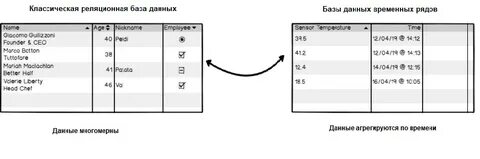
In einer zunehmend datengetriebenen Welt gewinnt die Fähigkeit, große Mengen an Zeitreihendaten zuverlässig und schnell zu speichern, zu verarbeiten und abzurufen, immer mehr an Bedeutung. Zeitreihendaten entstehen überall dort, wo Werte kontinuierlich und mit Zeitstempeln versehen erfasst werden. Typische Anwendungsgebiete sind Video-Streaming, Finanzmärkte, IoT-Sensorik oder industrielle Überwachungssysteme. NanoTS ist eine neue, eingängige und sehr leistungsfähige Zeitreihendatenbank, die speziell für solche Anforderungen optimiert wurde. Ihre minimalistische und dennoch hochfunktionale Architektur ermöglicht sowohl sehr schnelle Schreibvorgänge als auch effektives Lesen großer Datenmengen.
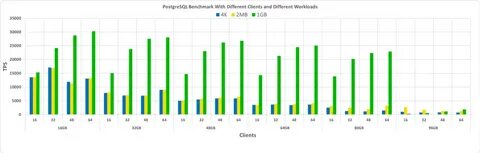
NanoTS zeichnet sich insbesondere dadurch aus, dass sie als eingebettete Datenbank konzipiert wurde, ähnlich wie SQLite, aber mit dem Fokus auf Zeitreihendaten. Das bedeutet, dass sie direkt in Anwendungen integriert werden kann, ohne dass ein separater Datenbankserver erforderlich ist. Für Entwickler ergeben sich dadurch große Vorteile: Einfachere Installation, geringere Latenzen und maximale Kontrolle über die Daten. Ein herausragendes Merkmal von NanoTS sind die ultraschnellen Schreibzugriffe. Auf SSDs erreicht die Datenbank Schreibzeiten von durchschnittlich 8,83 Mikrosekunden pro Eintrag, auf konventionellen Festplatten sind es etwa 300 Mikrosekunden.
Diese beeindruckende Performance ist vor allem auf die speichergestützte Architektur zurückzuführen. Die Daten werden mittels Memory-Mapping in den Speicher geladen, was einen nahezu verzögerungsfreien Zugriff erlaubt. Diese Technik macht den Schreibvorgang nahezu sperr- und blockierungsfrei, was in Echtzeitanwendungen von immensem Vorteil ist. Die Speicherstruktur von NanoTS besteht aus einem hybriden Layout. Die Metadaten der Datenbank werden in SQLite verwaltet, während die eigentlichen Zeitreihendaten in speicherabbildenden Binärdateien abgelegt sind.
Die Daten werden in Blöcken organisiert, deren Größe flexibel an die Bedürfnisse der Anwendung angepasst werden kann. Ein Block besteht aus einem Header, der Metadaten und die Anzahl der Frames enthält, einem Index, der Zeitstempel auf Datenoffsets abbildet, sowie den eigentlichen Datenframes, die variable Größen aufweisen – ideal für die Speicherung unterschiedlich großer Datenpakete. Da die meisten Anwendungen, die NanoTS verwenden, eine kontinuierliche Datenaufnahme erfordern, ist die Haltbarkeit der Daten ein wichtiger Aspekt. NanoTS bietet hier konfigurierbare Durability-Optionen. Kleinere Blöcke verbessern die Wiederherstellbarkeit nach einem unerwarteten Systemabsturz, während größere Blöcke die Performance steigern, jedoch potentiell größere Datenverluste im Crash-Fall verursachen können.
Dieses Abwägen zwischen Performance und Zuverlässigkeit können Entwickler mit NanoTS optimal an ihre individuellen Anforderungen anpassen. Ein weiteres Schlüsselelement ist die automatische Crash-Recovery-Funktion. NanoTS erkennt bei jedem Start anstehende Reparaturarbeiten und stellt sicher, dass teilweise geschriebene Datenblöcke korrekt erkannt und repariert werden. Dies garantiert eine hohe Datenintegrität und minimiert Ausfallzeiten. Darüber hinaus punktet NanoTS mit Flexibilität durch Unterstützung mehrerer Datenströme innerhalb einer einzigen Datenbankdatei.
