Die Wahl der richtigen Datenbank spielt eine zentrale Rolle für den Erfolg moderner Softwareprojekte. Insbesondere in wachstumsstarken Unternehmen führt der Umgang mit steigenden Datenmengen und Anforderungen an Verfügbarkeit und Geschwindigkeit zu einer kritischen Überprüfung des eingesetzten Datenbanksystems. Der Wandel vom Einsatz einer verteilten SQL-Datenbank wie CockroachDB hin zu einem klassischen relationalen System wie PostgreSQL ist dabei keine Seltenheit. Diese Migration bietet spannende Chancen, bringt aber auch technische Hürden mit sich, die es zu meistern gilt. CockroachDB hat sich in den letzten Jahren als eine äußerst attraktive Lösung etabliert.
Insbesondere zeichnet sich das System durch seine hohe Skalierbarkeit aus, da es von Haus aus für Multi-Region-Setups ausgelegt ist. Die Fähigkeit zur horizontalen Skalierung und die starke Ausfallsicherheit machen es vor allem für Cloud-basierte Anwendungen interessant. Außerdem bietet CockroachDB eine SQL-kompatible Schnittstelle, die den Einstieg erleichtert, wenn bereits mit gängigen relationalen Datenbanken gearbeitet wurde. Doch genau diese Vorteile schlagen in manchen Fällen auch in Nachteile um, insbesondere wenn das Anwendungsszenario nicht alle Features von CockroachDB erfordert. Die Nutzung einer verteilten Datenbank kann zu unverhältnismäßigen Kosten führen, vor allem wenn die Anwendung primär auf eine Region beschränkt ist und einfache transaktionale Abfragen durchführt.
In einem solchen Kontext kann ein klassisches System wie PostgreSQL nicht nur wirtschaftlicher, sondern auch performanter sein. Ein häufiges Problem bei CockroachDB sind zeitintensive Migrationen. Mit wachsendem Datenvolumen kommt es vor, dass bei Schemaänderungen und Migrationen teils lange Timeouts auftreten. Entwickler sehen sich dann gezwungen, Migrationen manuell und teilweise parallel auszuführen, was den Deploy-Prozess erheblich verzögert und das Risiko von Fehlern erhöht. Diese prozeduralen Engpässe führen nicht selten dazu, dass Entwickler aus Angst vor Systemblockaden den direkten Weg in die Datenbank umgehen und Teile der Logik aus der Datenbank in die Anwendungsschicht verlagern – eine Praxis, die langfristig die Wartbarkeit erschwert.
Die fehlende oder unzureichende Unterstützung von ETL-Werkzeugen stellt ein weiteres Hemmnis dar. Während sich CockroachDB vor allem durch seine verteilte Architektur auszeichnet, ist der Markt für robuste ETL-Lösungen und Datenreplikation im Ökosystem noch vergleichsweise jung. Es gibt zwar Lösungen wie Airbyte, diese befinden sich jedoch häufig im Alpha-Stadium oder weisen Probleme wie Speicherlecks auf, was bei produktiven ETL-Workflows zu wiederholten Ausfällen und Performanceproblemen führt. Interessant wird es bei der Abfrageperformance. CockroachDB beeindruckt mit einem intelligenten Query Planner, der komplexe Abfragen in einigen Fällen sogar schneller ausführt als PostgreSQL.
Dennoch zeigen sich in der Praxis oft genau die gegenteiligen Effekte. Komplexe, durch ORMs wie Prisma generierte SQL-Anweisungen verursachen in der verteilten Architektur besonders hohe Latenzen. Häufig führt dies zu Full Table Scans, die erhebliche Ressourcen binden und in CockroachDB zu spürbaren Performanceeinbrüchen führen – mitunter um den Faktor zwanzig langsamer als vergleichbare Abfragen auf PostgreSQL. Nicht zu vernachlässigen sind außerdem praktische Aspekte rund um den Entwicklungsalltag. Die CockroachDB-Konsole zur Abbruch laufender Queries ist umständlich und erfordert ein hohes Maß an Koordination, da die Clusterstruktur das Finden und Beenden einer abgebrochenen Abfrage auf allen Knoten verlangt.
Entwicklern fehlt zudem eine nahtlose und benutzerfreundliche Oberfläche. Support und Dokumentation verteilen sich auf getrennte Plattformen mit langsamen Reaktionszeiten, was gerade bei kritischen Problemen die Handlungsfähigkeit einschränkt. Auch die Netzwerkstabilität spielt eine Rolle: Im Betrieb mit CockroachDB traten immer wieder sporadische Ausfälle durch unerklärte Verbindungsprobleme mit DNS-Einträgen auf. Diese beeinträchtigten sowohl CI-Umgebungen als auch lokale Entwicklungsumgebungen und konnektorenbasierte Datenpipelines, was sich neben der reinen Performance negativ auf die Betriebsstabilität auswirkte. Die Migration selbst verdient eine besondere Betrachtung.
