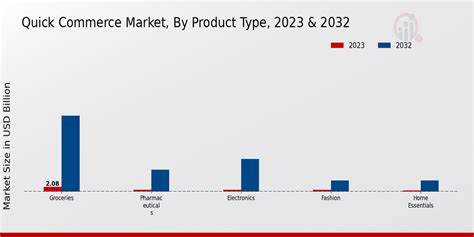
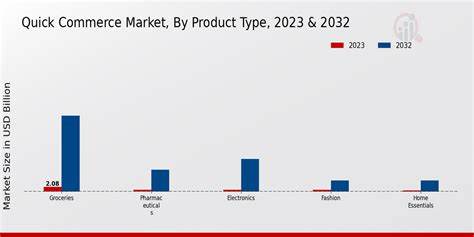
Der Quick Commerce, oft auch als Q-Commerce bezeichnet, revolutioniert das Einkaufsverhalten der Konsumenten, indem Produkte blitzschnell geliefert werden. In einem solch dynamischen und schnelllebigen Markt ist es für Marken essenziell, den Überblick über Verkaufszahlen, Kundenpräferenzen und Lagerbestände in Echtzeit zu behalten. Nur so lässt sich eine agile und datengetriebene Strategie entwickeln, die den Markenerfolg nachhaltig sicherstellt. Die Verarbeitung und Auswertung von Millionen Datenpunkten, von Produktansichten bis hin zu stadtbezogenen Verkaufszahlen, bietet dabei einen unschätzbaren Vorteil für alle Beteiligten. Es gilt jedoch nicht nur, auf Basis großer Datenmengen zu arbeiten, sondern diese auch schnell und präzise interpretieren zu können, um zeitnah Entscheidungen zu treffen und sich somit vom Wettbewerb abzuheben.
Zepto, ein Vorreiter im Quick Commerce in Indien, zeigt eindrucksvoll, wie wichtige Einblicke in die Markenperformance erzeugt und gewinnbringend eingesetzt werden können. Die Plattform verarbeitet täglich riesige Datenmengen und schafft es, daraus relevante Informationen für Marken in nahezu Echtzeit zu gewinnen. Durch den Einsatz moderner Brand-Analytics-Lösungen erhalten Partnerunternehmen nicht nur Transparenz über Trends und Verkaufserfolge, sondern können auch ihr Inventar und die Suchtrends ihrer Produkte detailliert überwachen und optimieren. Die größten Herausforderungen im Umgang mit der Flut an Daten liegen weniger in der Verfügbarkeit als vielmehr in der Handhabung. Datenmengen wachsen explosionsartig mit der Zahl an registrierten Marken, der Vielfalt des Angebots und den Nutzern, die täglich auf der Plattform einkaufen.
Traditionelle relationale Datenbanken wie PostgreSQL bieten zwar eine zuverlässige Basis, stoßen aber schnell an ihre Grenzen, wenn es um komplexe analytische Abfragen über hunderte Millionen Datensätze mit niedriger Latenz geht. Die Abfragegeschwindigkeit und die gleichzeitige Bearbeitung von zahlreichen Benutzeranfragen sind hier elementare Faktoren für den Erfolg. Um diesen Performanceproblemen zu begegnen und die Anforderungen an eine moderne analytische Dateninfrastruktur zu erfüllen, setzte Zepto schließlich auf spezialisierte OLAP-Datenbanksysteme. Nach umfassenden Tests verschiedener Lösungen wie ClickHouse und Apache Pinot fiel die Wahl auf StarRocks. Dieses System überzeugte durch seine Fähigkeit, komplexe Joins blitzschnell auszuführen und selbst bei mehreren hundert Millionen Datenzeilen Antwortzeiten unter einer halben Sekunde zu gewährleisten.
