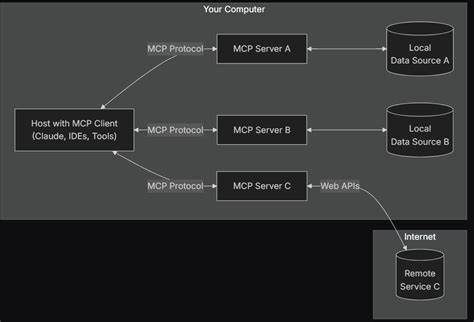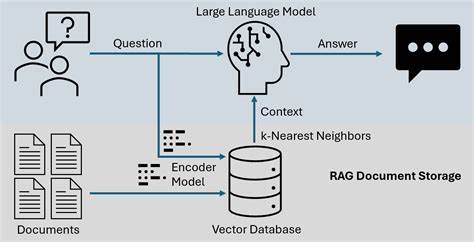
Die Einführung von Retrieval-Augmented Generation, kurz RAG-Systeme, in die Welt der großen Sprachmodelle war ein bedeutender Schritt, der verspricht, die Fähigkeiten von KI-Systemen zu erweitern. Durch die Kombination vortrainierter Sprachmodelle mit externer Wissensdatenbank und Informationsabruf soll die Genauigkeit und Relevanz generierter Texte gesteigert werden. Auf den ersten Blick klingt das nach einer zukunftsweisenden Kombination, die die Grenzen der reinen Sprachmodelle überwindet. Doch trotz der vielversprechenden Ansätze gibt es gewichtige Gründe, warum RAG-Systeme die Sicherheit von großen Sprachmodellen nicht notwendigerweise erhöhen, sondern im Gegenteil oftmals sogar reduzieren können. Bei genauerer Betrachtung offenbaren sich komplexe Probleme, die Auswirkungen auf die Zuverlässigkeit, Manipulationsanfälligkeit und Vertrauenswürdigkeit von KI-Systemen haben.
Große Sprachmodelle, also die sogenannten Large Language Models (LLMs), zeichnen sich durch ihre Fähigkeit aus, durch umfangreiche Trainingsdaten zu lernen und darauf basierende Texte zu generieren. Allerdings sind diese Texte nicht immer korrekt oder sicher, da Modelle oft manchmal Halluzinationen produzieren und unbeabsichtigte Verzerrungen enthalten können. RAG soll hier Abhilfe schaffen, indem das Modell während der Generierung gezielt zusätzliche Informationen aus einer externen Datenquelle abruft. So wird versucht, Fakten zu validieren oder ergänzende Inhalte beizusteuern. Dennoch hat die Einbettung einer solchen Retrieval-Komponente zahlreiche nicht triviale Folgen.
Ein Kernproblem der Sicherheit besteht darin, dass die externe Datenabfrage das Risiko birgt, unsichere, manipulierte oder fehlerhafte Informationen in den Textfluss einzuschleusen. Während das Sprachmodell selbst trainiert und kontrolliert wird, kann die externe Wissensquelle dynamisch und unkontrolliert sein. Wenn also die Rückgewinnung von Inhalten aus einer Datenbank schwach überwacht wird, entstehen Angriffsmöglichkeiten für böswillige Akteure, die falsche oder irreführende Informationen systematisch einspeisen können. In der Praxis heißt das, dass RAG-Systeme anfälliger für sogenannte Datenvergiftungen sind. Dabei manipulieren Angreifer die Datengrundlage, aus der das Modell Informationen zieht.
Dies führt zu einer Degradierung der Antwortqualität und potentiell gefährlichen Fehlinformationen. Besonders heikel wird es, sobald solche Systeme in sensiblen Bereichen wie Gesundheit, Recht oder Finanzen eingesetzt werden. Ein weiteres Sicherheitsrisiko entsteht durch die komplexere Architektur. Die Integration von Retrieval-Modulen mit Sprachmodellen erhöht die Anzahl potentieller Fehlerquellen und Angriffsflächen. Während reine LLMs hauptsächlich durch Modellarchitekturen und Trainingsdaten beeinflusst werden, erzeugt die Kombination mit externen Suchmodulen zusätzliche Herausforderungen in puncto Robustheit und Verlässlichkeit.
