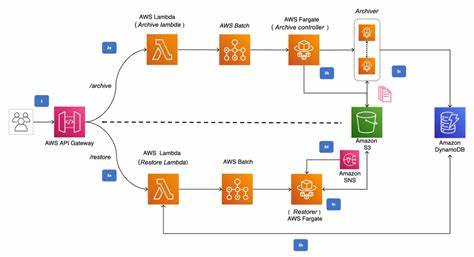
Die Cloud verändert die Art und Weise, wie Unternehmen Daten speichern und verarbeiten. Besonders Amazon S3 hat sich als objektbasierter Cloud-Speicher weltweit etabliert. Seine scheinbar unbegrenzte Skalierung, Kosteneffizienz und Zuverlässigkeit machen S3 attraktiv für viele Anwendungen. Doch sobald der Wunsch aufkommt, S3 als primären Speicher für eine performante Streaming-Datenbank zu nutzen, zeigen sich erhebliche Herausforderungen: Die hohe Latenz von S3, das Fehlen traditioneller Dateisystem-Funktionalitäten und die Kosten für API-Zugriffe machen den Einsatz komplex. RisingWave hat sich dieser Herausforderung angenommen und eine Architektur entwickelt, die S3 nicht nur als Backup-Lösung, sondern als Heimat der gesamten Persistenz nutzt.
Das Ergebnis ist ein verteiltes Streaming-System mit Eigenschaften einer In-Memory-Datenbank, aber mit Cloud-Ökonomie und Skalierbarkeit. Viele Entwickler unterschätzen die Unterschiede zwischen klassischen lokal gebundenen Speichern wie Festplatten oder SSDs und S3 als objektbasiertem Speicher. S3 ist nicht einfach nur ein fernes Dateisystem. Es sieht Daten als unveränderliche Objekte. Operationen wie das Anhängen an Dateien, zufälliger Zugriff oder inkrementelle Updates sind nicht möglich.
Zudem bietet S3 nur eine sogenannte eventual consistency für normale Schreiboperationen, was bedeutet, dass Änderungen mit Verzögerung sichtbar werden können. Diese Tatsache allein macht viele bestehende Systeme, die auf synchrone Disk-Operationen setzen, für S3 ungeeignet. RisingWave hat deshalb seine gesamte State- und Speicherarchitektur von Anfang an auf S3 als Hauptspeicher konzipiert. Die internen Zustände, Operator-Ergebnisse, Materialisierte Views und Logs werden als unveränderliche Objekte in S3 abgelegt. Parallel dazu verwaltet eine PostgreSQL-Datenbank das Metadaten-Katalog, der den Überblick über Versionen, Objektorte und Epochs behält.
Diese Entkopplung ermöglicht stateless compute nodes, die sich jederzeit von S3 rekonstruieren können, was Ausfallsicherheit und Elastizität fördert. Die größte Hürde bei der Nutzung von S3 als Hauptspeicher ist die Latenz. Typischerweise können 100 bis 300 Millisekunden bis zur ersten Byte-Auslieferung anfallen, was in einem Streaming-System, das auf zehntausende von Operationen pro Sekunde angewiesen ist, eine Ausbremsung bedeutet. Ein direkter Zugriff auf S3 für jeden Zustandszugriff würde das System unweigerlich in die Knie zwingen. Der Schlüssel liegt deshalb in einer geschichteten Speicherarchitektur, die S3 für dauerhafte Speicherung nutzt, aber häufig genutzte Daten lokal im Speicher oder auf schnellerer Disk zwischenspeichert.
RisingWave hat mit einer Kombination aus Speicherhierarchie gearbeitet, bei der RAM für sehr schnelle Zugriffe, NVMe SSDs oder EBS als Zwischencache und S3 als permanenten Speicher dienen. Insbesondere der Einsatz von EBS bringt hier Vorteile hervor, weil es eine flexible Größenanpassung erlaubt und auf allen Cloud-Anbietern verfügbar ist. EBS kann mit der richtigen Provisionierung in Leistung und Latenz lokalem SSD in vielen Fällen nahekommen und dabei signifikante Flexibilität bei der Ausstattung bieten. Zusätzlich betreibt RisingWave eine intelligente Cache-Schicht namens Foyer, die auf der Zwischendisk-Ebene arbeitet. Diese Komponente kontrolliert das Caching-Management, überwacht Telemetriedaten und interagiert eng mit dem Query-Engine-System, um sicherzustellen, dass häufig genutzte Daten bestmöglich im schnellen Zwischenspeicher vorgehalten werden.
Das Zusammenwirken zwischen Speicherhierarchie und Cache-Strategien sorgt dafür, dass S3-Anfragen im heißen Pfad der Abfragen fast nie direkt stattfinden und die Performance auf dem Niveau von In-Memory-Systemen liegt. RisingWave nutzt darüber hinaus ein Remotekompaktions-Verfahren, um die Speicherstrukturen auf S3 und der Zwischendisk kontinuierlich zu reorganisieren. Konventionelle lokale Kompaktionen, bekannt aus Systemen wie RocksDB, binden Rechen- und IO-Ressourcen auf dem selben Knoten, der Benutzerabfragen bedient, was zu Leistungseinbußen und Stottern im Stream führen kann. Mit Remote-Kompaktoren werden diese Arbeiten aus dem Abfragepfad ausgelagert. Spezielle Worker ziehen die Daten von S3, organisieren und verdichten sie und schreiben sie zurück, ohne die Front-End-Knoten zu belasten.
