Die Welt der Datenanalyse und des Data Engineering ist geprägt von ständig wachsender Komplexität und immer größeren Datenmengen. Werkzeuge wie DBT (Data Build Tool) haben sich in diesem Umfeld zu unverzichtbaren Helfern entwickelt, um Datenpipelines zu verwalten, Transformationen vorzunehmen und den Überblick über komplexe SQL-Modelle zu behalten. Trotz ihrer Relevanz stellen DBT-Projekte jedoch häufig eine Herausforderung für diejenigen dar, die nicht tief in der technischen Datenverarbeitung stecken: Analysten, Produktmanager und auch neue Mitglieder in Teams kämpfen häufig damit, die vielfältigen Zusammenhänge und Details der Modelle zu verstehen. Ein Open-Source-Projekt mit dem Namen „DBT to English“ adressiert genau dieses Problem und nutzt dabei die Möglichkeiten moderner großer Sprachmodelle (Large Language Models, LLMs), um automatisch verständliche und kontextreiche Dokumentationen zu erzeugen. DBT ist zweifelsohne eine der führenden Plattformen im Bereich des analytischen Daten-Engineerings.
Mit DBT können Entwickler SQL-basierte Modelle erstellen und diese orchestrieren, um komplexe Datenpipelines abzubilden. Das Werkzeug strukturiert Transformationslogik und definiert Abhängigkeiten zwischen Modellen in einem übersichtlichen Framework. Dennoch sind die SQL-Skripte manchmal schwer nachvollziehbar, besonders wenn sie viele verschachtelte Berechnungen oder CTEs (Common Table Expressions) enthalten. Die mitgelieferte Dokumentation, etwa die DBT Docs, ist zwar hilfreich, bietet aber nur eine begrenzte Einsicht in die einzelnen Berechnungsschritte oder die genaue Funktionsweise der Modelle. Hier kommt „DBT to English“ ins Spiel, ein Projekt, das innovative Technik mit praxisnaher Lösung vereint.
Die Grundlage der neuen Dokumentationsmethode bildet der Einsatz von KI-Modellen, die in der Lage sind, komplexe technische Inhalte in einfache und verständliche Sprache zu übersetzen. In „DBT to English“ können Entwickler ihre DBT-Projektdateien hochladen, insbesondere die manifest.json und catalog.json, die alle notwendigen Metadaten und Transformationen speichern. Anschließend analysiert das System diese Daten und erzeugt eine klar verständliche Erklärung des jeweiligen Modells – ohne dabei auf die originale SQL-Syntax zurückzugreifen und so auch Nicht-Programmierern den Zugang zu erleichtern.
Ein besonderer Vorteil des Tools ist die flexible Nutzung verschiedener großer Sprachmodelle, wie zum Beispiel jene von Anthropic oder Amazons Bedrock, wodurch Nutzer ihre bevorzugte Technologie einsetzen können. Darüber hinaus ermöglicht die offene Architektur und Konfigurierbarkeit den Teams, das Antwortverhalten und die Darstellung der Dokumentation an ihre individuellen Bedürfnisse anzupassen. So kann der Stil der Erklärung verändert oder zusätzliche Informationen eingebunden werden, je nachdem, was für das jeweilige Unternehmen oder Team relevant ist. Die Benutzeroberfläche des Tools ist benutzerfreundlich gestaltet und basiert auf Streamlit, einem Framework für schnelle Webanwendungen. Nach dem Einrichten des Systems über Docker öffnet sich eine übersichtliche Weboberfläche, in welcher Nutzer die spezifischen Projektdateien laden und auswählen können, welche Modelle sie näher beleuchten möchten.
