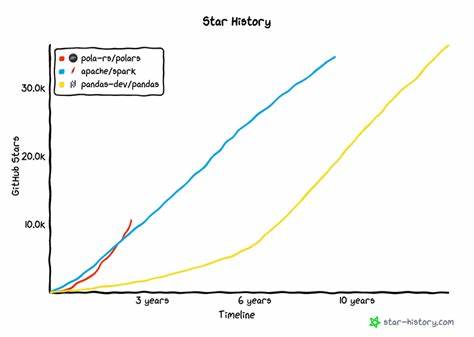
Die Datenverarbeitung hat sich in den letzten Jahren rasend schnell entwickelt. DataFrames sind zu einem unverzichtbaren Werkzeug für Data Scientists, Analysten und Ingenieure geworden, denn sie erlauben effiziente und strukturierte Handhabung von großen Datenmengen. Während Pandas jahrzehntelang als Standard galt, erschließen moderne Bibliotheken wie Polars, PySpark oder DuckDB immer mehr Anwendungsbereiche, die mit traditionellen Methoden schwer zu bewältigen sind. Doch genau darin liegt eine Herausforderung: Die Vielzahl verschiedener DataFrame-Bibliotheken mit jeweils eigenen APIs führt häufig zu inkompatiblen Codebasen, mehrfacher Implementierung von Funktionen oder gar zu Technologie-Lock-ins. Eine Antwort auf diese Problematik liefert Narwhals – eine leichte und vielseitige Kompatibilitätsschicht, die es erlaubt, DataFrame-Operationen einheitlich über unterschiedliche Frameworks hinweg zu formulieren und auszuführen.
Narwhals erlaubt es, komplexe Datenmanipulationen einmal zu beschreiben und auf Pandas, Polars, PySpark, DuckDB, PyArrow und weitere anzuwenden. Damit wird der Code nicht nur wiederverwendbar, sondern bleibt auch robust gegenüber den stetigen Veränderungen der einzelnen Bibliotheken. Das Problem begann typischerweise damit, dass Entwickler entweder alle Daten in Pandas konvertieren mussten oder für jede Bibliothek eigene Funktionen schreiben mussten. Eine Funktion, die Daten gruppiert, aggregiert oder transformiert, musste also in vielen Varianten vorgehalten werden – was extrem wartungsintensiv und fehleranfällig ist. Die Umwandlung sämtlicher Eingabedaten ins Pandas-Format verhindert zwar meist Kompatibilität, kostet aber enorme Leistungseinbußen und verschenkt die Vorteile neuer Technologien wie GPU-Beschleunigung oder Lazy Evaluation.
Die Herangehensweise, für jede Bibliothek eigenen Code zu schreiben, ist zwar funktional, skaliert aber nicht mit dem wachsenden Ökosystem an DataFrame-Tools. Genau hier punktet Narwhals, indem es einen gemeinsamen API-Layer bereitstellt, der sich am Polars-API orientiert und somit modern, intuitiv und flexibel ist. Nutzer müssen ihre Logik nur einmal verfassen – die Konvertierung zu und von nativen DataFrames der verschiedenen Frameworks übernimmt Narwhals automatisch im Hintergrund. Das Ergebnis sind Funktionen mit klarer Struktur, typischerweise gruppiert nach gewissen Zeitpunkten, aggregierend oder filternd, die praktisch in jeder Umgebung laufen, ohne zusätzliche Abhängigkeiten. Ein weiterer Vorteil von Narwhals ist die Stabilität gegenüber Versionsänderungen der zugrundeliegenden Bibliotheken.
Da Library-APIs oft brechen oder sich ändern, führt das meist zu zahlreichen Code-Anpassungen in Projekten. Narwhals jedoch abstrahiert diese Unterschiede so, dass der programmierte Code mit alte wie auch neuen Versionen kompatibel bleibt und so die Wartung drastisch vereinfacht. Ein Beispiel für einen häufigen Anwendungsfall ist die monatliche Aggregation von Preisdaten über ein Zeitreihen-DataFrame. Ohne Narwhals müsste dafür für jede Bibliothek eigener Code erstellt werden, der die Gruppierung nach Datum steuert und Mittelwerte berechnet. Mit Narwhals sieht die Implementierung dagegen klar und elegant aus, basierend auf gemeinsamen Abstraktionen für Spalten und Aggregationsfunktionen.
Das macht nicht nur die Entwicklung schneller, sondern fördert auch eine bessere Zusammenarbeit zwischen Data-Science-Teams und Engineering-Bereichen, die unterschiedliche Frameworks favorisieren. Neben der Vereinfachung der Codebasis ermöglicht Narwhals auch die Nutzung von Performance-Optimierungen wie Lazy Evaluation in Polars oder die verteilte Verarbeitung in PySpark. Diese Vorteile gehen bei simplen Pandas-Konvertierungen meist verloren. Durch native Unterstützung werden alle Stärken der jeweiligen Frameworks voll genutzt, ohne die Komplexität für den Nutzer zu erhöhen. Narwhals gewinnt auch deshalb an Bedeutung, weil die Data-Engineering-Welt zunehmend diverser wird.
Teams, die früher ausschließlich mit Pandas arbeiteten, setzen heute parallel auf spezialisierte Tools. Eine Plattformübergreifende Lösung mit Zukunftssicherheit ist unverzichtbar, um Entwicklungsgeschwindigkeit und Codequalität zu gewährleisten. Neben den genannten Technologien stellt Narwhals derzeit auch Kompatibilität mit PyArrow und DuckDB bereit, weitere Frameworks sind in Planung. Für Unternehmen bedeutet das, bestehende Data Pipelines einfach zu modernisieren ohne große Refaktorierungen. Für Einzelentwickler ist es eine Möglichkeit, eigene Data-Science-Bibliotheken zukunftssicher und wartbar zu gestalten.
Wer sich für Narwhals entscheidet, profitiert von einer lebendigen und unterstützenden Community sowie von regelmäßigen Updates, die auf Innovation und Stabilität gleichermaßen ausgerichtet sind. Ergänzend zur API existieren ausführliche Dokumentationen, Beispiele und Tutorials, die den Einstieg erleichtern. Narwhals ist damit nicht nur ein praktisches Werkzeug, sondern auch ein beispielhafter Schritt hin zur Vereinheitlichung des DataFrame-Ökosystems. In einer immer komplexeren Datenwelt ist es essenziell, Werkzeuge zu haben, die Zusammenspiel, Wiederverwendbarkeit und langfristigen Support gewährleisten. Narwhals erfüllt diese Rolle und bietet Data Scientists und Entwicklern die Freiheit, ihre DataFrame-Logik ohne Einschränkungen zu gestalten und flexibel auf unterschiedlichste Anforderungen zu reagieren.
Letztlich ist Narwhals die Antwort auf die Frage, wie man moderne Datenanalyse in heterogenen und dynamischen Umgebungen nachhaltig gestalten kann. Durch seine Leichtgewichtigkeit, hohe Kompatibilität und Zukunftssicherheit eröffnet Narwhals neue Möglichkeiten zur effizienten DataFrame-Programmierung und vereinfacht den oft frustrierenden Anpassungs- und Wartungsaufwand erheblich. Damit ist Narwhals ein unverzichtbares Werkzeug für alle, die große Datenmengen mit verschiedenen Frameworks auf konsistente Weise verarbeiten möchten und gleichzeitig auf Performance, Flexibilität und Zukunftsfähigkeit Wert legen.