Die Forschung im Bereich der künstlichen Intelligenz (KI) ist von einem ständigen Wettlauf geprägt. Jeden Tag entstehen neue Ideen, Methoden und Technologien, die das Potenzial haben, die Entwicklung von KI grundlegend zu verändern. Doch nicht jede vielversprechende Idee hält, was sie verspricht. Viele Forschungsansätze scheitern bei praktischen Tests oder liefern nicht die erhofften Verbesserungen. Die Validierung dieser Ansätze ist oft zeit- und ressourcenintensiv und stellt damit eine große Hürde für schnellere Innovation dar.
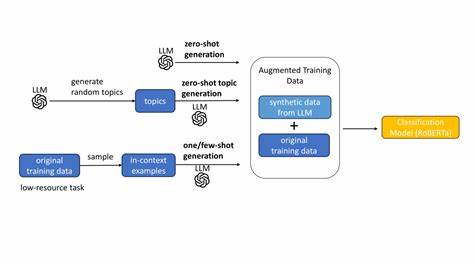
Genau an diesem Punkt setzen moderne Sprachmodelle an. Sie können inzwischen nicht nur Texte generieren oder Fragen beantworten, sondern auch komplexe Zusammenhänge verstehen und bewerten. Ein richtungsweisender Forschungsansatz beschäftigt sich damit, den Erfolg von KI-Forschungsprojekten oder -ideen anhand bereits vorliegender Daten vorherzusagen. Damit wird ein effektiver Entscheidungsprozess möglich, der Ressourcen bündelt und unnötigen Aufwand verringert. Im Zentrum dieser Innovation steht die Nutzung von großen Sprachmodellen wie GPT-4.
1, die auf umfangreichen Datensätzen trainiert wurden und in der Lage sind, subtile Nuancen der Fachliteratur zu erfassen. Forscher haben nun eine Benchmark entwickelt, die genau diese Fähigkeit überprüft: Gegeben werden zwei vergleichbare Forschungsansätze oder Ideen, und das Modell soll vorhersagen, welche von beiden in Tests oder Experimenten bessere Ergebnisse erzielen wird. Diese Aufgabe stellt eine erhebliche Herausforderung dar, da der Erfolg einer wissenschaftlichen Idee von vielen Faktoren abhängt. Neben der methodischen Qualität sind auch die Innovationskraft, die Umsetzbarkeit und verschiedene externe Einflüsse entscheidend. Erst recht ist es überraschend, dass ein Sprachmodell nicht nur diese komplexen Faktoren erfassen kann, sondern auch menschliche Experten im Durchschnitt übertrifft.
Die getesteten Daten stammen aus einer umfangreichen Sammlung von Forschungsarbeiten, die nach dem Cut-Off-Datum des Basismodells veröffentlicht wurden. Insgesamt wurden über 1.500 validierte Vergleichspaare als Testset genutzt, daneben etwa 6.000 Paare für das Training. Diese Paare bestehen aus zwei unterschiedlich bewerteten Forschungsansätzen, deren Resultate empirisch bestätigt wurden.
So entsteht eine solide Grundlage, um die Vorhersagepräzision der Modelle zu prüfen. Die Ergebnisse sprechen für sich: In der Domäne der natürlichen Sprachverarbeitung (Natural Language Processing, NLP) erzielte das fine-getunte System eine Genauigkeit von knapp über 64 Prozent, während erfahrene menschliche Experten nur auf knapp 49 Prozent kamen. Bei der Auswertung des gesamten Testsets steigerte sich die Modellgenauigkeit sogar auf etwa 77 Prozent. Typische Sprachmodelle ohne spezielle Feinabstimmung, zum Beispiel die o3-Version, erreichten hingegen nicht mehr als Zufallstreffer. Besonders interessant ist, dass das Modell seine Vorhersagen nicht durch oberflächliche Merkmale wie die Komplexität der Forschungsansätze oder Länge der Papiere trifft.
In umfangreichen Robustheitstests, sowohl von Menschen als auch von anderen Sprachmodellen entworfen, wurde diese Möglichkeit ausgeschlossen. Damit steigt das Vertrauen, dass die KI ein echtes Verständnis der wissenschaftlichen Ideen und deren potenziellem Erfolg besitzt. Ein weiterer vielversprechender Aspekt liegt in der Anwendung auf noch unveröffentlichte, neuartige Ideen. Dazu gehören unter anderem Vorschläge, die von KI-gestützten Ideengenerierungsagenten entwickelt wurden. Hier liegt die Genauigkeit bei ungefähr 64 Prozent, was zeigt, wie solche Systeme als sogenannte Reward-Modelle für die Verbesserung von Ideengenerierungsprozessen eingesetzt werden können.
Dadurch ergeben sich völlig neue Möglichkeiten in der KI-Forschung, indem die Qualität von Ideen bereits im Entstehungsprozess verbessert wird. Die Bedeutung dieser Ergebnisse kann kaum überschätzt werden. Die traditionelle empirische Forschung ist geprägt von aufwändigen Experimenten und Validierungen, die viel Zeit und Energie kosten. Mit der Unterstützung von leistungsfähigen Sprachmodellen können Forscher schneller entscheiden, welche Ideen eine höhere Wahrscheinlichkeit für Erfolg besitzen und welche Ansätze weniger vielversprechend sind. Dies führt nicht nur zu einer Effizienzsteigerung, sondern kann auch die Innovationsdynamik in der gesamten KI-Community beschleunigen.
Darüber hinaus könnten diese Modelle dazu beitragen, die Transparenz und Nachvollziehbarkeit wissenschaftlicher Entwicklungen zu verbessern. Indem sie eine objektive Einschätzung liefern, fungieren sie als wertvolles Korrektiv gegenüber menschlichen Biases und Fehleinschätzungen. Die Kombination aus menschlicher Intuition und maschineller Analyse verspricht somit eine Symbiose, die das volle Potenzial beider Welten ausschöpft. Natürlich gibt es auch Einschränkungen und Herausforderungen. Die Qualität der Vorhersagen hängt stark von der Datenbasis ab, auf der die Sprachmodelle trainiert wurden.
Sollten bestimmte Forschungsbereiche weniger gut repräsentiert sein, kann dies die Aussagekraft der Prognosen einschränken. Zudem müssen ethische Aspekte sowie die Gefahr einer Überoptimierung auf den Benchmark sorgfältig berücksichtigt werden, um Fehlentwicklungen im Forschungsprozess zu vermeiden. Dennoch scheint der Weg klar, dass Sprachmodelle zu einem unverzichtbaren Werkzeug in der empirischen KI-Forschung werden. Sie eröffnen eine ganz neue Dimension der Unterstützung von Innovation und Effizienz und könnten letztlich dazu beitragen, die Entwicklung von künstlicher Intelligenz insgesamt schneller, präziser und nachhaltiger zu gestalten. Zukünftige Forschungen werden sich darauf konzentrieren müssen, diese Systeme noch besser an unterschiedliche Forschungsgebiete und -methoden anzupassen.