Die Entwicklung von Java-Anwendungen ist ein komplexer Prozess, der weit über das bloße Schreiben von Quellcode hinausgeht. Wenn Entwickler an den Debugging-Prozess denken, ist es eine natürliche Annahme, dass sie direkt mit dem Quellcode arbeiten, den sie geschrieben haben. Doch der wahrhaftige Ablauf hinter den Kulissen ist weitaus facettenreicher. Java-Programme werden nicht direkt als Quellcode ausgeführt, sondern zuerst in Bytecode übersetzt, der wiederum von der Java Virtual Machine (JVM) verarbeitet wird. Dieses Verfahren bietet nicht nur Plattformunabhängigkeit, sondern sorgt auch für zahlreiche Herausforderungen und Chancen beim Debuggen.
Das Verständnis der Zusammenhänge zwischen Quellcode, Bytecode und Debug-Informationen kann Entwicklern helfen, Fehler schneller zu finden und zu beheben sowie ihre Anwendungen effizienter zu gestalten. Java-Quellcode ist für Entwickler die verständlichste Form, da er im gewohnten Syntax- und Sprachgebrauch vorliegt. Sobald ein Programm kompiliert wird, erzeugt der Java-Compiler (javac) Bytecode-Dateien mit der Endung .class. Diese Dateien sind jedoch nicht direkt lesbar, sondern enthalten eine Reihe von plattformunabhängigen Befehlen, die über die JVM ausgeführt werden.
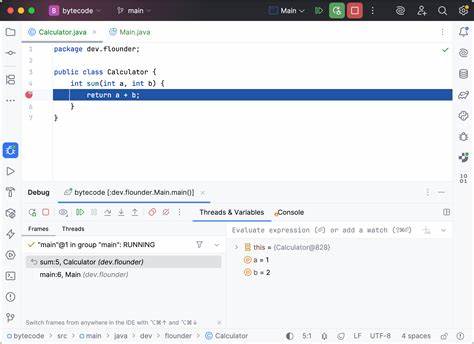
Der Bytecode ist in gewisser Weise eine Zwischendarstellung, welche die Programmeinstellungen und Logik in eine Form bringt, die auf jeder Maschine mit einer installierten JVM lauffähig ist. Bytecode ist dabei kompakt und optimiert, was seiner Portabilität und Ausführungsgeschwindigkeit dient. Ein einfaches Beispiel dafür ist eine Methode, die zwei Zahlen addiert. Im Quellcode ist das leicht verständlich durch zwei Parameter und eine Rückgabe ausgedrückt. Kompiliert man sie, wandelt der Compiler diese Methode in eine Folge von Bytecode-Befehlen um, die etwa Ladebefehle für Variablen, eine Additionsoperation und schließlich den Rückgabebefehl umfassen.
Diese Bytecode-Abfolge repräsentiert die Logik, die die JVM Schritt für Schritt abarbeitet. Trotzdem wäre es für Entwickler ineffizient, Fehlersuchen oder Programmflussanalysen direkt auf dem Bytecode durchzuführen. Die Bytecode-Ebene ist für Menschen schwer lesbar und unterscheidet sich erheblich vom ursprünglichen Quellcode. Hier kommen Debug-Informationen ins Spiel. Diese werden während der Kompilierung in die .
class-Dateien eingebettet und enthalten essenzielle Daten wie Zeilennummern, Variablennamen und den Namen der ursprünglichen Quelldatei. Dank dieser sogenannten Debug-Symbole können Debugger wie JDB oder die in modernen IDEs integrierten Tools den Programmfluss im Quellcode anzeigen, Variablenwerte nachvollziehen und den Ursprung von Ausnahmen bestimmen. Eine wichtige Komponente der Debug-Informationen sind die Zeilennummern, gespeichert in der sogenannten LineNumberTable. Diese Tabelle verknüpft Bytecode-Offsets mit konkreten Zeilennummern im Quellcode. So kann der Debugger genau angeben, an welcher Stelle im Quellcode sich ein Fehler befindet oder wo gerade Ausführung stattfindet.
Ohne diese Informationen wäre es nahezu unmöglich, präzise auf Fehlersuchen zu arbeiten, denn Ausnahme-Stapelspuren oder Breakpoints könnten keine relevanten Quelltext-Zeilen anzeigen und wären nur mit Bytecode-Offsets versehen. Neben Zeilennummern sind auch Variablennamen in der sogenannten LocalVariableTable enthalten. Diese erlaubt es, während des Debugging-Prozesses die tatsächlichen Variablennamen und nicht nur generische Slot-Bezeichnungen anzuzeigen. Entwickler erhalten so eine transparente Darstellung der laufenden Werte, was das Verstehen des Programmzustands erheblich erleichtert. Fehlen diese Daten, zeigt der Debugger oft Platzhalter wie slot_1 oder slot_2, was die Fehlersuche erschwert.