Im Cloud-Betrieb wird Kompaktion als serverloses Pooling angeboten, das automatisch skaliert und mehrfachen Mandanten effizient dient. Diese Architektur ermöglicht es, das System stabil und performant zu halten, selbst bei ungleichmäßiger oder hoher Last. Eine weitere wichtige Optimierung betrifft die Kosten und Performance bei S3-Zugriffen. Amazon S3 verrechnet nicht nur nach Speicherplatz, sondern auch nach Anzahl und Art der API-Calls. Kleine, häufige Lese- oder Schreibanfragen können so unerwartet hohe Kosten verursachen.
RisingWave begegnet dem mit größeren blockbasierten Leseeinheiten, die ca. vier Megabyte groß sind. Dieses Blockpacking reduziert die Anzahl der API-Calls drastisch. Zudem werden Sparse-Indizes genutzt, die aus Speicher oder SSD geladen werden, um genau die Datenblöcke herauszufiltern, die für eine Abfrage relevant sind. Ein intelligentes Prefetching auf Basis der Abfrageplanung erlaubt es, Daten parallel zu laden und Wartezeiten zu minimieren.
In der Praxis reduziert das System damit API-Roundtrips zu S3 um bis zu 90 Prozent, was sowohl Kosten als auch Latenzen deutlich senkt. Die Anforderungen an Echtzeit-Datenverarbeitung verlangen einen hohen Grad an Konsistenz und Frische der Daten. Nutzer sind heute nicht bereit, verzögerte Ergebnisse zu akzeptieren. RisingWave setzt daher auf eine Architektur mit einer wirklichen Read-after-Write-Konsistenz. Jede neue Schreiboperation löst unmittelbar eine Aktualisierung und Invalidierung sämtlicher Caches aus.
Materialisierte Views werden inkrementell aktualisiert ohne Komplettneu-Berechnungen, die Latenz zwischen Datenänderung und Abfrageergebnis liegt im Sekundenbereich. Diese Echtzeit-Konsistenz wird möglich durch koordinierte Events und durch aggressive Cache-Management-Strategien auf allen Speicherstufen. Multi-Tenancy ist in einem cloudbasierten Ökosystem meist eine komplexe Herausforderung. Klassische Systeme isolieren Mandanten oft durch separat betriebene Cluster, was teuer und schwer skalierbar ist. Durch das Nutzen von S3 als gemeinsamen persistenten Speicher kann RisingWave eine klare Trennung auf der logischen Ebene realisieren, jedoch physisch alle Mandanten in einem gemeinsamen Objektstore betreiben.
Das entkoppelt den Speicherbedarf vom jeweiligen Knoten und vermeidet Überbuchungen oder Ressourcenkonflikte. Die Ausführungsschicht erzwingt per Query CPU und Speicherquoten und steuert die I/O-Budgetierung, um einzelne „laute“ Mandanten einzubremsen ohne das Gesamtsystem zu gefährden. Gleichzeitig ist ein gemeinsames Metadaten-Repository verfügbar, sodass zusammenarbeitende Teams effizient an denselben Datenströmen und Views arbeiten können, ohne redundante Datensätze anlegen zu müssen. Ein besonderes Feature, das zukünftiges Potenzial birgt, ist das Peer-to-Peer Cache Hydration. Dabei würden einzelne Knoten ihre frisch geladenen oder berechneten Daten direkt anderen Knoten zur Verfügung stellen.
Dieses Prinzip entspricht einem innerbetrieblichen CDN und könnte die Last auf S3 noch weiter reduzieren sowie Latenzen minimieren. Dieses Konzept reiht sich in moderne Ansätze ein, die zunehmend Distributed Systems und Edge-Caching nutzen. Zusammenfassend zeigt das Beispiel von RisingWave: Die Nutzung von S3 als primären Speicher für ein Streaming-System ist keine triviale Aufgabe. Es erfordert ein radikales Umdenken bezüglich Speicher- und Zustandsverwaltung, Cache-Strategien, Konsistenzmanagement und Ressourcenzuteilung. Die Kombination aus einer durchdachten Speicherhierarchie, intelligentem Caching, Remote-Kompaktion und einem stark auf Objektstore optimierten Zugriff führt zu einem System, das die Agilität und Kostenvorteile von Cloud-Objektspeichern mit der Performance eines In-Memory-Datenbank-Systems verbindet.
Die Vorteile sind enorm: Mandanten können einfach und sicher nebeneinander betrieben werden, Knoten können blitzschnell ausgefallen werden ohne Datenverlust, Skalierung über Regionen und Cloud-Anbieter hinweg ist naturgegeben und hohe Verfügbarkeit ist gewährleistet. Am wichtigsten aber: Trotz aller Cloud-Charakteristika fühlt sich das System für Entwickler und Nutzer performant und schnell an – als ob es vollständig im RAM laufen würde. Für Unternehmen, die ihre Streaming-Dateninfrastruktur auf den nächsten Stand bringen möchten und dabei Flexibilität, Skalierbarkeit und Wirtschaftlichkeit suchen, ist dieses Modell eine faszinierende Alternative zu klassischen Architekturen. Indem man Speicher, Rechenleistung und Koordination entkoppelt und von Anfang an auf Cloud-Native Prinzipien setzt, erschließt sich ein Weg in die Zukunft der Datenverarbeitung.