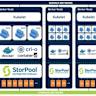
Die rasante Entwicklung im Bereich der Künstlichen Intelligenz hat eine immense Transformation in der Art und Weise bewirkt, wie Unternehmen Daten verarbeiten, Modelle trainieren und KI-Anwendungen implementieren. Dabei ist die Wahl und das Zusammenspiel der darunterliegenden Software-Stacks entscheidend für den Erfolg in puncto Skalierbarkeit, Performance und Benutzerfreundlichkeit. In diesem Kontext hat sich eine Kombination aus bewährten Open-Source-Technologien als Standard herauskristallisiert: Kubernetes, Ray, PyTorch und vLLM. Diese vier Komponenten bilden zusammen einen leistungsstarken und flexiblen Stack, der den modernen Anforderungen an KI-Compute gerecht wird und eine solide Grundlage für die Zukunft der KI-Berechnung bietet. Der Ursprung des Stacks basiert auf den Erfahrungen mit dem Ray Framework, das von Hunderten von KI- und Plattform-Teams weltweit eingesetzt wird, um AI-Workloads produktiv zu machen.
Während AI-Anwendungen früher vorwiegend klassische Machine-Learning-Modelle und kleinere Deep-Learning-Projekte beinhalteten, dominieren heute komplexe generative KI-Modelle, die große Datenmengen in großem Maßstab verarbeiten müssen. Diese rasante Entwicklung hat die Komplexität der Software-Infrastruktur deutlich erhöht und erfordert leistungsfähige, zugleich aber flexible Frameworks. Kubernetes hat sich in den letzten Jahren als das führende Container-Orchestrierungssystem etabliert, das Management und Skalierung von Anwendungen in Container-Umgebungen ermöglicht. Gleichzeitig ist PyTorch das dominante Framework im Deep Learning, das nicht nur dank seiner Flexibilität und Benutzerfreundlichkeit, sondern auch durch stetige Innovation in der Branche punktet. Ray als verteilte Compute-Engine ergänzt Kubernetes und PyTorch perfekt, indem es die Aufgabenverteilung, Datenbewegung und Fehlertoleranz auf Workload-Ebene gewährleistet.
Abgerundet wird der Stack durch vLLM – eine hochspezialisierte Inferenz-Engine, die sich auf effiziente Transformer-basierte Modelle konzentriert und besonders im Bereich der Large Language Models (LLMs) für echte Performancegewinne sorgt. Das Zusammenwirken dieser Komponenten erlaubt es Unternehmen, sowohl Training, Inferenz als auch Batch-Verarbeitung multimodaler Daten in großem Umfang sicher und effizient zu betreiben. Im Kern der Architektur steht die Schichtung der Software. Die unterste Ebene bildet der Container-Orchestrator Kubernetes, dessen Aufgabe es ist, die zugrundeliegenden Compute-Ressourcen bereitzustellen, Container zu starten und zu verwalten sowie Arbeitsspeicher und Rechenleistung auf verschiedene Nutzer und Jobs zu verteilen. Kubernetes gewährleistet dabei Multitenancy, Isolation und eine intelligente Ressourcenplanung.
Es fungiert als Schnittstelle zur Cloud-Infrastruktur und stellt sicher, dass Anfangs- und Nachschubkapazitäten flexibel und automatisiert angepasst werden. Darauf aufbauend sorgt Ray als verteilte Rechner-Engine für die feingranulare Aufteilung von Aufgaben innerhalb eines Jobs, die Datenbewegung zwischen diesen Aufgaben und die Fehlerbehandlung auf Workload-Ebene. Ray ist speziell auf AI-Workloads abgestimmt, unterstützt Python nativ und ist GPU-aware, was für Machine-Learning- und Deep-Learning-Workloads besonders wichtig ist. Seine Fähigkeit, dynamisch zu skalieren, Ausfälle zu kompensieren und Ressourcen intelligent anzupassen, macht es zum perfekten Bindeglied zwischen Container-Orchestrierung und Modell-Execution. Die oberste Schicht im Stack sind Frameworks zur Modell-Definition und Inferenz, hier sind PyTorch und vLLM die Eckpfeiler.
