Die rasante Entwicklung von Großsprachmodellen (LLMs) hat die Art und Weise, wie Wissen verarbeitet und angewandt wird, grundlegend verändert. Vor allem im Bereich der Chemie zeigt sich ein bemerkenswertes Potenzial dieser Systeme, komplexe Fragestellungen zu verstehen und Lösungen zu liefern. Doch wie schlägt sich die künstliche Intelligenz im direkten Vergleich mit den Fähigkeiten erfahrener Chemiker? Und in welchen Bereichen sind Modelle bereits heute überlegen, wo bleiben sie noch weit hinter menschlichen Experten zurück? Großsprachmodelle basieren auf maschinellem Lernen und werden mit gigantischen Mengen an Textdaten trainiert, die unter anderem auch chemische Fachliteratur, Lehrbücher, Forschungsergebnisse und Datenbanken umfassen. Diese Modelle sind in der Lage, natürlichsprachliche Eingaben zu interpretieren und darauf basierend Antworten oder Vorschläge zu generieren. Die jüngsten wissenschaftlichen Untersuchungen zeigen, dass einige dieser Modelle, wenn sie speziell auf chemische Fragestellungen angewendet werden, selbst Experten übertreffen können.
Doch die Erfolgsbilanz ist differenziert und eröffnet spannende Perspektiven für Forschung und Lehre. Eine bedeutsame Entwicklung in diesem Kontext ist das Benchmarking-Framework ChemBench. Dieses automatisierte Bewertungssystem wurde entwickelt, um chemisches Wissen und die deduktiven Fähigkeiten von LLMs umfassend mit denen von menschlichen Chemikern zu vergleichen. Das System enthält tausende sorgfältig kuratierte Frage-Antwort-Paare, die ein breites Themenspektrum der Chemie abdecken – von Basiswissen bis zu komplexen, intuitiven und rechnerisch anspruchsvollen Problemen. Die Datenbasis von ChemBench umfasst dabei nicht nur Multiple-Choice-Fragen, wie sie in herkömmlichen Prüfungen üblich sind, sondern auch offene Fragestellungen, die eine ausführlichere Beantwortung erfordern.
Das erlaubt eine realistischere Einschätzung der tatsächlichen Kompetenzen der Modelle, da in der Praxis selten nur vorgegebene Antwortoptionen verwendet werden. Die Schwierigkeit der Fragen reicht von einfachen Fakten bis hin zu anspruchsvollen Problemstellungen, die etwa das Erkennen spezieller Isomerieformen, das Vorhersagen von NMR-Spektren oder das Bewerten der Toxizität von Substanzen betreffen. Die Analyse der Ergebnisse zeigt, dass führende LLMs in der Summe viele der gestellten Fragen mit hoher Genauigkeit beantworten und dabei in bestimmten Bereichen sogar besser sind als die besten befragten Chemiker. Dies gilt insbesondere für Wissensfragen, die mit Hilfe umfangreichen Textmaterials trainiert wurden. Die Fähigkeit zur schnellen Wiederholung und Verknüpfung von Fakten macht die Modelle hier zum unschätzbaren Hilfsmittel.
Dennoch bleiben fundamentale Schwächen bestehen, insbesondere wenn es um tiefergehendes chemisches Verständnis und schlussfolgerndes Denken geht. Beispielsweise haben die Modelle Schwierigkeiten bei Aufgaben, die das systematische Ableiten von Informationen aus strukturellen Darstellungen von Molekülen erfordern. Das betrifft etwa die korrekte Vorhersage der Anzahl der verschiedenen Signale in einem Kernspinresonanzspektrum – ein typisches Problem der analytischen Chemie. Hier kann ein menschlicher Chemiker aus seiner Intuition und langjähriger Erfahrung oft Zusammenhänge erschließen, die einem Modell, das primär auf Textdaten basiert, schwerfallen. Auch bei Themenbereichen wie Sicherheit und Toxizität fällt auf, dass die Modelle noch häufig falsche oder übermäßig selbstsichere Antworten liefern.
Ein weiterer Herausforderungspunkt ist die Einschätzung der eigenen Antwortsicherheit. Während Menschen im Allgemeinen recht gut beurteilen können, wann sie eine Frage richtig beantworten und wann nicht, fehlt vielen LLMs eine zuverlässige Unterscheidung zwischen sicheren und unsicheren Prognosen. Das bedeutet, dass sie oft mit hoher Selbstsicherheit inkorrekte Informationen präsentieren. Für sensible Fragestellungen, etwa im Bereich des chemischen Gesundheitsschutzes, birgt dies ein erhebliches Risiko und erfordert sorgfältige menschliche Überprüfung der automatisierten Ergebnisse. Interessant ist auch die Erkenntnis, dass die Leistungsfähigkeit der LLMs stark mit ihrer Größe und Komplexität korreliert.
