Große Sprachmodelle (LLMs) haben die Art und Weise, wie Softwareentwicklung gestaltet wird, grundlegend verändert. Durch ihre Fähigkeit, Code zu generieren, Fehler zu erkennen und komplexe Entwicklungsprobleme zu lösen, sind sie heute unverzichtbare Werkzeuge für Entwickler und Organisationen weltweit. Doch mit der steigenden Bedeutung dieser Modelle wächst auch der Bedarf an robusten, zuverlässigen und fairen Bewertungssystemen, die ihre tatsächlichen Fähigkeiten präzise messen. Hier setzt SWE-Rebench an – ein innovatives Benchmark, das speziell für Software-Engineering-LLMs entwickelt wurde und darauf abzielt, die Grenzen bisheriger Evaluationsverfahren zu überwinden. SWE-Rebench bietet eine dynamische, kontinuierlich aktualisierte und datensaubere Bewertung, die neue Standards in der Beurteilung von KI-Modellen im Softwareengineering setzt.
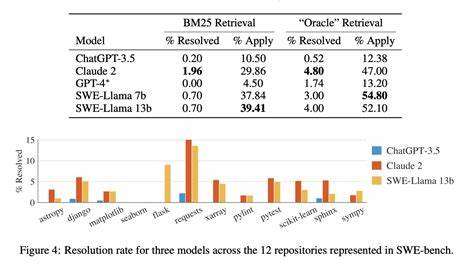
Die Herausforderungen im Bereich der Bewertung von Software-Engineering-Sprachmodellen sind vielfältig. Bei herkömmlichen Benchmarks, wie etwa SWE-bench, die eine Sammlung von GitHub-Issues als Testbasis verwenden, zeigen sich immer wieder Probleme wie Datenkontamination, eine nicht einheitliche Testumgebung und eine unzureichende Reproduzierbarkeit der Ergebnisse. SWE-bench hat zwar eine wichtige Pionierrolle übernommen und wertvolle Einblicke darin geboten, wie Sprachmodelle reale Entwicklungsprobleme bearbeiten können, leidet aber unter seiner statischen Datenbasis und der variablen Auswertungsmethodik. Diese Faktoren führen dazu, dass die Messergebnisse verfälscht oder nur schwer vergleichbar sind und den Fortschritt unterschiedlicher Modelle nicht adäquat widerspiegeln. Datenkontamination ist eines der gravierendsten Probleme traditioneller Benchmarks.
Wenn ein Modell Teile der Testdaten bereits in seiner Trainingsphase gesehen hat, kann es Ergebnisse erzielen, die nicht die tatsächliche Leistungsfähigkeit widerspiegeln, sondern auf bloßem Memorieren basieren. Da die ursprünglich verwendeten GitHub-Issues seit Ende 2023 öffentlich zugänglich sind, besteht für alle nach diesem Zeitpunkt veröffentlichten Modelle das Risiko, auf diese Daten zuzugreifen. SWE-Rebench begegnet diesem Problem durch eine fortlaufende Sammlung neuer Aufgaben aus aktiven Open-Source-Projekten, die algorithmisch gefiltert und aufbereitet werden. Dabei werden Erstellungsdaten der Issues und Pull Requests genau mit den Veröffentlichungsdaten der Modelle abgeglichen, um potenziell kontaminierte Evaluierungen transparent zu markieren. So wird sichergestellt, dass die Bewertungen den echten Lernfortschritt widerspiegeln und nicht durch Vorwissen verzerrt sind.
Neben der Datenqualität ist die Einheitlichkeit der Evaluationsumgebung für einen fairen Vergleich von zentraler Bedeutung. Während bei SWE-bench häufig unterschiedlichste „Scaffoldings“ – also Evaluationsrahmenwerke mit individuellen Prompts, Multi-Agenten-Systemen oder komplexen Sampling-Strategien – zum Einsatz kommen, setzt SWE-Rebench auf eine stark standardisierte Infrastruktur. Jeder getestete Sprachmodellagent wird mit dem gleichen minimalen ReAct-Framework geprüft. Dieses Agentensystem kombiniert logisches Denken und Aktionen in einem einheitlichen Ablauf, der von den Entwicklern der Modelle empfohlen wird. Zudem sind für alle Tests identische Prompts und standardisierte Parametereinstellungen bindend.
Die Kontextlänge wird dabei auf großzügige 128.000 Tokens festgelegt, soweit das Modell dies unterstützt. Dieses Vorgehen nimmt dem Benchmark subjektive Tuningeffekte und verhindert eine Überanpassung an bestimmte Testszenarien, die bei SWE-bench häufig beobachtet wurde. So legt SWE-Rebench den Fokus ganz bewusst auf die reinen Fähigkeiten der Modelle, komplexe Softwareprobleme zu verstehen, zu planen, korrekt zu lösen und validierbar zu machen. Die Evaluierungsprozesse sind zudem in SWE-Rebench strikt zentralisiert.