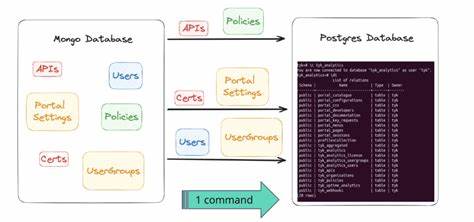
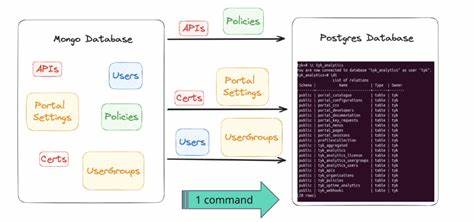
Bei enormen Datenbeständen im dreistelligen Millionenbereich ist der Übergang alles andere als trivial. Zudem zeigen sich bei der Übertragung von Datenstrukturen, insbesondere bei komplexen Typen wie JSON und Arrays, Inkompatibilitäten zwischen CockroachDB und PostgreSQL. Ein direkter Export-Import-Weg funktioniert nur mit aufwändigen Transformationen, die sicherstellen müssen, dass Dateninhalte beim Wechsel unverändert bleiben. Eine bewährte Taktik ist daher die Entwicklung einer maßgeschneiderten ETL-Pipeline, die sämtliche Daten zunächst in einem Zwischenschritt in kompatible Formate überführt. Etwa durch Skripte, die Daten als CSV-Dateien exportieren, anschließend zeilenweise einlesen und mit speziellen Parsern auf Vorfeld-Inkompatibilitäten prüfen und korrigieren.
Dies wird häufig durch parallele Prozesse beschleunigt, die jeweils einzelne Tabellen übernehmen, während die Daten anschließend sequenziell oder gleichzeitig in PostgreSQL eingefügt werden. Ein solches Verfahren erfordert neben technischem Know-how auch eine präzise Planung, um Ausfallzeiten möglichst kurz zu halten. Idealerweise wird die Migration in Wartungsfenstern mit reduzierter Nutzeraktivität durchgeführt. Industrieerfahrungen zeigen, dass bei gut vorbereiteten Projekten eine Migration großer Datenbanken mit hundert Millionen Reihen in wenigen Minuten bis zu einer Stunde realisierbar ist. Dabei ist ein schrittweises Hochfahren der Anwendung und eine gründliche Validierung der Datenintegrität essenziell.
Im Anschluss an die Migration profitieren Unternehmen von zahlreichen Vorteilen. Durch die Verlagerung zu PostgreSQL lassen sich nicht nur Hosting- und Lizenzkosten erheblich senken, sondern auch die Performance in der täglichen Nutzung verbessern. Die breite Unterstützung durch ein ausgereiftes Ökosystem an Tools ermöglicht eine effiziente Abfrageoptimierung, Monitoring und Wartung. Darüber hinaus sind Entwicklungsabläufe dank besserer Integrationen und stabilerer Schnittstellen deutlich angenehmer. Die Möglichkeit, Abfragen direkt zu pausieren, sich auf einer vertrauten SQL-Konsole zu bewegen und schnelleres Supportreaktionsverhalten zu erhalten, steigert die Produktivität der Entwicklerteams.
Die Erfahrungen zeigen, dass die Entscheidung für PostgreSQL insbesondere dann lohnt, wenn die Anwendung keine zwingenden Anforderungen an die Multi-Region-Verteilung stellt. Dort, wo überwiegend transaktionale Lasten vorliegen und die horizontale Skalierung nicht die oberste Priorität hat, sind klassische relationale Systeme in der Regel leistungsfähiger und kosteneffizienter. Für Unternehmen, die mit der Migration liebäugeln, ist es wichtig, frühzeitig den gesamten Prozess technisch genau zu planen. Eine umfassende Analyse der Datenstrukturen und Abfragen, verbunden mit einem konsequenten Testen von Migrationstools und – bei Bedarf – dem Aufbau eigener Import- und Konvertierungsskripte, ist unerlässlich, um unerwartete Ausfälle und Datenverluste zu vermeiden. Zusammenfassend lässt sich sagen, dass die Migration von CockroachDB zu PostgreSQL trotz einiger Herausforderungen eine sehr lohnenswerte Investition darstellt.
Neben erheblichen Kostenersparnissen bietet sie die Möglichkeit, Datenbankabfragen zu beschleunigen, den Betrieb zu vereinfachen und Entwicklungsteams produktiver arbeiten zu lassen. Wer diesen Weg einschlägt, sollte sich auf eine sorgfältige Planung, intensive Tests und eine Phase der Anpassung einstellen – am Ende steht jedoch eine stabilere, schneller skalierende und wirtschaftlichere Infrastruktur, die den ständig wachsenden Anforderungen moderner Anwendungen gerecht wird.