In den letzten Jahren hat die Künstliche Intelligenz enorme Fortschritte gemacht und beinahe alle Bereiche unseres Lebens durchdrungen. Von der automatisierten Sprachverarbeitung bis hin zur Bildanalyse – KI scheint allgegenwärtig und allmächtig. Doch trotz dieser rasanten Entwicklung steht die Branche 2024 an einem entscheidenden Wendepunkt: Generalistische KI, also Modelle, die möglichst viele Aufgaben mit einem einzigen System bewältigen sollen, stößt zunehmend an ihre Grenzen. Die Frage, warum diese Modelle nicht mehr effizient skalieren, beschäftigt Entwickler, Unternehmen und Investoren weltweit. Die Antwort darauf ist nicht nur technisch, sondern hat weitreichende ökonomische und gesellschaftliche Implikationen.
Kern des Problems ist die exponentielle Zunahme der benötigten Rechenleistung, wenn Modelle immer größer und umfassender werden. Allgemein betrachtet baut das Training eines KI-Modells in der Größenordnung von N Parametern darauf auf, mit immer mehr Trainingsdaten das Modell so anzupassen, dass es präzisere und verlässlichere Ergebnisse liefert. Dabei ist die Anzahl der Parameter oft immens, um eine akzeptable Generalisierbarkeit zu erreichen. Ein kritischer Aspekt ist, dass der Trainingsaufwand in der Regel quadratisch zur Größe der Modellparameter steigt, also O(N^2). Das bedeutet, dass eine Verdopplung der Modellgröße nicht nur die Trainingszeit verdoppelt, sondern vervierfacht.
Die damit verbundenen Kosten und der Stromverbrauch explodieren förmlich. NVIDIA und andere Marktriesen der Halbleiterindustrie erleben dies selbst hautnah. Deren Markwert und Zukunftsaussichten hängen stark vom Bedarf an hochleistungsfähiger Grafik- und Rechentechnologie für KI ab. Doch genau hier droht ein unüberwindbares Hindernis. Die finanzielle und ökologische Belastung durch immer größere und komplexere generalistische Modelle lässt sich nicht unbegrenzt steigern.
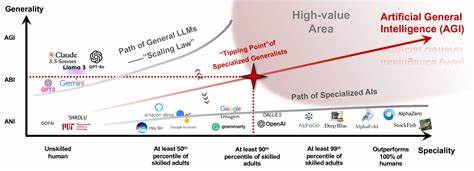
Die Halbleiterindustrie steht daher vor der Herausforderung, diese Wachstumsspirale zu durchbrechen oder Technologien grundlegend zu verändern. Ein weiterer limitierender Faktor ist die Verfügbarkeit von qualitativ hochwertigem Trainingsmaterial. Während Anwendungen wie Schach- oder Go-Modelle noch relativ einfach durch selbstspielende Systeme kontinuierlich neue Daten generieren können, sind tiefgründige und vielfältige Trainingsdaten für allgemeinwissensbasierte Modelle stark beschränkt. Lehrbücher, wissenschaftliche Artikel und allgemeine Wissensquellen bieten nur einen endlichen Pool an Informationen, der für die stetig wachsenden Anforderungen nicht ausreichend ist. Angesichts dieser Herausforderungen rückt eine alternative Herangehensweise immer stärker in den Fokus: der Wandel von generalistischen KI-Modellen hin zu spezialisierten Expertensystemen.
Diese Idee beruht auf der Prämisse, dass es oftmals sinnvoller und effizienter ist, einzelne Teilbereiche gezielt mit spezialisierten Modellen abzudecken, anstatt ein riesiges Allzweckmodell zu trainieren. Dabei wird die Gesamtanzahl der Modellparameter in mehrere kleinere Einheiten unterteilt, die jeweils auf spezialisierte Domänen trainiert werden. Technisch betrachtet reduziert sich dadurch die Trainingskomplexität pro Submodell erheblich. Statt ein Modell der Größe N mit O(N^2) Aufwand zu trainieren, lässt sich das Problem in k kleinere Modelle untergliedern, die jeweils N/k Parameter besitzen. Die exponentielle Kostenzunahme beim Training verringert sich somit mathematisch auf O(N^2/k).
