Die Welt der Datenstrukturen wächst beständig, da Programme und Anwendungen immer komplexer werden und gleichzeitig hohe Anforderungen an Performance und Speicherverwaltung haben. Ein Paradigma, das in den letzten Jahren stark in den Fokus gerückt ist, sind sogenannte persistente Datenstrukturen. Diese erzeugen bei jeder Änderung eine neue Version der Datenstruktur, während die alte unverändert bestehen bleibt. Dadurch bieten sie eine hohe Sicherheit vor unbeabsichtigten Seiteneffekten und eine größere Vorhersagbarkeit des Programms. Doch diese Vorteile haben ihren Preis: Das naive Kopieren großer Datenmengen bei jeder Änderung führt schnell zu einem erheblichen Mehrverbrauch an Zeit und Speicher.
Hier kommen optimierte Techniken wie strukturelle Teilteilung ins Spiel, die das Kopieren beschleunigen und Speicher sparen, da unveränderte Teile der Datenstruktur wiederverwendet werden. Die Speicher- und Zeitkomplexität sinkt dadurch etwa von linear auf logarithmisch – ein enormer Fortschritt, der beispielsweise im funktionalen Programmierumfeld starken Anklang findet. Allerdings bringt auch diese Optimierung nicht für alle Anwendungsfälle die gewünschte Effizienz. Gerade in Szenarien mit sehr großen Datenstrukturen oder häufigen Updates entstehen noch immer Engpässe. Um dieses Problem anzupacken, wurden sogenannte transiente Datenstrukturen entwickelt.
Transiente Datenstrukturen sind quasi mutable Varianten der persistenten Datenstrukturen, die es erlauben, Veränderungen direkt und oft deutlich schneller vorzunehmen. Trotz der Mutabilität behalten sie jedoch eine ähnliche Schnittstelle wie persistente Strukturen bei, was die Integration erleichtert. Der entscheidende Unterschied ist, dass transiente Strukturen nach einem Update eventuell intern verändert werden, sodass die alte Version nicht mehr zugänglich oder gültig sein muss – eine Einschränkung, die jedoch durch geeignete Nutzungsmuster beherrschbar ist. Ein weiterer, spannender Gedanke ist die Verschiebung dieses Modells aus dem strikt funktionalen Paradigma hin zu einer weniger restriktiven Welt, in der Mutation akzeptiert und sogar gewünscht wird, solange sie kontrolliert erfolgt. In solchen „nicht-strikt-funktionalen“ Umgebungen ist es unnötig, vor jeder Veränderung eine komplette Kopie zu erzwingen.
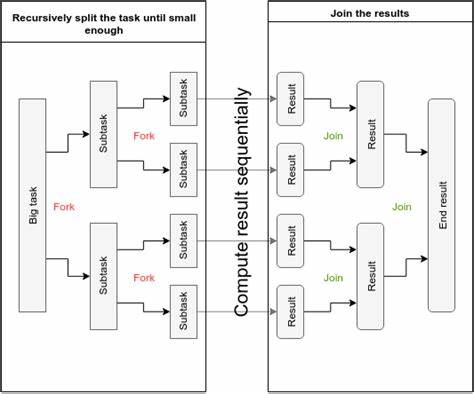
Gleichzeitig gibt es aber immer wieder Situationen, in denen es wichtig ist, eine neue Version der Datenstruktur zu besitzen – etwa wenn mehrere Threads oder Methoden parallel und unabhängig voneinander auf unterschiedlichen Zuständen arbeiten sollen. Hier setzen Fork-Join Datenstrukturen an. Sie verbinden die Vorzüge von persistenten und transienten Datenstrukturen und erlauben sublineare Kopien – also Kopiervorgänge, deren Aufwand deutlich unterhalb der Größe der gesamten Datenstruktur liegt. Diese Effizienz entsteht durch strukturelle Teilung, bei der unveränderte Teilbäume oder interne Knoten zwischen alten und neuen Versionen geteilt werden. Dadurch ist es zum Beispiel möglich, eine leicht veränderte Kopie anzulegen, ohne die komplette Datenmenge duplizieren zu müssen.
Zusätzlich eröffnet die Technik der strukturellen Teilung neue Möglichkeiten für das Zusammenführen – das sogenannte Join – verschiedener Versionen. Gerade in Datenparallelen Szenarien, bei denen Zwischenergebnisse aus unterschiedlichen Prozessen oder Threads zusammengeführt werden müssen, kann dieser „Merge“ erheblich beschleunigt werden. Statt komplette Datenstrukturen neu aufzubauen, nutzt der Algorithmus Strukturgleichheiten und teilt sich wieder in unveränderten Teilen, was zu einem weit effizienteren Zusammenschmelzen der Daten führt. Ein besonders großer Vorteil an Fork-Join Datenstrukturen ist ihre Flexibilität. Da sie eine Schnittstelle bieten, die mutierende und kopierende Vorgänge gleichermaßen unterstützt, können sie in bestehende Systeme integriert werden, ohne dass große Umstellungen notwendig sind.