Die Schnittstellen zwischen Komponenten müssen abgesichert werden, um Performanz und Datenschutz sicherzustellen. An diesem Punkt führt die steigende Komplexität der Systeme oft zu einem Sicherheitsparadoxon: Mehr Funktionalität führt nicht automatisch zu mehr Sicherheit, sondern kann das gesamte System anfälliger machen. Auch die zunehmende Abhängigkeit von externen Datenbanken kann zum Problem werden, wenn diese Quellen nicht regelmäßig auf ihre Integrität überprüft werden. Ein typisches Szenario sind veraltete oder widersprüchliche Informationen, die nicht korrekt herausgefiltert werden. Für den Nutzer entsteht so die Illusion, vertrauenswürdige und verifizierte Inhalte zu erhalten, obwohl im Hintergrund veraltete oder irreführende Daten genutzt werden.
Eine weitere Herausforderung ist die Schwierigkeit, die Herkunft und Qualität der abgerufenen Informationen transparent zu machen. In reinen LLM-Anwendungen lassen sich Antworten zwar nicht immer lückenlos nachvollziehen, doch bei RAG-Systemen sollte eigentlich die Quelle der zusätzlichen Daten klar dokumentiert sein. Diese Nachvollziehbarkeit ist essenziell, um Sicherheit und Vertrauenswürdigkeit zu gewährleisten. Jedoch existieren derzeit kaum standardisierte Ansätze, die dabei helfen, die Abrufquellen transparent zu machen und zu validieren. Damit bleibt ein wachsendes Vertrauensdefizit bestehen.
Darüber hinaus zeigt sich, dass RAG-Systeme das Risiko von unbeabsichtigten Leaks und Datenschutzverletzungen erhöhen können. Da externe Wissensquellen oft personenbezogene Daten oder sensible Informationen enthalten, besteht die Gefahr, dass solche Daten unbeabsichtigt in generierten Texten auftauchen. Besonders kritisch ist das, wenn das Retrieval-System auf unsichere oder unzureichend geschützte Datenbanken zugreift. Auch die Gefahr von sogenanntem Prompt Injection, bei dem Eingaben des Nutzers so gestaltet werden, dass unerwünschte Systemreaktionen ausgelöst werden, wird durch RAG nicht grundsätzlich reduziert. Vielmehr können komplexe Interaktionen zwischen Retrieval und LLM dazu führen, dass Schadcode oder Manipulationsversuche sich leichter verstecken oder ausnutzen lassen.
Sicherheitsforschung warnt daher davor, dass eine nahtlose Integration von Retrieval-Komponenten in LLMs ohne robuste Sicherheitsmechanismen und Monitoring leicht kontraproduktiv sein kann. Statt einer Verbesserung der Sicherheit kann dies schnell zu einem paradoxen Effekt führen, bei dem vermeintlich intelligente Systeme verlässlicher wirken, in Wahrheit aber fehleranfälliger und manipulierbarer sind. Aus Sicht von Entwicklern und Anwendern ist es deshalb unabdingbar, die Sicherheitsaspekte von RAG kritisch zu hinterfragen und mit gezielten Maßnahmen gegenzusteuern. Dazu gehören regelmäßige Audits der genutzten Datenquellen, Implementierung von Filtermechanismen zur Erkennung und Vermeidung von toxischen oder irreführenden Inhalten, sowie transparente Dokumentationen zu Herkunft und Verarbeitungsprozessen. Zivilgesellschaft, Wissenschaft und Unternehmenswelt sollten gemeinsam daran arbeiten, Standards und Normen für sichere, vertrauenswürdige RAG-Systeme zu etablieren, um das Potenzial dieser Technologien voll auszuschöpfen, ohne neue Gefahren zu schaffen.