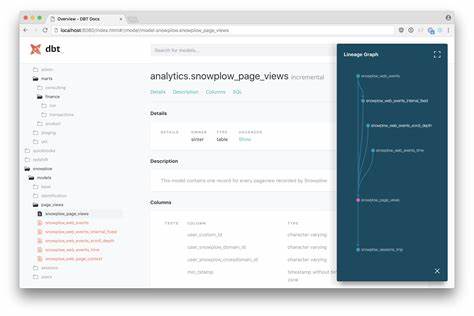
Nach wenigen Klicks generiert das System dann eine mehrstufige Darstellung: Zunächst eine narrative Beschreibung des Modells in alltäglicher Sprache, dann eine interaktive Grafik, die nicht nur die Abhängigkeiten zwischen Hauptmodellen darstellt, sondern auch interne Strukturen wie CTEs oder Zwischenschritte visualisiert – etwas, das über die üblichen DBT-Dokumentationen hinausgeht. Diese Visualisierung stärkt das Verständnis enorm, da Abhängigkeiten und Beziehungen transparent werden. Außerdem gibt es eine detaillierte Aufschlüsselung der zugrundeliegenden SQL-Logik und der Berechnungen je Spalte, was besonders bei der Wartung und Weiterentwicklung der Datenmodelle von großem Vorteil ist. Zusätzlich werden Abhängigkeiten in einem separaten Abschnitt zusammengefasst, inklusive kurzer Erklärungen, welche Rolle diese Quellen und Modelle im gesamten Datenfluss spielen. Dass die Dokumentationen durch die großen Sprachmodelle automatisch erzeugt werden, bietet neben einer erheblichen Zeitersparnis auch eine einheitliche Qualität und Verständlichkeit.
Teams müssen sich nicht mehr auf individuell unterschiedlich ausgeprägte Kommentare in SQL-Quellcodes verlassen, sondern verfügen über eine stets aktuelle und konsistente Erklärung ihrer Datenpipelines. Besonders in wachsenden Teams oder Unternehmen mit häufig wechselnden Ressourcen bietet dies eine klare Verbesserung der Wissenshaltung und Kommunikation. Die Open-Source-Natur des Projekts lädt dabei zur aktiven Beteiligung aus der Community ein. Entwickler können das Tool weiterentwickeln, neue Features integrieren, weitere Modelle und Anbieter von Sprach-KI unterstützen oder die Benutzeroberfläche optimieren. Durch diesen kollaborativen Ansatz verspricht die Lösung langfristig immer besser auf die Bedürfnisse der Nutzer abgestimmt zu werden und aktuelle technologische Innovationen zu integrieren.
Neben der technischen Seite adressiert „DBT to English“ auch einen wichtigen kulturellen Wandel im Data Engineering: Die Demokratisierung von Datenwissen. Wo früher nur wenige Spezialisten Detailwissen über Pipelines und Modelle hatten, wird nun Wissen geteilt und verständlich gemacht – eine entscheidende Voraussetzung für agilere Entwicklungsprozesse und datengetriebene Entscheidungen auf allen Ebenen einer Organisation. In einer Zeit, in der Data Engineering und Analytics einen immer strategischeren Stellenwert einnehmen, sind Werkzeuge, die Komplexität reduzieren und Transparenz schaffen, von unschätzbarem Wert. Die Kombination aus bewährter Datenmodellierung mit DBT und der assistierenden Intelligenz großer Sprachmodelle öffnet neue Möglichkeiten, die eigene Datenwelt besser zu verstehen und effizienter zu nutzen. Interessierte können das Projekt über GitHub beziehen und sofort damit experimentieren oder sich an der Weiterentwicklung beteiligen.
Die einfache lokale Installation über Docker und die intuitive Benutzeroberfläche ermöglichen es Anwendern unterschiedlichster Erfahrungsstufen, von der Technologie zu profitieren. Zusammenfassend steht „DBT to English“ exemplarisch für den Fortschritt im Bereich automatisierter Dokumentation und Wissensmanagement im Data Engineering. Durch die kreative Nutzung von Künstlicher Intelligenz wird das traditionelle Problem der mangelnden Verständlichkeit von SQL-Transformationslogik elegant gelöst. Zukunftsweisend zeigt das Projekt, wie offene Zusammenarbeit und innovative Technologien Hand in Hand gehen können, um Arbeitsprozesse zu verbessern und Wissen zugänglicher zu machen – ein Meilenstein auf dem Weg zur datengetriebenen Organisation.