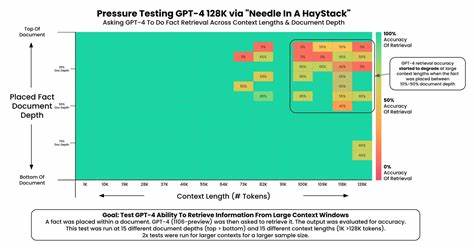
Die Welt der Künstlichen Intelligenz entwickelt sich rasant weiter, insbesondere mit der Einführung neuer und leistungsfähigerer Sprachmodelle. GPT-4 von OpenAI ist derzeit eines der fortschrittlichsten Modelle auf dem Markt und unterstützt nun ein beeindruckend großes Kontextfenster von 128.000 Tokens. Aber was bedeutet diese Zahl eigentlich? Wie viel Text kann das Modell tatsächlich verarbeiten, und wie lässt sich diese Menge in alltägliche, greifbare Einheiten umrechnen? Genau das ist die Fragestellung, die kürzlich auf Hacker News diskutiert wurde und zu einem besseren Verständnis der praktischen Anwendung von GPT-4 beiträgt. Im Folgenden wird diese Thematik ausführlich beleuchtet und verständlich erklärt.
Was ist ein Token im Kontext von GPT-4? Um die Relevanz der 128.000 Tokens zu begreifen, ist es zunächst wichtig zu verstehen, was beim Sprachmodell eigentlich mit „Token“ gemeint ist. Ein Token kann dabei ein ganzes Wort sein, eine Wortkomponente oder sogar nur einzelne Buchstaben oder Satzzeichen. GPT-4 und ähnliche Transformer-Modelle zerlegen Texte vor der Verarbeitung in solche Token, um daraus Sinnzusammenhänge und Kontext zu erkennen. Die durchschnittliche Token-Länge hängt stark von der verwendeten Sprache und vom Texttyp ab.
In englischer Standardsprache wird häufig mit etwa drei Viertel eines Wortes pro Token gerechnet, was heißt, dass 100 Tokens ungefähr 75 Wörtern entsprechen. Die grobe Annahme, dass ein Token etwa vier Zeichen enthält, hilft zusätzlich bei der Umrechnung in Zeichenanzahlen. Vergleich mit herkömmlichen Textgrößen Um diese abstrakte Zahl von 128.000 Tokens greifbarer zu machen, bietet es sich an, Vergleiche mit bekannteren Größen anzustellen. Ein typisches einseitiges A4-Dokument mit Standard-Formatierung (Schriftgröße 12pt, einzeiliger Abstand) enthält etwa 500 bis 600 Wörter.
Wenn man die Faustregel von ¾ Wort pro Token anlegt, resultiert das in ungefähr 700 bis 800 Tokens pro Seite. Das bedeutet, dass das Kontextfenster von GPT-4 ungefähr der Menge von 160 Seiten vollflächigem Text entspricht. Je nach Schreibstil und Formatierung kann diese Zahl leicht nach oben oder unten variieren, weshalb eine Spanne von 150 bis 190 Seiten als realistisch gilt. Diese große Kapazität hebt GPT-4 von seinen Vorgängern deutlich ab, die zum Teil nur einen Bruchteil dieser Kontextgröße verarbeiten konnten. Praktische Bedeutung des erweiterten Kontextfensters Das Vergrößern des Kontextfensters auf 128.
000 Tokens bedeutet nicht nur, dass viel längere Texte verarbeitet werden können. Es eröffnet auch neue Möglichkeiten in den Bereichen Forschung, Kreatives Schreiben, juristische Analyse, Softwareentwicklung und viele weitere Felder. Beispielsweise können komplette Bücher, komplexe wissenschaftliche Abhandlungen oder umfassende Vertragswerke in einem einzigen Durchgang analysiert und verarbeitet werden. Für Autoren und Redakteure bedeutet es eine enorme Erleichterung, weil der gesamte Text als Kontext zur Verfügung steht und somit kohärentere Vorschläge und textliche Verbesserungen generiert werden können. Auch für Entwickler, die mit dem Modell arbeiten, bringt dieses große Fenster klare Vorteile mit sich.
Der gesamte Programmcode einer umfangreichen Software kann als Kontext in das Modell eingespeist werden, um komplexe Analysen durchzuführen oder intelligenten Support bei der Fehlerbehebung zu bieten. Herausforderungen im Umgang mit größeren Kontextfenstern Trotz der beeindruckenden Möglichkeiten, die 128.000 Tokens bieten, sind auch gewisse Herausforderungen damit verbunden. Zur Verarbeitung großer Textmengen sind entsprechend hohe Rechenressourcen erforderlich. Je mehr Tokens im Kontext berücksichtigt werden, desto aufwändiger wird die Generierung von Antworten, was sich in der benötigten Rechenzeit und den Kosten niederschlägt.
Außerdem kann die Qualität der Ergebnisse beeinträchtigt werden, wenn das Modell nicht gut darin ist, den relevanten Kontext in dieser riesigen Datenmenge zu identifizieren. Zum Beispiel kann ein Ausufernder Kontext dazu führen, dass das Modell „den Faden verliert“ und weniger präzise antwortet. Deshalb wird auch viel Forschung betrieben, wie man Modelle darin trainieren kann, effizient mit langen Kontexten umzugehen. Zukunftsperspektiven und Bedeutung für die KI-Entwicklung Die Erweiterung des Kontextfensters ist ein weiterer bedeutender Schritt auf dem Weg zur Entwicklung von KI-Systemen, die komplexe Aufgaben menschlicher Kommunikation immer besser verstehen und bewältigen können. Das ermöglicht unter anderem eine natürlichere Interaktion mit KI, da mehr Hintergrundinformationen und längere Gedankengänge berücksichtigt werden können.
Für Unternehmen und Anwender kann das bedeuten, dass KI-Systeme künftig in der Lage sind, tiefgründige Beratungen, umfassende Dokumentenzusammenfassungen oder auch kreative Arbeiten mit hohem Detailgrad zu übernehmen. Damit kommen wir dem Ziel einer echten, hilfreichen und vielseitigen künstlichen Intelligenz ein großes Stück näher. Fazit Zusammenfassend lässt sich sagen, dass das 128.000-Tokens-Kontextfenster von GPT-4 eine wirklich beeindruckende Kapazität darstellt, die in etwa 150 bis 190 A4-Seiten Text entspricht. Diese Quantität eröffnet neue Möglichkeiten in der Nutzung von Sprachmodellen und verbessert deren Leistungsumfang erheblich.
Gleichzeitig bringt es Herausforderungen hinsichtlich Rechenaufwand und Kontextmanagement mit sich, an deren Lösung intensiv geforscht wird. Das Verständnis, wie viel Text diese Tokenanzahl wirklich ist, hilft Anwendern und Entwicklern dabei, die Potenziale und Grenzen von GPT-4 besser einzuschätzen und gewinnbringend einzusetzen. Mit der weiteren Verbesserung solcher Modelle ist in Zukunft mit noch größerer Leistungsfähigkeit und Anwendungsbreite im Bereich der künstlichen Intelligenz zu rechnen.


![How to Transcribe a Song with fugue-state.io [video]](/images/A5B02D67-4590-44CC-9D8A-C398A5C35F8B)
![Meta First Quarter 2025 Results [pdf]](/images/05AD55FD-07E5-4C94-95B2-BC8BF6E9703A)