Dies erleichtert nicht nur die Einführung in bestehende Projekte, sondern ermöglicht es auch, bekannte Programmierschnittstellen weiterzuverwenden und gleichzeitig von den Performance-Vorteilen der neuen Technik zu profitieren. Im Gegensatz zu klassischen funktionalen persistenten Datenstrukturen, die oft eine Umstellung der Denkweise erfordern und den gesamten Programmierstil beeinflussen, fungieren Fork-Join Datenstrukturen als Art „Drop-in“-Ersetzungen oder Erweiterungen bestehender Datentypen. Entwickler können somit gezielt dort multiplattformsicher und nebenläufig agieren, wo das Kopieren und Zusammenführen von Daten zwingend erforderlich ist, während sie andere Bereiche weiterhin mit konventionelleren mutablen Strukturen abdecken. Darüber hinaus bieten Fork-Join Datenstrukturen eine interessante Grundlage, um neue abstrakte Schichten zu implementieren. Für Umgebungen, die eine funktionale Programmierung bevorzugen, können auf diesen mutablen Kerntechnologien persistent abstrahierte Schnittstellen aufgebaut werden.
Diese passen dann vor externe Zugriffe eine effiziente interne Kopie an, ohne dass der Programmierer die Komplexität der internen Mutabilität sehen muss. So entsteht eine Kombination aus hoher Performance und funktionaler Sicherheit. Im praktischen Alltag zeigt sich dieses Konzept als besonders vorteilhaft in hochperformanten Systemen mit paralleler Datenverarbeitung, in verteilten Systemen und bei der GUI-Programmierung, wo viele parallele Zustände gepflegt werden müssen. Auch in Big Data und Echtzeitanwendungen kann die Fähigkeit, Daten effizient zu kopieren, zu bearbeiten und anschließend wieder zusammenzuführen, enorme Ressourcen einsparen. Ein oft unterschätzter Aspekt ist zudem die Speichereffizienz.
Während klassische mutable Datenstrukturen häufig in jedem Update neue Speicherbereiche allozieren, erlauben Fork-Join Datenstrukturen durch strukturelle Teilung eine nachhaltigere Nutzung von Ressourcen. Insbesondere in Situationen mit langsamen Speicherzugriffen oder limitiertem Arbeitsspeicher liefert dies einen signifikanten geschwindigkeits- und energiesparenden Vorteil. Gleichzeitig fordert der Einsatz von Fork-Join Datenstrukturen eine neue Herangehensweise bei der Programmierung. Entwickler müssen die neuen Möglichkeiten nutzen, wissen, wann eine Kopie tatsächlich erforderlich ist und wann Mutation genügt. Die Grenzen zwischen persistentem und transientem Verhalten verschwimmen, was eine bewusste Steuerung der Versionsverwaltung innerhalb der Anwendung notwendig macht.
Solche Überlegungen führen jedoch zu besser überlegtem und strukturierterem Code. Die Schnittstelle von Fork-Join Datenstrukturen mit ihrer Option, bewusst reproduzierbare Versionen anzulegen und gezielt zusammenzuführen, fördert außerdem die Parallelisierung. In Multithread-Umgebungen oder verteilten Architekturen kann die Möglichkeit, lokal zu arbeiten und nach Abschluss der Arbeit die Ergebnisse effizient zusammenzuführen, die gesamte Skalierbarkeit verbessern und die Komplexität gleichzeitig verringern. Ein abschließender Blick zeigt, dass die Konzepte hinter Fork-Join Datenstrukturen auch weit über klassische Datenverwaltung hinauswirken. Sie beeinflussen Designentscheidungen in moderner Softwareentwicklung, ermöglichen neue Muster im Softwarearchitektur-Design und zeigen innovative Wege auf, wie Mutabilität und Immutabilität koexistieren können, ohne dass man großen Aufwand betreiben muss, um zwischen den beiden Welten zu wechseln.
Immer mehr Entwickler erkennen die Vorteile von Fork-Join Datenstrukturen, da sie die Kluft zwischen funktionaler Sicherheit und unter Performance-Gesichtspunkten nötiger Mutabilität überbrücken. Sie bilden so einen Baustein für eine zukunftssichere, effiziente und dennoch flexible Softwareentwicklung, die den Anforderungen moderner Systeme gerecht wird und dabei Potenziale sowohl im Bereich Parallelität als auch in der Wartbarkeit von Software ausschöpft. In diesem Sinne bieten Fork-Join Datenstrukturen eine spannende Kombination aus vertrauten Paradigmen und höchster Effizienz, die Entwickler ermutigen, das Beste aus beiden Welten zu nutzen – die Sicherheit und einfache Konzepte persistenter Datenstrukturen mit den nicht zu vernachlässigenden Performancevorteilen kontrollierter Mutation. Dieses Zusammenspiel findet zunehmend Eingang in moderne Programmiersprachen, Bibliotheken und Frameworks – aus gutem Grund.





![Why Older Men Are Staying Single Today [video]](/images/E3E091D3-F906-45BC-9625-268FA3376898)

