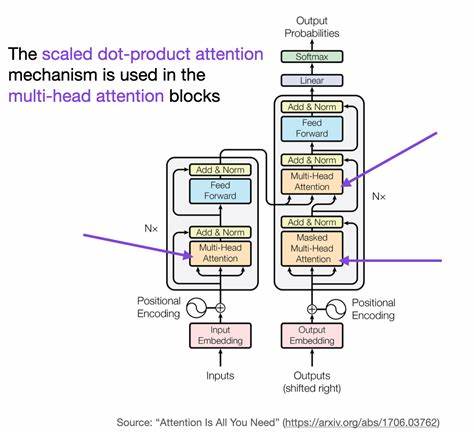
In der Welt der künstlichen Intelligenz stellen große Sprachmodelle (Large Language Models, LLMs) einen bedeutenden Fortschritt im Verständnis und der Erzeugung natürlicher Sprache dar. Die Fähigkeit solcher Modelle, längere und zusammenhängendere Texte zu verarbeiten, hat sich in den letzten Jahren deutlich verbessert. Ein zentrales Element dabei ist die Self-Attention, ein Mechanismus, der es einem Modell ermöglicht, den Zusammenhang zwischen Tokens oder Wörtern über einen gegebenen Kontext hinweg zu berücksichtigen. Doch mit wachsender Kontextlänge steigen auch die Herausforderungen – sowohl im Hinblick auf Speicherbedarf als auch auf Rechenzeit. Die Komplexität von Self-Attention im Hinblick auf die Skalierung ist deshalb ein entscheidender Faktor für die Weiterentwicklung leistungsfähiger LLMs.
Self-Attention als Kernmechanismus großer Sprachmodelle ist entscheidend für die Verarbeitung von Eingabesequenzen. Dabei wird für jedes Token im Eingabetext eine Art Fokus auf alle anderen Tokens gelegt, um wichtige Abhängigkeiten zu erfassen. Mathematisch manifestiert sich dieser Mechanismus in einem Aufmerksamkeitsscore, der für jeden einzelnen Token-Paar ermittelt wird. Diese Werte ergeben eine Aufmerksamkeitsmatrix, deren Größe quadratisch mit der Länge der Eingabesequenz wächst – das heißt, bei einer Sequenzlänge von n Tokens kommt es zu n² Berechnungen und Speicheranforderungen. Dabei macht es keinen wesentlichen Unterschied, ob nur Teile dieser Matrix verwendet werden; auch mit effizienteren Speicherverfahren bleibt die zugrundeliegende Komplexität in der Größenordnung von O(n²).
Warum ist das relevant? Zu Beginn waren Sprachmodelle wie ChatGPT mit Kontextlängen im niedrigen Tausenderbereich üblich. Für diese Moderatgröße sind die quadratischen Anforderungen beim Rechnen und Lagern der Aufmerksamkeitsmatrix noch relativ gut bewältigbar. Doch moderne Modelle gehen weit darüber hinaus. GPT-4.1 von OpenAI arbeitet beispielsweise mit mehr als einer Million Tokens als Kontextfenster, und Googles Gemini 1.
5 Pro verdoppelt diese Zahl sogar. Ein solcher Sprung bedeutet rein rechnerisch einen Anstieg im Speicherbedarf um Millionenfach – aus Megabyte werden Terabyte. Selbst modernste, teure GPUs stoßen bei der Verarbeitung solcher Datenmengen an ihre Grenzen, was die nahtlose Anwendung langer Kontexte zu einer enormen Herausforderung macht. Neben dem Speicherverbrauch nimmt auch die Rechenzeit exponentiell zu. Die Aufmerksamkeitsmatrix entsteht durch die Multiplikation von Quer- und Schlüssel-Matrizen (Querys und Keys), gefolgt von Softmax-Berechnungen und der Anwendung auf die Werte-Matrix.
Alle relevanten Operationen skalieren mindestens quadratisch mit der Sequenzlänge. Ein einfaches Beispiel verdeutlicht das Dilemma: Wenn ein Modell mit 1000 Tokens Kontext pro Token 0,1 Sekunden Rechenzeit benötigt, würde ein Modell, das eine Million Tokens verarbeitet, theoretisch 100.000 Sekunden, also ungefähr 28 Stunden, allein für einen Token benötigen. Eine solche Verlangsamung ist für interaktive Anwendungen, bei denen schnelle Antwortzeiten wichtig sind, völlig inakzeptabel. Es sind jedoch nicht nur Ressourcenfragen, die durch den quadratischen Faktor erschwert werden.
Ein weiterer Punkt, der häufig diskutiert wird, ist die Relevanz der Abhängigkeiten über extrem weite Kontexte hinweg. Ist es sinnvoll, dass ein Token am Ende eines Textdokumentes in einem Self-Attention-Modell sämtliche Tokens, die eine Million Stellen zuvor erscheinen, mit gleich hoher Aufmerksamkeit verarbeitet? Für ein gutes Textverständnis ist das nicht notwendig und sogar kontraproduktiv. In der Praxis suchen Modelle und Entwickler nach effizienten Strukturen, die nahegelegene Kontextbereiche bevorzugen und nur selektiv Informationen aus weiter entfernten Teilen einbeziehen. Dies spiegelt auch das menschliche Leseverhalten wider, denn auch wenn wir beim Lesen eines Romans zurückblättern können, tun wir dies meist gezielt und nicht dauerhaft über den ganzen Text hinweg. Angesichts dieser Herausforderungen wurden mehrere Ansätze erforscht und entwickelt, um Self-Attention in großen Modellen zu skalieren, ohne dem Speicher- und Rechen-Flaschenhals zu erliegen.
