In der zunehmend digitalen Welt stellen Suchmaschinen einen zentralen Baustein für die Informationsbeschaffung dar. Die Erwartungen an Suchsysteme steigen stetig, insbesondere hinsichtlich der Schnelligkeit und Relevanz der Ergebnisse. Klassische Suchansätze, insbesondere die sogenannte Hybrid-Suche, die sowohl lexikalische als auch vektorbasierte Algorithmen kombiniert, stoßen jedoch immer häufiger an ihre Grenzen. Die Herausforderung besteht darin, eine ausgewogene Auswahl an Kandidaten zu treffen, die sowohl semantisch relevant als auch lexikalisch passend sind. An dieser Stelle gewinnen Two-Tower-Modelle erheblich an Bedeutung als effektive Alternative.
Sie ermöglichen es, komplexe Suchanfragen effizienter und präziser zu bearbeiten, indem sie die Verarbeitung von Dokumenten und Suchanfragen mithilfe von parallelen neuronalen Netzen optimieren. Hybrid-Suche bedeutet traditionsgemäß, dass eine lexikalische Filterung der Dokumente auf einer ersten Ebene erfolgt, beispielsweise durch Schlüsselwörter, die im Produkttitel oder in der Produktbeschreibung enthalten sind. Anschließend wird eine Rangordnung nach vektorbasierter Ähnlichkeit mit dem Suchbegriff vorgenommen. Damit wird versucht, die Suche möglichst genau und relevant zu gestalten. Die Problematik liegt darin, dass die Selektion der lexikalischen Kandidaten sehr granular und vielfältig sein kann – es werden viele unterschiedliche Kategorien, Attribute und Filter verwendet.
Dies führt zu einer enormen Komplexität, die sich schnell zur sogenannten „Chicken-und-Egg“-Situation hochschaukelt: Es müssen möglichst viele lexikalisch relevante Kandidaten gefunden werden, um ausreichend gute Vektor-Kandidaten zu generieren, doch die Menge der Kandidaten wächst exponentiell und wird damit unüberschaubar und langsam. Diese komplexe Situation macht es notwendig, die Art und Weise, wie Suchanfragen und Dokumente dargestellt und verarbeitet werden, grundlegend zu überdenken. Der vielversprechende Ansatz in diesem Zusammenhang besteht darin, weitere relevante Attribute und Merkmale nicht separat als Filter zu behandeln, sondern im Embedding zu konsolidieren. Somit wird die Filterung nicht als eigenständiger Schritt vor der semantischen Suche abgehandelt, sondern fließt direkt in die Erzeugung der semantischen Vektor-Repräsentation ein. Hier kommen Two-Tower-Modelle ins Spiel, die durch ihr paralleles Architekturdesign eine effektive, gemeinsame Repräsentation von Suchanfrage und Dokument erzeugen.
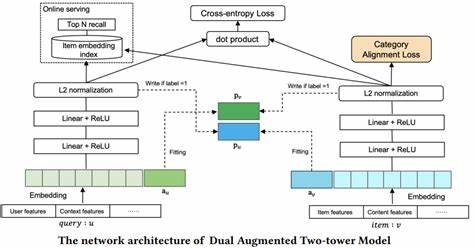
Das Grundprinzip von Two-Tower-Modellen besteht darin, Suchanfrage und Dokumente mithilfe separater, aber ähnlicher („twin“) neuronaler Netze zu verarbeiten. Diese sogenannten „Türme“ extrahieren jeweils Merkmale und erzeugen dichte Vektor-Embeddings, die im Anschluss miteinander verglichen werden. Im Gegensatz zu traditionellen Modellen, bei denen häufig die gesamte Abfrage-Dokument-Kombination gemeinsam verarbeitet wird, ermöglichen es die Two-Tower-Modelle, sowohl auf der Query-Seite als auch auf der Dokument-Seite eigenständige und zugleich koordinierte Darstellungen zu lernen. Der eigentliche Clou bei Two-Tower-Modellen ist die Verwendung eines sogenannten kontrastiven Lernansatzes. Dieser basiert auf einer gezielten Anpassung der Embeddings, sodass relevante Paare (etwa eine Suchanfrage und ein treffendes Produkt) im Vektorraum näher zusammenrücken, während irrelevante Paare weiter auseinandergedrängt werden.
