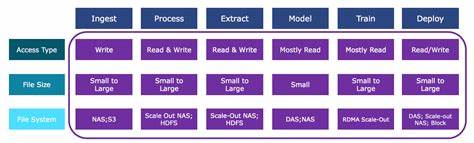
Machine Learning ist heute eine der zentralen Technologien der digitalen Transformation, die in zahlreichen Branchen von der Automobilindustrie bis hin zur Gesundheitsbranche Anwendung findet. Doch während viel über Algorithmen, Modellarchitekturen und Trainingsverfahren gesprochen wird, ist ein oft unterschätztes Thema die Art und Weise, wie Daten im Machine-Learning-Prozess zugänglich gemacht, verarbeitet und gespeichert werden. Das Verständnis von Zugriffsmustern spielt hierbei eine entscheidende Rolle, um eine effiziente, kostengünstige und skalierbare Dateninfrastruktur zu implementieren, die den hohen Anforderungen moderner KI-Anwendungen gerecht wird. Der maschinelle Lernprozess ist nicht linear, sondern umfasst mehrere komplexe Phasen – von der Datenaufnahme bis hin zur Bereitstellung eines trainierten Modells. Jede dieser Phasen weist charakteristische Zugriffsmuster auf – also spezielle Wege, wie auf die Daten zugegriffen wird.
Diese Muster unterscheiden sich je nach Datenvolumen, Lese- und Schreiboperationen sowie Anforderungen an Latenz und Bandbreite. Die Kenntnis und Analyse dieser Zugriffsmuster ist essenziell, um die passende Speichertechnologie und Dateninfrastruktur auszuwählen, die zugleich Leistung und Kosteneffizienz ermöglichen. Zu Beginn steht die sogenannte Datenaufnahme oder Ingest-Phase. In dieser Stufe werden Datenquellen unterschiedlichster Art integriert. Die Bandbreite reicht von winzigen, hochfrequenten Zeitreihendaten von IoT-Sensoren bis zu massiven, seltenen Datensätzen wie Satellitenbildern, die täglich in Terabytes auf die lokale Infrastruktur übertragen werden.
Interessanterweise ist das Zugriffsmuster hier typischerweise „write-only“, also ein einseitiges Schreiben von Daten ohne sofortige Lesebedarf. Besonders wichtig sind in dieser Phase Input/Output-Operationen pro Sekunde (IOPS), da die Systeme hohe Schreiblasten zuverlässig bewältigen müssen. Im Anschluss folgt die Verarbeitungsphase – eine der rechenintensivsten und datenintensivsten Phasen des Machine Learning. Daten werden annotiert, bereinigt und miteinander verknüpft, um aus den Rohdaten brauchbare Features extrahieren zu können. In diesem Abschnitt gleichen sich Lese- und Schreibzugriffe oft aus, da Daten kontinuierlich gelesen, bearbeitet und zurückgeschrieben werden.
Die Speicherinfrastruktur muss hier sowohl hohe Kapazität als auch Performance bieten – häufig kommen parallel arbeitende Dateisysteme und besonders schnelle SSDs oder NVMe-Flash-Speicher zum Einsatz, kombiniert mit Hochgeschwindigkeitsnetzwerken, um die Verarbeitung großer Datenmengen in akzeptablen Zeiträumen zu ermöglichen. Die Extraktionsphase ist geprägt durch einen stark iterativen Prozess. Während Feature-Engineering und Modelltraining ausprobiert und validiert werden, wird stetig auf die verarbeiteten Daten zugegriffen, um neue Feature-Datenpakete zu generieren. Die Zugriffe sind hier sowohl Lese- als auch Schreibvorgänge an großen Datenmengen, die allerdings auf einer einheitlichen Infrastruktur stattfinden können. Die extrahierten Features sind in der Regel deutlich kleiner als die verarbeiteten Rohdaten und werden auf GPU-Plattformen geladen, um die Modellierung und das Training zu beschleunigen.
Die Modellentwicklungsphase unterscheidet sich signifikant von den vorherigen. Datenwissenschaftler arbeiten hier mit kleineren, gezielten Datensätzen, um Hypothesen zu testen und Algorithmen anzupassen. Dabei dominieren Lesezugriffe, während Schreibzugriffe auf die Speicherung von Zwischenergebnissen oder Modellausgaben begrenzt sind. Das Zugriffsmuster ist hier eher locker strukturiert und flexibler, wobei die Reaktionsgeschwindigkeit der Speicherlösungen für zügiges Experimentieren wichtig ist. Das eigentliche Training der Modelle ist die rechenintensivste Phase, besonders im Bereich des Deep Learning.