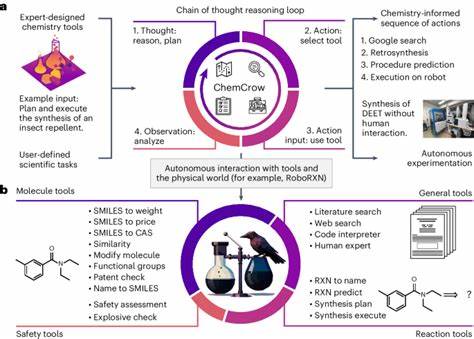
Größere Modelle erzielen tendenziell bessere Ergebnisse, was die Bedeutung von Rechenleistung und Datenmenge für die Weiterentwicklung der Werkzeuge hervorhebt. Zugleich zeigen Untersuchungen, dass reine Datenmenge allein nicht genügt, um systematisch vollständiges chemisches Verständnis zu erreichen. Hier sind modelleigene architektonische Verbesserungen sowie gezielte Trainingsstrategien insbesondere mit spezialisierten chemischen Datenbanken und Formaten gefragt. Die Praktikabilität der LLM-Anwendungen in der Chemie zeigt sich nicht nur in der reinen Wissensabfrage, sondern auch in der Unterstützung realer Forschungsprozesse. So können LLMs in Verbindung mit externen Tools, beispielsweise Suchmaschinen oder Rechen-Engines, sehr komplexe Fragestellungen autonom bearbeiten.
Sie sind zunehmend in der Lage, Vorschläge für chemische Synthesen, Materialentwicklung oder Laborautomatisierung zu erzeugen. Dieses Potenzial wird bereits von einigen innovativen Projekten genutzt, die auf eine teilautonome Steuerung von Experimenten oder die automatische Explikation wissenschaftlicher Texte setzen. Die Debatte um die Rolle von KI-Systemen in der Chemie berührt allerdings auch ethische und sicherheitsrelevante Aspekte. Neben den Chancen, etwa für schnellere Entdeckung neuer Medikamente oder nachhaltiger Materialien, besteht das Risiko des Missbrauchs. Dies betrifft beispielsweise die Möglichkeit, toxische Substanzen oder potenziell gefährliche chemische Prozesse zu entwerfen.
Hier ist eine verantwortungsbewusste Steuerung und Regulierung von entscheidender Bedeutung, um den Schutz von Öffentlichkeit und Umwelt zu gewährleisten. Angesichts der beeindruckenden Fortschritte, aber auch der bestehenden Schwächen, zeichnen sich klare Implikationen für die Chemieausbildung ab. Das reine Auswendiglernen von Fakten wird für Menschen künftig weniger relevant sein, da Maschinen dies effizient übernehmen. Stattdessen gewinnt die Fähigkeit, kritisch zu reflektieren, komplexe Sachverhalte zu interpretieren und kreative Lösungswege zu entwickeln, an Bedeutung. Dabei können KI-basierte Systeme als Kooperationspartner dienen, die den Menschen entlasten und ihm helfen, neue Erkenntnisse aus großen Datenmengen zu gewinnen.
Zudem ist die Standardisierung und Entwicklung weiterer Benchmarks wie ChemBench zentral, um den Fortschritt im Feld messbar zu machen. Nur mit klaren Bewertungskriterien kann die Leistung neuer Modelle transparent eingeschätzt und gezielt verbessert werden. Ebenso wichtig ist die Offenlegung von Daten und Code, um eine breite wissenschaftliche Zusammenarbeit zu ermöglichen und die Qualität der Modelle zu sichern. Zusammenfassend lässt sich festhalten, dass Großsprachmodelle in der Chemie heute schon eine beeindruckende Bandbreite an Aufgaben bewältigen und in vielen Bereichen Expertenwissen erreichen oder übertreffen. Dennoch sind sie keine vollständigen Ersatzsysteme für menschliche Chemiker, sondern ergänzen deren Fähigkeiten auf vielseitige Weise.
Die Zukunft der chemischen Forschung und Lehre wird vermutlich eine enge Symbiose zwischen Mensch und Maschine darstellen, in der KI-Systeme Werkzeuge für effizientes Arbeiten, Entdeckungen und Bildung sind. Kritisches Denken, ethische Verantwortung und Fachwissen bleiben jedoch unverzichtbar, um die Möglichkeiten der künstlichen Intelligenz sicher und sinnvoll zu nutzen.