der genutzten GPUs, die unzuverlässigen Netzwerkeigenschaften, insbesondere die Latenzzeiten und verfügbaren Bandbreiten, sowie große Speicheranforderungen an die Zwischenspeicher für Modelle und Daten sind wesentliche Faktoren.
Im Gegensatz zu zentralisierten Systemen, die schnelle interne Vernetzung und durchgängige Hardwarekonsistenz besitzen, muss ein Peer-to-Peer-System diese inhärenten Widrigkeiten entschärfen, um eine effiziente und praktische Lösung zu bieten. Eine der Kerntechnologien, die Peer-to-Peer dezentrale Inferenz ermöglicht, ist Pipeline Parallelismus. Dabei wird das große KI-Modell in mehrere Teilmodelle segmentiert, jeweils von einem Gerät übernommen und verarbeitet. So bearbeitet jedes Gerät einen eigenen Abschnitt des Modells sequentiell und kommuniziert Zwischenergebnisse an das nächste Gerät weiter. Diese Methode hat den Vorteil, dass der Speicherbedarf pro Gerät drastisch sinkt, da kein Gerät das vollständige Modell laden muss.
Zudem eignen sich Pipeline-Parallelismen durch vergleichsweise geringe Kommunikationsanforderungen besonders gut für Netzwerke mit hoher Latenz. Das macht sie hervorragend geeignet für das öffentliche Internet, im Gegensatz zu Tensor-Parallelismus, der intensive Kommunikation innerhalb jeder Schicht erfordert und daher in verteilten Umgebungen nur schwer praktikabel ist. Allerdings ist Pipeline-Parallelismus nicht ohne Nachteile. Die sequentielle Natur des Prozesses führt häufig zu Leerlaufzeiten der GPUs, da Geräte auf die Zwischenergebnisse ihrer Vorgänger warten müssen. Ansätze wie asynchrone Micro-Batch-Scheduling können zwar diese Leerlaufzeit in Trainingsprozessen reduzieren, sind jedoch für den Inferenzbetrieb nicht effektiv genug, insbesondere da dieser von Speicherbandbreite und Gesamtspeicher limitiert ist und nicht primär von den Rechenkapazitäten.
Die inhärente Speicherlast entsteht vor allem durch die sogenannte KV-Cache, einen Zwischenspeicher für Schlüssel und Werte der vergangenen Token, der während der automatischen Textgenerierung Schritt für Schritt wächst. Diese Cache wächst linear mit der Batchgröße, womit große parallele Dekodierungsabläufe schnell an Speichergrenzen stoßen. Die intensive Auseinandersetzung mit der Speicher- und Kommunikationsarchitektur hat gezeigt, dass die derzeitigen Systeme meist im Speicherbandbreiten-gebundenen Modus laufen. Das bedeutet, dass der Datentransfer im Speicher oder über die Netzwerke die Fließkommaoperationen limitiert, wodurch Rechenleistung ungenutzt bleibt. Sowohl beim dekodieren eines einzelnen Tokens als auch beim parallelen Dekodieren mehrerer Sequenzen ist die Bewegung der Daten und der Aufbau des KV-Caches der Flaschenhals, nicht die eigentliche Rechenleistung.
Zur Lösung dieses Problems könnte es entscheidend sein, den Arbeitsablauf der Inferenz neu zu denken. Ein vielversprechender Ansatz ist, durch strategische Wiederverwertung von Rechenkapazitäten während der Wartezeiten in der Netzwerkkommunikation, Speicheranforderungen teilweise durch Mehrberechnungen zu ersetzen. Dieser Trade-off zwischen Speicherverbrauch und Rechenzeit verlangt eine veränderte Perspektive auf die Optimierung, indem man den Rechnerwert während Netzwerkpausen erhöht – ein Szenario, das man im öffentlichen Internet häufiger findet als in Rechenzentren mit hoher Netzwerkqualität. Eine weitere Optimierungsrichtung ist die Reduzierung des maximalen Speichernutzungsbedarfs während der Inferenz. Dies umfasst leichtere Cache-Mechanismen und eine intelligente Rekombination von Zwischenergebnissen.
