In der heutigen digitalisierten Welt generieren Unternehmen kontinuierlich enorme Mengen an Log-Daten. Diese dienen nicht nur der Fehlerbehebung und Überwachung, sondern spielen auch eine entscheidende Rolle bei der Sicherheitsanalyse und der Einhaltung gesetzlicher Vorgaben. Die Herausforderung besteht darin, diese riesigen Datenmengen effizient zu speichern und gleichzeitig die Kosten im Rahmen zu halten, ohne die Verfügbarkeit der Daten zu beeinträchtigen. Intelligentes Tiering, eine Methode, die ursprünglich im Kontext von Cloud-Speicherlösungen wie Amazon S3 Intelligent-Tiering bekannt wurde, erlangt zunehmend Aufmerksamkeit für den Bereich der Log-Datenverwaltung. Dabei handelt es sich um die automatische Verschiebung von Daten zwischen verschiedenen Speicherebenen je nach Zugriffshäufigkeit und Alter der Daten, um Kosten zu optimieren und Performance zu sichern.
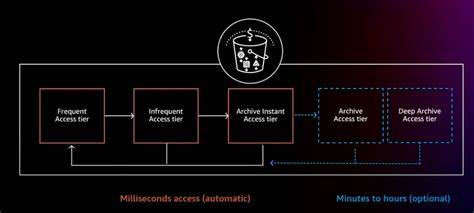
Viele Unternehmen stehen vor der Frage, ob und wie sich ein solches intelligentes Tiering für Logs implementieren lässt und welche Vorteile es bringt. Die Speicherung von Daten in „heißen“, „warmen“ und „kalten“ Speicherbereichen ist mittlerweile eine bewährte Methode, um Log-Daten effizient zu verwalten. Heißer Speicher zeichnet sich durch schnellen Zugriff aus, ist aber kostenintensiv. Er wird für Logs genutzt, die aktuell benötigt werden – beispielsweise für die unmittelbare Fehlersuche oder für Monitoring-Aufgaben in Echtzeit. Warmer Speicher ist preislich günstiger, hat jedoch längere Zugriffszeiten.
Hier landen Logs, die nicht mehr ständig, aber gelegentlich abgefragt werden. Kalter Speicher schließlich dient der langfristigen Archivierung von Logs, die selten benötigt werden, aber aufgrund von Compliance-Anforderungen und historischen Analysen erhalten bleiben müssen. In der Praxis bedeutet das, dass Unternehmen zunächst darüber nachdenken müssen, wie lange Logs wirklich häufig genutzt werden. Studien und Praxiserfahrungen zeigen, dass der Großteil der Abfragen auf Logs zugreift, die wenige Tage alt sind. Nach Ablauf dieses Zeitraums sinkt der Wert der Daten im Sinne der operativen Nutzung oftmals stark ab.
Die Nutzung von maßgeschneiderten Lagerstufen kann deshalb enorme Einsparungen ermöglichen. Ein konkretes Beispiel zeigt ein Startup namens Markhub, welches für seine Log-Daten einen dreistufigen Ansatz verfolgt. In einer heißen Phase von etwa sieben Tagen werden Logs in Elasticsearch gespeichert, einem leistungsfähigen, aber kostspieligen Such- und Analysewerkzeug. Für Logs im mittleren Alter von 7 bis 90 Tagen erfolgt der Transport zu Amazon S3 Standard Speicher mit Abfrage über Athena, ein SQL-ähnliches Analyse-Tool, das Abfragen auf Objektspeichern ermöglicht. Danach erfolgt eine Archivierung im S3 Glacier Deep Archive, die für die Langzeitspeicherung und Compliance genutzt wird.
Diese Strategie kombiniert Kostenersparnisse mit der erforderlichen Zugänglichkeit in unterschiedlichen Nutzungsszenarios. Diese Vorgehensweise basiert auf der Erfassung und Analyse der tatsächlichen Abfragehäufigkeit. Unternehmen, die ihre Zugriffsstatistiken auf Log-Daten überwachen, gewinnen wertvolle Erkenntnisse, um ihre Speicherebenen sinnvoll zu staffeln. Eine regelmäßige Auswertung der Nutzeranfragen anhand von Log-Daten und Suchanfragen ermöglicht es, den Zeitraum für die heiße Speicherung dynamisch festzulegen. Ebenso hilft es dabei, die Anforderungen an den warmen und kalten Speicher zu definieren, ohne wichtige Daten vorschnell zu löschen oder unnötig lange kostspielig vorzuhalten.