Dies ermöglicht es, unterschiedliche Datenarten – etwa Video, Audio und Sensorwerte – parallel und gleichzeitig zu speichern und auszulesen. Die Iterator-Interfaces der Datenbank erlauben einen effizienten Zugriff auf die Daten in beide Richtungen und ermöglichen präzise Suche und Navigation anhand von Zeitstempeln. Die Einsatzmöglichkeiten von NanoTS sind vielfältig. Im Bereich Video-Streaming kann NanoTS verwendet werden, um Videoframes mit Mikrosekunden-Timestamps zu speichern und schnelle Positionssuchen für Wiedergaben zu realisieren. Auch bei IoT-Anwendungen ist der Nutzen groß: Hochfrequente und heterogene Sensordaten können effizient zusammengeführt, analysiert und für historische Abfragen bereitgestellt werden.
Im Finanzsektor wiederum sind Genauigkeit und Geschwindigkeit entscheidend für Tick-Daten und Marktanalysen, wo NanoTS mit seiner low-latency-Architektur und präzisem Zeitmanagement seine Stärken voll ausspielen kann. Die Open-Source-Datenbank ist plattformübergreifend nutzbar und unterstützt Linux, Windows und MacOS. Die implementierten APIs sind in moderner C++17 geschrieben, was eine einfache Integration in bestehende Projekte erleichtert. Für Entwickler ist der Einstieg besonders unkompliziert, da NanoTS entweder als statisch zu linkende Bibliothek oder als Copy-and-Paste-Include mit wenigen Quelldateien ins Projekt eingebunden werden kann. Einige Besonderheiten, die NanoTS hervorheben, sind die automatische Speicherverwaltung und -recycling.
Ist der vorgegebene Speicherplatz voll, werden die ältesten Datenblöcke automatisch überschrieben, sofern die Auto-Recycle-Funktion aktiviert ist. Dies erlaubt den Betrieb auch bei begrenztem Speicher und gewährleistet gleichzeitig, dass stets die neuesten Daten gespeichert werden. Das ist vor allem bei Ringpuffer-Anwendungen wie Streaming-Speicherung von Vorteil. Dank des geringen Ressourcenbedarfs und der effizienten Nutzung des virtuellen Adressraums durch Memory-Mapping eignet sich NanoTS hervorragend für Systeme mit limitierten Ressourcen oder eingebettete Systeme. Die Limitierungen der Datenbank, wie beispielsweise das Schreiben nur in eine Richtung und die Notwendigkeit angemessener Blockgrößen, sind gut dokumentiert und durchdacht, sodass Entwickler bei der Implementierung die richtigen Entscheidungen treffen können.
Die offene Lizenz nach Apache 2.0 gibt Unternehmen und Entwicklern Sicherheit und Flexibilität bei der Verwendung und Anpassung des Codes. Zudem fördert die aktive Community den Austausch und kontinuierliche Weiterentwicklung. Abschließend lässt sich sagen, dass NanoTS mit seiner Kombination aus Geschwindigkeit, Robustheit und Kompaktheit ein wertvolles Werkzeug für Applikationen darstellt, die große Mengen zeitbasierter Daten verarbeiten müssen. Besonders im Zeitalter von IoT, hochauflösendem Video und hochfrequenten Finanzdaten ist eine effiziente und zuverlässige Zeitreihendatenbank von zentraler Bedeutung für den Erfolg moderner Softwarelösungen.
NanoTS erfüllt diese Anforderungen auf beeindruckende Weise und ist eine attraktive Alternative zu schwergewichtigeren Datenbanksystemen oder selbstgebauten Speicherlösungen. Entwickler, die Wert auf Performance, Stabilität und einfache Einbindung legen, finden in NanoTS eine offen lizenzierte Technologie, die mit neuesten Methoden die Hürden moderner Echtzeitdatenverarbeitung elegant überwindet.