Der Name der Quelldatei gibt Debuggern zusätzlich Hinweise, welche Quelle zu dem ausgeführten Bytecode gehört. Wird diese Information nicht mitgeliefert, erscheinen Namen beim Debugging als Unknown Source, was ebenfalls die Nachvollziehbarkeit beeinträchtigt. Um diese Debug-Informationen zu steuern, bietet der Java-Compiler verschiedene Compiler-Flags. Standardmäßig sind Zeilennummern und Quellinformationen meist enthalten, Variablennamen manchmal nicht. Über den Schalter -g kann der Entwickler auswählen, welche Debug-Daten einbezogen werden sollen, zum Beispiel -g:lines,vars,source für alle drei Arten.
Die Bewahrung oder Entfernung von Debug-Informationen ist keine triviale Entscheidung. Während diese Daten während der Entwicklung und Fehlersuche enorm wertvoll sind, gibt es Gründe, sie im Produktionsumfeld zu entfernen. Das Fehlen von Debug-Symbolen erhöht marginal den Schutz gegen Reverse Engineering oder das Eindringen durch Debugger. Es hält jedoch keinen entschlossenen Angreifer fern, da andere Techniken die Programminternas offenlegen können. Dennoch kann das Reduzieren der Debug-Informationen die Angriffsfläche und die Angriffsoberfläche etwas verringern.
Neben Sicherheitsaspekten spielt auch die Größe der ausführbaren Dateien eine Rolle. Jede hinzugefügte Debug-Information vergrößert die Klassen-Datei und damit letztlich die gesamte Anwendung. Dies kann gerade in ressourcenbeschränkten Umgebungen wie eingebetteten Systemen entscheidend sein. Ein Vergleich zeigte, dass eine typische Java-Klassen-Datei ohne Debug-Informationen deutlich kleiner sein kann als die vergleichbare Datei mit integralen Debug-Daten. Entwickler müssen also zwischen Komfort beim Debuggen und verlustfreier Größe sowie erhöhter Sicherheit abwägen.
Im Fall von komplexen Anwendungen oder Bibliotheken existieren Fälle, bei denen die Quelldateien nicht Teil des aktuellen Projekts sind. Möchte man während der Fehleranalyse dennoch in den Code von Drittanbieterbibliotheken einsteigen, können Quellen manuell hinzugefügt werden. Entwickler geben sie entweder als separate Quellenwurzeln an oder binden sie als Abhängigkeiten ein. So können moderne IDEs wie IntelliJ IDEA die externen Quellcodes zur Laufzeit zuordnen und ermöglichen ein nahtloses Debugging. Eine Herausforderung stellen Situationen dar, in denen das Projekt, aus dem der Bytecode stammt, gar nicht erst zur Verfügung steht.
Auch hier gibt es pragmatische Lösungen: Ein leeres Java-Projekt wird erstellt, die fehlenden Quelltextdateien werden eingebunden, und die Ziel-JVM wird mit einem Debug-Agenten gestartet. Anschließend verbindet sich eine Debugger-Konfiguration, die als Remote Debugging bezeichnet wird, mit der laufenden Anwendung. Dieses Setup erlaubt das Debuggen einer Anwendung auch ohne originale Entwicklungsumgebung und gleichermaßen mit nur einigen Quellen. Es kann dennoch immer wieder zu Konstellationen kommen, in denen die Diskrepanz zwischen Quellcode und Bytecode zu Problemen führt. So kann das Programm scheinbar an einer falschen oder unerwarteten Stelle anhalten, das sogenannte Source Mismatch.
Eine der Ursachen liegt darin, dass das Debugging nur anhand des Dateinamens arbeitet und versucht, den zur Laufzeit geladenen Bytecode mit vorhandenem Quellcode zu verknüpfen. Sind die Quelldateien veraltet oder modifiziert, kann die Abbildung fehlerhaft sein, was zu irritierenden Debug-Situtation führt. Diese Probleme sind oft durch sorgfältiges Management der Versionsverwaltung und Projektkonfiguration vermeidbar. Zusammenfassend ist das Zusammenspiel von Quellcode, Bytecode und Debugging ein grundlegendes Element der Java-Entwicklungskultur. Die JVM abstrahiert den eigentlichen Ausführungsprozess, während Debug-Informationen die Brücke zwischen Maschinencode und für Menschen verständlichen Quellen schlagen.