Technisch setzt die Umsetzung intelligenter Tiering-Konzepte oft auf bestehende Tools aus dem Open-Source-Ökosystem wie Fluentd oder Logstash zum Transport und zur Transformation der Daten. Diese Komponenten können automatisiert Logs archivieren oder rehydrieren, je nachdem, wie sie in der Tiering-Struktur benötigt werden. Auch die Cloud-Anbieter bieten zunehmend Möglichkeiten, die Lifecycle-Management-Policies auf Objektspeicher anzuwenden, sodass der automatische Übergang der Daten in günstigere Speicherklassen ohne manuellen Eingriff möglich ist. Dabei ist wichtig, dass das System flexibel auf individuelle Geschäftsbedürfnisse und Compliance-Richtlinien reagiert. Gerade im Bereich von Sicherheitsdaten oder gesetzlich vorgeschriebenen Aufbewahrungsfristen muss das Late-Archiving und das „Break Glass“-Szenario gut durchdacht sein.
Eine weitere Herausforderung ist, dass einige klassische Log-Verwaltungssysteme bislang vor allem statische Retention-Policies bieten. Ein dynamisches intelligentes Tiering, das bei wechselnden Zugriffsmustern automatisch reagiert, ist noch nicht in allen Plattformen integraler Bestandteil. Splunk hat zwar teilweise bereits Lösungen in diese Richtung entwickelt, doch in der gängigen Praxis dominieren statische Regeln, die nicht immer optimal auf die tatsächliche Nutzung abgestimmt sind. Hier ist die Kombination moderner Analyse- und Cloud-Speicher-Technologien oft der Schlüssel zur Effizienzsteigerung. Es ist auch essentiell, zwischen structurierten und unstrukturierten Log-Daten zu unterscheiden, da diese unterschiedliche Speicheranforderungen haben können.
Strukturierte Logs lassen sich leichter indizieren und mit Tools wie Elasticsearch blitzschnell durchsuchen, während unstrukturierte Daten oft größere Mengen an Rohdaten darstellen, die kostengünstig archiviert werden sollten. Intelligente Tiering-Strategien sollten daher auch technisch auf die Art der Log-Daten eingehen, da sie den Speicherbedarf, die Komprimierungsmethoden und das Zugriffsverhalten maßgeblich beeinflussen. Unternehmen, die tiefgehende Analysen und Monitoring betreiben, profitieren zudem von der Möglichkeit, Logs für eine bestimmte Zeit auf schnellerem Speicher vorzuhalten und so schnelle Reaktionszeiten bei Fehlern oder Sicherheitsvorfällen zu gewährleisten. Die gleichzeitige Verlagerung älterer Daten auf günstigere Speicherklassen entlastet das Budget ohne die operativen Abläufe zu beeinträchtigen. Dadurch wird ein optimaler Kompromiss zwischen Performance und Kosten hergestellt, der gerade für schnellwachsende Unternehmen mit großen Datenmengen essenziell ist.
In Kombination mit Data-Lifecycle-Management-Systemen und intelligenten Datenklassifikationsmechanismen kann das Tiering automatisiert und kontinuierlich optimiert werden. Machine Learning Ansätze für die Vorhersage von Zugriffsverhalten und Anomalien in Log-Daten sind auf dem Vormarsch und könnten zukünftig die Datenebenen noch intelligenter steuern. Automatische Migration von Daten aus heißen in kalte Speicher ohne menschliches Eingreifen ermöglicht eine deutlich effizientere Nutzung der Ressourcen. Insgesamt zeigt sich, dass intelligentes Tiering für Logs eine praktikable und wirtschaftliche Lösung im Umgang mit den exponentiell wachsenden Datenmengen darstellt. Es erfordert jedoch ein Umdenken in der Architektur und der Implementierung von Log-Management-Systemen.