Die rasante Entwicklung und Verbreitung großer Sprachmodelle, auch bekannt als LLMs (Large Language Models), haben die Art und Weise, wie Menschen mit Technologie interagieren, grundlegend verändert. Von automatisierten Chats bis hin zu komplexen Textanalysen und kreativen Vorschlägen – die Einsatzmöglichkeiten sind enorm vielfältig. Gleichzeitig wächst die Sorge um die Privatsphäre der Nutzer, da viele dieser Anwendungen auf Cloud-Services und externe Server angewiesen sind, um ihre Rechenleistung und Funktionalität bereitzustellen. Die Frage, wie viel Vertrauen man großen Technologieanbietern bei der Verarbeitung persönlicher und oft sensibler Daten entgegenbringen kann, wird immer drängender. Zudem stellt sich die Frage, wie bewusst sich Nutzer über die Datenflüsse sind und welche Maßnahmen Entwickler ergreifen, um Datenschutz zu gewährleisten.
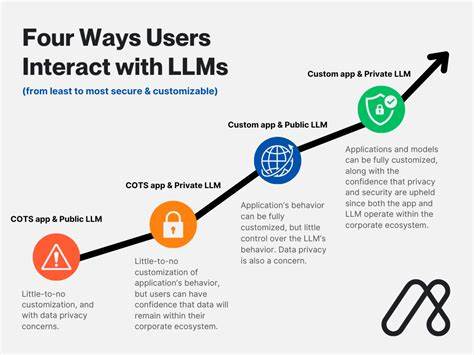
Nutzererwartungen und technologische Realitäten stehen hier oft im Spannungsfeld. Betrachtet man die Perspektiven von Nutzern und Entwicklern, offenbaren sich verschiedene Spannungsfelder, die es genauer zu beleuchten gilt. Viele der großen LLM-Dienstleister wie OpenAI, Anthropic oder Google bieten leistungsstarke APIs, die den Zugang zu KI-Funktionalitäten vereinfachen. Allerdings bedeutet das auch, dass sämtliche Anfragen, inklusive aller Eingaben – sei es ein harmloser Chat oder vertrauliche Informationen – an entfernte Server gesendet werden. Dort werden sie verarbeitet, um eine Antwort zu generieren.
Die Infrastruktur umfasst häufig mehrere Dritte, da etwa Cloudanbieter oder Partnerunternehmen beteiligt sind. Für Nutzer ergibt sich daraus ein Transparenzproblem: Wer hat Zugriff auf welche Daten? Wie lange werden die Daten gespeichert? Werden die Daten tatsächlich nur zur Modellverbesserung genutzt oder könnten sie auch anderweitig verwendet werden? Einige Anbieter veröffentlichen Datenschutzerklärungen und Richtlinien zur Datenverwendung, doch das Verständnis dieser Texte ist für den durchschnittlichen Nutzer oft schwierig. Das Bewusstsein über die potenziellen Risiken und den Umgang mit persönlichen Daten ist damit begrenzt. Die Diskussion über Vertrauen gegenüber großen Anbietern ist seit jeher kontrovers. Manche User, wie einige Stimmen in der Entwickler-Community, zeigen sich äußerst skeptisch und lehnen die Nutzung von KI-Anwendungen ab, wenn sie personenbezogene Daten preisgeben müssen.
Diese Haltung ist geprägt von der Sorge, dass sensible Informationen missbraucht, weiterverkauft oder ohne Zustimmung für Trainingszwecke verwendet werden könnten. Dabei gibt es durchaus Parallelen zu anderen digitalen Diensten wie E-Mail-Providern, sozialen Netzwerken oder Suchmaschinen, bei denen Nutzer oft stillschweigend zustimmen, dass ihre Daten gesammelt und ausgewertet werden. Der Unterschied liegt allerdings darin, dass bei LLMs die Daten insbesondere verwendet werden, um die KI-Systeme selbst zu verbessern. Dies bringt eine besondere Gefahr mit sich, da Informationen dauerhaft in den Trainingsdaten verankert werden können – ohne eindeutige Kontrolle oder Löschmöglichkeit. Trotz der Risiken entwickeln viele Unternehmen Strategien, um den Datenschutz zu stärken.