PyTorch ermöglicht das schnelle Erstellen, Trainieren und Evaluieren komplexer neuronaler Netze, unterstützt automatische Differenzierung und bietet vielseitige Parallelisierungsstrategien wie Daten- und Modellparallelismus, kombiniert mit Hardware-naher Optimierung, insbesondere für GPUs. Vorrangig für das Training ist PyTorch unerlässlich, während vLLM sich als Inferenz-Engine speziell auf Transformer-Modelle konzentriert und Techniken wie kontinuierliches Batchen, spezialisierte Speicherverwaltung und effiziente Dekodierung einsetzt, die die Latenz stark reduzieren und die GPU-Auslastung maximieren. Gerade im Zeitalter großer Sprachmodelle stellt vLLM eine erhebliche Verbesserung der Performance bei der Ausführung von Aufgaben wie Chatbots, automatischen Übersetzern oder Moderation sicher. Beispiele aus der Praxis zeigen eindrucksvoll, wie Unternehmen diesen Stack nutzen, um große Herausforderungen im KI-Bereich zu meistern. Pinterest berichtet von drastischen Verbesserungen in der Datenverarbeitung und Trainingsgeschwindigkeit, mit einer Verkürzung der Dateniterationszeit von 90 auf 15 Stunden und einer gleichzeitigen Steigerung der GPU-Auslastung auf über 90 Prozent.
Auch die Kosten bei der Batch-Inferenz konnten um das 30-fache reduziert werden. Uber hat mit seinem Michelangelo-Framework seine Trainings- und Inferenz-Plattform kontinuierlich weiterentwickelt und nutzt Kubernetes, Ray und PyTorch, um selbst die größten Modelle mit 70 Milliarden Parametern zu handhaben und den Durchsatz signifikant zu erhöhen. Roblox, ein weiterer Tech-Gigant, hat sich von einem Kubeflow- und Spark-zentrierten Ansatz hin zu einem Kubernetes-basierenden Hybrid-Modell mit Ray und vLLM entwickelt. Das Ergebnis sind signifikante Steigerungen bei der GPU-Auslastung, Kosteneinsparungen und eine Auflösung von typischen Engpässen bei Multimodalität und Batch-Inferenz. Neben diesen Industrieanwendungen gibt es einen wachsenden Bereich, der als Post-Training bezeichnet wird.
Hierbei handelt es sich vor allem um Verfahren des Reinforcement Learnings, die eine Kombination aus Modelltraining und -inferenz benötigen, oftmals eingebettet in simulationsbasierte oder agentenorientierte Umgebungen. Fünf der wichtigsten Open-Source-Post-Training-Frameworks basieren auf einem ähnlichen Stack aus Kubernetes und SLURM (für die Container-Orchestrierung), Ray (für das Distributed Computing) sowie PyTorch und vLLM als Frameworks für Training und Inferenz. Diese Frameworks adressieren äußerst komplexe Herausforderungen, die mit der Verbindung von Trainings- und Inferenzprozessen verbunden sind, und zeigen, wie flexibel und leistungsstark der beschriebene Stack ist. Die Kombination aus Kubernetes, Ray, PyTorch und vLLM bietet zahlreiche Vorteile: Sie garantiert eine hochautomatisierte, skalierbare Infrastruktur für KI-Anwendungen, die sowohl mit der Geschwindigkeit neuer Ideen und Modelle als auch mit dem Bedarf an Kosteneffizienz und Zuverlässigkeit Schritt hält. Der Stack unterstützt zudem heterogene Ressourcen, erleichtert Multitenancy und beschleunigt den Entwicklungszyklus für KI-Teams erheblich.
Für Unternehmen bedeutet das eine verlässliche Basis für kontinuierliches Wachstum und Innovation im KI-Bereich. Daraus ergibt sich, dass sich moderne AI-Compute-Stacks nicht mehr auf einzelne Technologien stützen, sondern auf die Integration etablierter, bewährter Open-Source-Tools, die ihre jeweilige Stärke ausspielen. Kubernetes übernimmt das harte Infrastruktur-Management und Resource-Provisioning, Ray garantiert reibungslose, ausfallsichere und effiziente Task-Verarbeitung innerhalb von Workloads, und PyTorch zusammen mit vLLM setzen moderne, optimierte Deep-Learning-Modelle performant um. Für die Zukunft sind diese Technologien gut gerüstet, um neue Hardware-Innovationen, veränderte Workload-Typen und neue KI-Methoden problemlos zu integrieren und anzupassen. Dies macht sie zur bevorzugten Wahl für alle Unternehmen, die ihre KI-Infrastruktur zukunftssicher aufbauen und erweitern möchten.
Schlussendlich zeigt sich, dass die Wahl der richtigen Software-Stack-Kombination ein wesentlicher Faktor für den Erfolg der KI-Einführung ist. Die Kombination aus Kubernetes, Ray, PyTorch und vLLM hat sich hierbei sowohl in der Theorie als auch in der Praxis als robust und innovativ erwiesen. Sie adressiert die komplexen Anforderungen der heutigen AI-Landschaft und ermöglicht eine flexible, leistungsstarke und kosteneffiziente Umsetzung von KI-Anwendungen in großem Maßstab. Unternehmen, die diese Technologien nutzen, sichern sich damit eine hochmoderne Plattform, die Innovationen beschleunigt und Wettbewerbsvorteile in einem dynamischen Marktumfeld schafft.