Dabei muss eine Balance gefunden werden zwischen der Geschwindigkeit einerseits und der Speicher- sowie Netzwerkbelastung andererseits. Das Ziel ist eine Architektur, die dynamisch mit unzuverlässigen und variierenden Rechenressourcen umgehen kann, dabei aber die Durchsatzleistung hochhält und gleichzeitig Kosten für Teilnehmer im Netzwerk minimiert. Auf der praktischen Seite steht bereits heute eine offene Forschungsplattform zur Verfügung, die eine Kommunikation über öffentliche Netzwerke mittels Peer-to-Peer Backend gewährleistet und Pipeline-Parallelismus in kooperierenden Verbraucherhardware-Umgebungen implementiert. Die sogenannte PRIME-IROH-Kommunikationsschicht bildet die Basis für verteilte Datenübertragungen im Pipeline-Setup. PRIME-VLLM stellt die Pipeline-Parallelismus-Integration für große Sprachmodelle bereit und PRIME-PIPELINE erlaubt Forschungsarbeiten zur Validierung und Optimierung von Cache-Strategien und Scheduling-Verfahren, um diese neuen Ansätze kontinuierlich zu verbessern.
Die Möglichkeit, bestehende private Hardware in einem Netzwerk zu verbinden und über öffentliche Netze Inferenzoperationen durchzuführen, hat eine enorme wirtschaftliche und gesellschaftliche Reichweite. Jeder Nutzer kann theoretisch zur Verfügung stehende Rechenleistung und Speicherplatz bereitstellen und somit an einem demokratischen, dezentralen KI-Ökosystem teilnehmen. Im Gegenzug profitieren auch kleine Betreiber von der kollektiven Intelligenz, ohne auf teure Cloud-Infrastruktur angewiesen zu sein. Diese Entwicklung hat das Potenzial, nicht nur die ökonomischen Barrieren für KI-Anwendungen zu senken, sondern auch ethische und gesellschaftliche Fragen neu zu formulieren. Durch die Verteilung der Modellberechnung auf zahlreiche Teilnehmer kann eine größere Offenheit und Transparenz im Umgang mit künstlicher Intelligenz geschaffen werden.
Die Kontrolle verbleibt nicht bei einigen wenigen Konzernen, sondern wird von vielen Nutzern partizipativ geteilt. Abschließend lässt sich festhalten, dass Peer-to-Peer dezentrale Inferenz eine Schlüsseltechnologie für die nächste Generation von KI-Anwendungen darstellt. Die technische Herausforderung besteht darin, eine Balance zwischen Speicheranforderungen, Rechenleistung und Netzwerkkommunikation zu finden und gleichzeitig die inhärenten Latenzprobleme im öffentlichen Internet zu bewältigen. Durch den Einsatz von Pipeline Parallelismus und innovativen Scheduling-Strategien, gepaart mit einem neuen Verständnis von Speicher-Komputations-Trade-offs, kann eine skalierbare, performante und demokratische KI-Infrastruktur entstehen. Die Zukunft verspricht ein globales Netzwerk von KI-berechnenden Geräten, das sich nahtlos präsentiert und durch seine Offenheit sowie Skalierbarkeit neue Maßstäbe in der KI-Leistung setzt.
Während der Weg noch mit Herausforderungen gepflastert ist, zeigt die aktuelle Forschung frische Ideen und handfeste Ansätze, die den Traum von einer planetarischen KI-Rechenmaschine näherbringen. Somit ist Peer-to-Peer dezentrale Inferenz weit mehr als ein technisches Konzept – es ist ein Schritt hin zu einer gerechteren und universell zugänglichen KI-Welt.




![Ask HN: Why are startups suddenly branding themselves the "OS" for [thing]?](/images/60C2454D-CF3F-437C-BF74-6B1B809C1544)

![Research paper: removing dependencies from large (Java) software projects [pdf]](/images/2A1E6232-BB0E-4179-BD93-CB494D99FE5E)