Eine vielversprechende Richtung sind sparsames oder lokales Attention-Mechanismen, die nur ausgewählte Bereiche des Kontextes berücksichtigen, beispielsweise durch Fensterung oder hierarchische Zusammenfassungen. Solche Techniken reduzieren effektiv die Menge der zu verarbeitenden Beziehungen auf eine lineare, oder zumindest sub-quadratische, Größenordnung. Darüber hinaus erfreuen sich auch Methoden großer Beliebtheit, die außerhalb des Modells agieren. So arbeitet beispielsweise eine Technik namens Retrieval-Augmented Generation (RAG) mit externen Wissensspeichern. Dabei werden relevante Ausschnitte des Kontextes dynamisch ermittelt und in das eigentliche Kontextfenster eingebracht, wodurch das Modell nur auf ausgewählte und prägnante Informationen zugreift.
Auch Zusammenfassungsmechanismen, bei denen längere Gesprächs- oder Textverläufe in kompakter Form gespeichert und fortgeführt werden, tragen zur Reduktion der benötigten Verarbeitungslast bei. Neben algorithmischen Ansätzen spielt auch Hardwarebeschleunigung eine Rolle. Moderne GPUs und spezialisierte Beschleuniger können Matrixoperationen massiv parallelisieren. Technologien wie FlashAttention optimieren den Speicherzugriff und die Berechnung der Aufmerksamkeitsmatrix aus hardware-naher Sicht, erreichen dabei teils erheblichen Linearitätsvorteil bei der Laufzeit, behalten aber den quadratischen Speicherbedarf bei. Damit schaffen sie es, LLMs mit langen Kontexten auf aktuellen Systemen performant auszuführen – aber die grundsätzliche Herausforderung der O(n²)-Skalierung bleibt bestehen.
Eine einfache Lösung, wie sie manchmal in kleinen Lehrbeispielen gezeichnet wird, nämlich die sequentielle Berechnung von Token-Aufmerksamkeiten statt parallel, würde zwar viel Speicher sparen und den Platzbedarf linear gestalten. Die Rechenzeit würde jedoch unverändert bleiben, da jeder Berechnungsschritt eine lineare Zeit beansprucht und n solche Schritte benötigt werden. Zudem führt das vollständige Fehlen von Parallelisierung zu erheblichen Performanceeinbußen, die in der Praxis kaum akzeptabel sind. Der Umgang mit den Problemen der Self-Attention-Komplexität ist also ein Kernfaktor bei der Entwicklung effizienter, leistungsstarker, skalierbarer Sprachmodelle. Die Balance zwischen Modell-Performance, Kontextlänge, Ressourcenverbrauch und Geschwindigkeit prägt die Forschungs- und Produktentwicklung in diesem Feld entscheidend.
Interessanterweise reflektieren die aktuellen technischen Diskussionen in den LLM-Communities die Notwendigkeit, nicht nur auf reine Performance zu achten, sondern auch auf die praktische Anwendbarkeit und das Verständnis der inneren Mechanismen. Die Vorstellung, dass es sinnvoll ist, jeden Token mit allen anderen unabhängig von der Entfernung gleichberechtigt interagieren zu lassen, wird hinterfragt. Stattdessen gewinnt die Idee an Bedeutung, dass Modelle Hierarchien oder Zusammenfassungsmechanismen lernen oder vorgegeben bekommen, um so den Kontext effektiv zu verdichten und relevante Informationen herauszufiltern. Zusammengefasst lässt sich festhalten, dass die Skalierung von Self-Attention die Quadratik der Datenmengen und Berechnungen mit sich bringt, was ohne geeignete Optimierungen die praktische Nutzung bei enormen Kontextlängen schlichtweg verhindert. Innovative Ansätze – sei es im Algorithmusdesign, in der Hardwareoptimierung oder der cleveren Strukturierung des Kontextzugriffs – sind also ausschlaggebend für den künftigen Erfolg großer Sprachmodelle.
Nur so lassen sich die beeindruckenden Fortschritte in der Verständlichkeit und Verlässlichkeit großer KI-Systeme mit realistischen Laufzeiten und Ressourcenanforderungen verbinden. Die Erforschung und das Verständnis dieser Komplexitätsproblematik bleiben eine spannende und zentrale Herausforderung für die KI-Forschung und das Engineering. Wer sich mit der Entwicklung eigener LLMs beschäftigt, sollte diese Aspekte gründlich kennen, um fundierte Entscheidungen beim Design von Modellen und Systemen treffen zu können. Dabei wird die Balance zwischen theoretischer Eleganz und praktischer Umsetzbarkeit oftmals über Erfolg oder Misserfolg ganzer Projekte entscheiden. Abschließend lässt sich sagen, dass die Self-Attention ein faszinierendes und gleichzeitig herausforderndes Prinzip ist.
Trotz seiner hohen Komplexität ermöglicht es Sprachmodellen, Kontexte dynamisch und differenziert zu erfassen und zu nutzen. Die künftigen Entwicklungen werden zeigen, wie die Forschung diese Komplexität in den Griff bekommt, um Modelle mit immer größeren und sinnvolleren Kontexten zu realisieren – und damit auch in der Praxis noch smartere, effektivere KI-Anwendungen entstehen zu lassen.