Die enge Integration mit bestehenden Datenquellen wie Kafka und Databricks erlaubt zudem eine einfache Einbindung in bereits etablierte Datenpipelines. Der Aufbau der Architektur verlagerte sich von einem eher zentralistischen Ansatz hin zu einem „Shared-Nothing“-Modell. Dabei verwaltet StarRocks die Daten lokal und sorgt so für eine stark reduzierte Latenz bei der Datenverarbeitung. Dies ist besonders für Dashboards von äußerster Bedeutung, die von externen Markenpartnern genutzt werden, um Echtzeit-Entscheidungen zu treffen. Für Unternehmen, die mit Datenvolumina im Bereich mehrerer Terabyte arbeiten, bietet diese Architektur den klaren Vorteil, das Nutzererlebnis durch einen geringeren Zeitaufwand beim Abruf von Daten dramatisch zu verbessern.
Die Daten werden aus verschiedenen Quellen in StarRocks eingespeist. Ein Teil des Workflows umfasst das Laden der Daten aus Databricks in Form von Parquet-Dateien, die auf Amazon S3 gespeichert sind. Mit der sogenannten Pipe Load Funktion scannt das System kontinuierlich neue Daten in bestimmten Speicherbereichen und lädt diese automatisch in die Datenbank. So bleiben die Informationen stets aktuell, ohne dass manuelle Eingriffe erforderlich sind. Für das Verarbeiten von Änderungssätzen bzw.
Events aus Streaming-Datenströmen setzt Zepto auf die Routine Load Funktion aus Kafka. Diese gewährleistet eine konsistente und genau-einmal-Verarbeitung, die insbesondere für hochfrequente Echtzeit-Analysen unverzichtbar ist. Der Einsatz von Apache Flink als Echtzeit-Datenprozessor ermöglicht es zudem, riesige Datenströme in Echtzeit zu aggregieren und aufzubereiten. So werden nur relevante, verdichtete Metriken an StarRocks weitergeleitet, was die Performance weiter steigert und eine schnellere Datenauswertung ermöglicht. Insgesamt verarbeitet das System mehrere zehn Millionen Datensätze täglich, die innerhalb von Sekunden für aussagekräftige Analysen bereitstehen.
Dieses Konzept erlaubt eine Abkehr von herkömmlichen batchbasierten Systemen hin zu einem modernen Echtzeit-Analytics-Ansatz, der gerade im Quick Commerce Wettbewerb ein entscheidender Faktor ist. Marken profitieren von diesen kontinuierlich aktualisierten Einsichten in vielfältiger Weise. Sie gewinnen nicht nur eine hohe Transparenz über das Nutzerverhalten und die Nachfrage in unterschiedlichen Märkten, sondern können auch ihre Lagerbestände effizienter steuern, Werbekampagnen gezielter ausrichten und ihr Sortiment entsprechend der Kundenvorlieben anpassen. Durch die Umwandlung von Rohdaten in umsetzbare Erkenntnisse erhalten Marken einen Wettbewerbsvorteil und erhöhen die Kundenbindung. Diese nahtlose Verbindung von modernster Technologie und datengetriebenem Geschäftsmodell ist der Schlüssel, um im schnellen und anspruchsvollen Umfeld des Quick Commerce nicht nur mitzuhalten, sondern auch Marktführer zu werden.
Die Transformation von einer MVP-Lösung auf Basis von PostgreSQL zu einem skalierbaren Analytics-Stack mit StarRocks zeigt exemplarisch, wie wichtig es ist, technologische Entscheidungen stetig zu hinterfragen und anzupassen. Die Anforderungen an Geschwindigkeit, Zuverlässigkeit und Integration treiben Innovationen voran. Dabei ist es ebenso entscheidend, die richtigen Tools und Architekturen für den jeweiligen Anwendungsfall auszuwählen, um langfristig erfolgreich zu sein. Der Blick in die Zukunft zeigt, dass Echtzeitdaten und ihre Verarbeitung die Geschäftsmodelle im Quick Commerce weiter verändern werden. Die zunehmende Datenmenge und Komplexität erfordern kontinuierliche Optimierungen an der Infrastruktur und neue Ansätze zur Automatisierung von Analysen.



![Nvidia CEO Huang Says UK in 'Goldilocks' Position for AI [video]](/images/610C0C2A-C44B-4E72-A7E2-13CF3C62E207)