Anstatt dass verschiedene Entwicklerteams oder Organisationen eigene Tests durchführen und Ergebnisse berichten, erfolgen alle Bewertungen durch ein festes Team mit vorgegebenen Methoden und Werkzeugen. Dieses Vorgehen erhöht sowohl die Vergleichbarkeit als auch die Transparenz der Resultate. Die verwendeten Systemprompts sind zudem öffentlich verfügbar, womit die gesamte Community nachvollziehen kann, wie die Modellinteraktion strukturiert ist. Ferner wird festgelegt, dass jedes Modell fünf Mal auf dem gesamten Benchmark ausgeführt wird, um die inhärente Variabilität stochastischer Agentläufe statistisch abzubilden. Dabei werden sowohl der Durchschnittswert als auch der Standardfehler der Mittelwerte sowie pass@5 Metriken veröffentlicht, was eine belastbare und reproduzierbare Ergebnisanalyse ermöglicht.
Die fortlaufende Aktualisierung des Benchmark ist ein weiteres zentrales Merkmal. Die Pipeline zur Sammlung der Software-Engineering-Probleme arbeitet automatisch und erhält kontinuierlich frische Aufgaben aus der aktiven Open-Source-Entwicklergemeinschaft. Dadurch bleibt SWE-Rebench stets aktuell, deckt die neuesten Arten von Problemen ab und verhindert eine statische „Einmalaufnahme“ des Entwicklungswesens. Zwar ist die Bevölkerung der Aufgaben dadurch heterogener und teils schwieriger zu lösen als bei manuell kuratierten sets wie SWE-bench Verified, doch arbeitet das SWE-Rebench-Team an einer laufenden Verbesserung der Filtermechanismen, um Qualität und Lösbarkeit der Aufgaben zu optimieren. Diese Vorgehensweise garantiert langfristig eine realistische und herausfordernde Testgrundlage für Modelle aller Leistungsstufen.
Was bedeutet das für Entwickler, Forscher und Unternehmen, die auf Software-Engineering-LLMs setzen oder diese weiterentwickeln? SWE-Rebench stellt eine mit hoher Zuverlässigkeit und Nachvollziehbarkeit ausgestattete Referenz bereit, die als objektiver Maßstab gelten kann. Durch die Eliminierung von Datenkontamination und die Standardisierung des Evaluationsrahmens werden Fortschritte in den Kernkompetenzen von Sprachmodellen leichter erkennbar. Dabei sind insbesondere Eigenschaften wie das analytische Erkennen komplexer Softwareprobleme, das Planen sinnvoller Lösungsschritte, die korrekte Codierung und die abschließende Verifikation entscheidend. Die Fähigkeit, innerhalb eines vorgegebenen Agentensystems zielgerichtet zu arbeiten, wird gleichermaßen bewertet – ein Aspekt, der in der realen Nutzung zunehmend an Bedeutung gewinnt. Zusätzlich fördert SWE-Rebench durch seine offizielle und zentralisierte Struktur auch eine umfassendere Vergleichbarkeit zwischen proprietären und offenen Modellen.
Dies ist besonders wertvoll für Forschungsgemeinschaften, die industrielle Akteure und die Weiterentwicklung des Fachgebiets insgesamt. Neben der Veröffentlichung von Ranglisten und Punktzahlen plant das Team, tiefere Analysen zur Performance der Modelle bereitstellen, um Nuancen im Verhalten und typische Fehlerquellen besser zu verstehen. SWE-Rebench ist kein statisches Projekt, sondern ein dynamisch wachsendes Ökosystem. Es sieht vor, den Benchmark regelmäßig mit neuen, automatisch generierten Softwareproblemen zu erweitern und eine wachsende Anzahl aktueller und frontier Modelle zu evaluieren. Damit entsteht ein lebendiges Abbild des Fortschritts im Bereich der Sprachmodell-basierten Softwareentwicklung.
Wer Interesse hat, sich aktiv zu beteiligen, findet beim SWE-Rebench-Team offene Türen. Über Feedback, Vorschläge zu neuen Modellen, Fragen zu Evaluationsparametern oder Angebote zum Zugang proprietärer Modelle wird gerne kommuniziert. Durch die Kollaboration mit der Gemeinschaft kann das Benchmark weiter verbessert und für eine breite Anwenderschaft optimiert werden. Die Bedeutung von SWE-Rebench erstreckt sich über die unmittelbare Praxis hinaus. Es fördert eine Kultur der Offenheit, Reproduzierbarkeit und wissenschaftlichen Integrität bei der Bewertung von KI-Systemen im Softwarebereich.




![The Impossible Feat inside Your VCR (2017) [video]](/images/99905B9F-722D-4E40-A699-68F0963092E7)
![Using AI to build a tactical shooter [video]](/images/6A82699C-42B2-4A23-AF36-2FCEDE434CAC)