Dies bedeutet eine massive Skaleneffizienz, ohne dass der Gesamtumfang der notwendigen Daten und Parameter verloren geht. Die Submodelle, etwa für Medizin, moderne Kunst oder andere Wissensgebiete, können in hoher Qualität trainiert werden, ohne in die Kosten- und Rechenfalle eines riesigen Generalisten zu tappen. Natürlich besteht bei dieser stark spezialisierten Herangehensweise das Risiko, dass das Modell weniger flexibel wird bei der Kombination von Wissen aus verschiedenen Bereichen. Moderne Kunst, die Polypeptide darstellt – ein Beispiel für eine Schnittmenge verschiedener Disziplinen – könnte einer solchen spezialisierten KI eventuell schwer fallen. Dennoch zeigt sich in der Praxis, dass viele Anfragen sehr gut durch explizite Spezialistenmodelle beantwortet werden können.
Dieses Vorgehen entspricht auch dem menschlichen Wissenserwerb: während eine Einzelperson viele Themen nur oberflächlich kennt, können Experten aus verschiedenen Fachgebieten in einer Gruppe gemeinsam tiefgreifende Antworten liefern. Um die Zusammenarbeit der Expertenmodelle zu erleichtern, kann zusätzlich ein sogenannter „Dispatcher“ oder Vermittler entwickelt werden. Dieses Submodell erkennt die Art der Anfrage und leitet sie an den jeweils geeigneten Experten weiter. So entsteht eine effiziente, modulare Architektur, die sowohl Skalierbarkeit als auch Qualität sicherstellt. Ein solcher Weg birgt nicht nur technische Vorteile, sondern hat auch ökonomische Relevanz.
Geringere Trainingskosten, schnellere Modellaktualisierungen und weniger Energieverbrauch machen spezialisierte Modelle gegenüber generalistischen Systemen attraktiver. Zudem kann durch die Nutzung mehrerer Expertensysteme eine größere Gesamtintelligenz realisiert werden, die einzelne Generalisten übertrifft, weil sie gezielter auf spezifische Aufgaben zugeschnitten ist. Aus Sicht der Forschung und Entwicklung ergeben sich zudem interessante Perspektiven. Kleine, spezialisierte Teams können gezielter auf ihre Domänen eingehen, ohne die komplexen Anforderungen eines riesigen Generalisten stemmen zu müssen. Auch Innovationen lassen sich so schneller integrieren, da Updates nicht das gesamte System betreffen, sondern nur einzelne Module.
Letztlich steht die KI-Branche 2024 an einem Scheideweg. Die Idee der gigantischen Allzweck-KI wird durch wirtschaftliche und physikalische Gesetzmäßigkeiten begrenzt. Die alternativen Wege, über eine modulare und spezialisierte Architekturen zu künstlicher Intelligenz zu gelangen, zeigen vielversprechende Ansätze, um das Potenzial von KI nachhaltig und effizient zu entfalten. Allgemein gilt: Spezialisierung ist keine Einschränkung, sondern die Antwort auf die Frage nach dem langfristigen Erfolg von KI-Systemen. Die Zukunft der Künstlichen Intelligenz wird daher aller Wahrscheinlichkeit nach von einer intelligent vernetzten Gemeinschaft spezialisierter Expertenmodelle geprägt sein.
Das Zusammenspiel der spezialisierten Systeme und ihrer Vermittler-Instanzen eröffnet nicht nur bessere Skalierbarkeit, sondern auch vielfältigere Anwendungsmöglichkeiten. Unternehmen, Investoren und Forscher sollten diesen Wandel als Chance sehen, die KI-Entwicklung auf ein neues Level zu heben und zugleich verantwortungsvoller mit Ressourcen und Daten umzugehen. Zusammenfassend lässt sich sagen, dass die Zeiten der großen Generalisten-Modelle zwar beeindruckend waren, sich aber im Jahr 2024 aus wirtschaftlichen, technischen und ökologischen Gründen nicht mehr als langfristige Lösung bewähren. Die Spezialisierung übernimmt zunehmend das Ruder und ebnet den Weg für leistungsfähigere, kosteneffizientere und nachhaltigere KI-Architekturen – eine Entwicklung, die auch die Art und Weise, wie wir mit KI interagieren, grundlegend verändern wird.