Hier kommen Cluster von GPU-Servern mit extrem hohen Netzwerkbandbreiten zum Einsatz. Die Speicherinfrastruktur muss darauf ausgelegt sein, die GPUs mit Daten in Echtzeit zu versorgen, um Rechenressourcen optimal zu nutzen und Verzögerungen zu vermeiden. Schnelle Speicherlösungen auf All-Flash NVMe-Basis, besonders solche mit speziell angepassten Dateisystemen, sind hier entscheidend, um den hohen Input-Output-Datenstrom zu gewährleisten und Trainingszeiten zu minimieren. Nach erfolgreichem Training folgt die Modellbereitstellung (Deployment). Bei der Anwendung von inferenzbasierten Modellen werden neue Datensätze benutzt, um Vorhersagen, Klassifizierungen oder Empfehlungen zu generieren.
Das resultierende Datenvolumen ist dabei meist deutlich kleiner als das originale Trainingsdataset, was sich auch in unterschiedlichen Lese- und Schreibverhältnissen widerspiegelt. Generative Modelle, die neue Inhalte wie Kunst, Musik oder Bilder erzeugen, weisen teilweise andere Muster auf, da hier im Rahmen von Kreativprozessen mit variierenden Datenzugriffen operiert wird. Beim Aufbau einer Machine-Learning-Infrastruktur ist es daher hilfreich, zwischen „Big Data“ und „Fast Data“ zu differenzieren. Big Data beschäftigt sich vor allem mit großen Datenmengen, die oft archiviert oder als langfristige Datengrundlage genutzt werden. Hier kommen meist kosteneffiziente, hochkapazitive Speichersysteme zum Einsatz, darunter klassische Festplatten oder hybride Modelle.
Fast Data dagegen steht für Daten, die sehr schnell verarbeitet und bereitgestellt werden müssen – das betrifft vor allem die Phasen der Datenaufnahme, Verarbeitung, Modell-Training und Deployment. Hier sind moderne Flash-basierte Speichertechnologien wie NVMe-SSDs und Software-definierte Speicherlösungen von großer Bedeutung. Eine feingliedrige Analyse und ein präzises Verständnis der Datenzugriffsmuster ermöglichen Unternehmen, gezielt die geeigneten Technologien einzusetzen. Dies führt nicht nur zu messbaren Verbesserungen bei der Performance und Skalierbarkeit von Machine-Learning-Lösungen, sondern wirkt sich auch positiv auf die Betriebskosten und die Gesamtwirtschaftlichkeit der Infrastruktur aus. Die Herausforderung besteht häufig darin, den gesamten Machine-Learning-Prozess als Gesamtsystem zu betrachten, da verschiedene Phasen auf unterschiedliche Art und Weise auf Daten zugreifen und somit unterschiedliche Anforderungen an Speichertechnologien und Netzwerkarchitekturen stellen.
Deshalb sind flexible, modulare und skalierbare Infrastrukturen gefragt, die sich dynamisch an wachsende Datenmengen und wechselnde Zugriffsmuster anpassen können. Innovative Konzepte wie composable Infrastructure oder Software-Defined Storage bieten in diesem Zusammenhang vielversprechende Ansätze, um Ressourcen effizient zu verwalten und optimal auf die spezifischen Anforderungen jeder Phase des Machine Learning zu reagieren. Insbesondere in Hyperscale-Umgebungen, wo mehrere Petabytes an Daten verarbeitet werden, ist es entscheidend, die Datenflüsse genau zu steuern, um Engpässe zu vermeiden und maximale Durchsatzraten zu erzielen. Das Verständnis von Zugriffsmustern im Machine Learning ist somit nicht nur eine technische Notwendigkeit, sondern ein entscheidender Wettbewerbsvorteil. Unternehmen, die ihre Datenumgebung entsprechend anpassen und optimieren, können schneller Modelle entwickeln, Kosten senken und letztlich intelligenter auf komplexe Herausforderungen reagieren.
Zusammenfassend lässt sich sagen, dass der Blick auf Zugriffsmuster weit über eine bloße technische Analyse hinausgeht. Er eröffnet die Möglichkeit, den gesamten Machine-Learning-Prozess nachhaltiger, effizienter und skalierbarer zu gestalten. Für alle, die sich künftig mit Dateninfrastrukturen im Bereich Künstliche Intelligenz beschäftigen, ist das Verständnis dieser Muster ein essenzieller Schritt und eine gute Basis für zukunftsfähige Lösungen.