Dazu zählt unter anderem die Anonymisierung von Daten, die Entfernung persönlich identifizierbarer Informationen vor der Speicherung sowie der Einsatz von lokalen Modellen, die komplett auf Nutzergeräten laufen können, ohne dass Daten das Gerät verlassen. Solche On-Premise-Lösungen haben zwar meist Einschränkungen bei der Leistungsfähigkeit, bieten dafür jedoch einen deutlich besseren Schutz der Privatsphäre. Darüber hinaus gewinnt die sogenannte „Privacy by Design“-Philosophie immer mehr an Bedeutung. Diese fordert, Datenschutz bereits bei der Entwicklung von Produkten zu berücksichtigen und nicht erst nachträglich als Zusatz zu integrieren. Dies könnte bedeuten, dass Abfragen minimiert, Protokolle verschlüsselt oder Transparenzberichte für Nutzer regelmäßig veröffentlicht werden.
Auf Seiten der Endanwender ist zudem wichtig, dass ein besseres Verständnis für die Datenverwendung geschaffen wird. Nutzer sollten über klare und verständliche Nutzungsbedingungen informiert sein. Auch die Möglichkeit, Anfragen und Verlauf einzusehen oder zu löschen, kann das Vertrauen fördern. Doch aktuell zeigen Umfragen und Diskussionen, dass bei vielen Nutzern das Bewusstsein für die Datenflüsse hinter LLM-Diensten noch begrenzt ist. Häufig sind die Beweggründe für die Nutzung solcher Dienste praktischer Natur – sei es Bequemlichkeit, Informationssuche oder kreative Unterstützung –, während die möglichen Folgen für die eigene Privatsphäre unterschätzt werden.
Experten warnen davor, gerade bei der Eingabe von sensiblen Informationen im Umgang mit LLMs vorsichtig zu sein. Dazu zählen etwa personenbezogene Daten, vertrauliche Geschäftsinformationen, Gesundheitsdaten oder juristische Details. Selbst wenn Anbieter versichern, dass solche Informationen nicht für andere Zwecke verwendet werden, bleibt ein Restrisiko, unter anderem durch Datenlecks oder Angriffe. Einige Diskussionsteilnehmer weisen außerdem auf den besonders gefährlichen Aspekt der Manipulation und Kontrolle durch große KI-Modelle hin. So könnten fremde Akteure mit Zugang zu personalisierten Informationen versuchen, Verhaltensmuster zu beeinflussen, falsche Informationen zu verbreiten oder gezielte psychologische Effekte zu erzielen.
Dies trägt zum allgemeinen Misstrauen gegenüber KI-Plattformen bei und verdeutlicht die gesellschaftlichen Herausforderungen dieser Technologie. Insgesamt zeigt sich ein komplexes Bild: Die Vorteile großer Sprachmodelle und deren Nutzen sind groß und vielfältig, doch sie bringen gleichzeitig erhebliche Herausforderungen im Bereich Datenschutz mit sich. Für Entwickler und Unternehmen gilt es, einerseits technisch und organisatorisch sichere Systeme anzubieten und andererseits Nutzer umfassend aufzuklären. Für Anwender ist es ratsam, sich bewusst mit den Risiken auseinanderzusetzen und bei sensiblen Themen genau hinzusehen, welche Dienste sie nutzen und wie diese ihre Daten behandeln. Nur durch ein ausgewogenes Verhältnis von Innovation und Datenschutz kann das Potenzial von LLMs langfristig verantwortungsvoll ausgeschöpft werden.
Die Diskussion über LLMs und Privatsphäre wird sich mit der weiteren technologischen Entwicklung und zunehmender Regulierung vermutlich noch intensivieren. Initiativen für strengere Datenschutzvorgaben, wie sie beispielsweise in der Europäischen Union bereits mit der Datenschutzgrundverordnung (DSGVO) gelten, könnten ein wichtiger Schritt sein, um den Schutz der Nutzerrechte zu verbessern – auch im Kontext moderner KI-Systeme. Ebenso ist die Zusammenarbeit zwischen Technikern, Datenschutzexperten, Juristen und der Öffentlichkeit essenziell. Nur so lassen sich praktikable Lösungen finden, die dem Schutz der Privatsphäre gerecht werden und zugleich die Innovationen im Bereich künstlicher Intelligenz fördern. Abschließend lässt sich festhalten, dass der bewusste Umgang mit persönlichen Daten im Kontext großer Sprachmodelle eine immer wichtigere Grundlage für eine vertrauenswürdige und sichere digitale Zukunft bildet.
Offenheit, Transparenz und technologische Vorsicht sind dabei zentrale Werte, die es zu kultivieren gilt, um die Chancen dieser revolutionären Technologie verantwortungsvoll zu nutzen und gleichzeitig die Privatsphäre jedes Einzelnen zu schützen.