Dieses Prinzip wird durch die kontrastive Verlustfunktion realisiert, die während des Trainings lernt, die Ähnlichkeiten im Embedding-Raum zwischen Suchbegriff und Dokumenten so zu optimieren, dass die Suchergebnisse nicht nur lexikalisch, sondern vor allem semantisch präzise und auf die jeweilige Anwendung zugeschnitten sind. Technisch gesehen basieren die Two-Tower-Modelle häufig auf leistungsstarken vortrainierten Transformermodellen wie BERT oder DistilBERT. Die Eingabe-Texte, sei es Produktnamen, Produktbeschreibungen oder Suchanfragen, werden zunächst tokenisiert und anschließend per Transformer in hochdimensionale Vektoren umgewandelt. Die Tokenisierung wandelt dabei die Rohtexte in eine für das Modell verständliche Form um, wobei spezielle Tokens und Masken verwendet werden, um die Struktur des Textes beizubehalten und Kontext sinnvoll zu erfassen. Im Modell werden die Embeddings für unterschiedliche Dokumentmerkmale, beispielsweise Produktnamen und Produktbeschreibungen, separat verarbeitet und durch trainierbare lineare Projektionen transformiert, die es erlauben, die Wichtigkeit einzelner Merkmale zu gewichten und kombiniert in eine Gesamtrepräsentation einzubetten.
Diese feinkörnige Verarbeitung erlaubt es, den Einfluss verschiedener Textquellen kontrolliert und gezielt an die Anforderungen der Suche anzupassen. Die gegenüber traditionelle Hybrid-Methoden entscheidenden Vorteile von Two-Tower-Architekturen liegen dabei nicht nur in einer verbesserten semantischen Darstellung, sondern auch in der erheblich reduzierten Komplexität der Suchpipeline. Statt einer großen Anzahl an lexikalischen Filtern wird die semantische Relevanz bereits im Embedding berücksichtigt, sodass weniger frühzeitige, harte Filter notwendig sind. Dies führt zu einer deutlichen Beschleunigung der vektorbasierenden Suchprozesse, da der Suchraum für Ähnlichkeitsvergleiche kleiner und besser fokussiert wird. Zudem ermöglicht die adaptive Gewichtung der verschiedenen Dokumentfeature im Embedding eine viel flexiblere und genauere Steuerung der Suchkriterien.
Dieser Paradigmenwechsel ist vor allem auch deshalb relevant, weil Unternehmen ihre Suchmaschinen nicht als reine Blackbox betrachten wollen, sondern die Möglichkeit schätzen, die Suchergebnisse auf ihre individuellen Anforderungen auszurichten. Two-Tower-Modelle lassen sich auf firmeneigene Trainingsdaten anpassen, und die kontrastive Trainingsmethode profitiert von speziell ausgewählten positiven und negativen Beispielen. Dadurch entstehen embeddingspezifische Suchräume, die auf die tatsächlichen Nutzerintentionen und die Produktvielfalt exakt zugeschnitten sind. Eine konkrete Umsetzung zeigt sich etwa in E-Commerce-Plattformen wie Wayfair, wo das WANDS-Datenset zur Optimierung von Produktsuchen verwendet wird. Hier werden Produktnamen und -beschreibungen parallel zu Suchanfragen mittels DistilBERT encodiert, anschließend durch lineare Layer transformiert und letztlich durch ein kontrastives Modell trainiert, um die Relevanz der Suchergebnisse zu maximieren.
Durch die geringere Anzahl notwendiger Filter und die bessere semantische Trennung können die Suchzeiten erheblich reduziert und gleichzeitig die Ergebnisqualität gesteigert werden. Darüber hinaus verbessert die Two-Tower-Architektur auch die Wartbarkeit und Skalierbarkeit der Suchengine. Da Dokumenteembeddings vorab berechnet und gespeichert werden können, müssen sie bei späteren Suchanfragen nicht erneut generiert werden. Nur die Query-Embeddings werden im laufenden Betrieb erzeugt und mit dem Dokumentpool verglichen. Diese Trennung vereinfacht nicht nur die Infrastruktur, sondern erlaubt auch den einfachen Austausch oder die Aktualisierung einzelner Komponenten, beispielsweise wenn neue Produktattribute oder Suchabsichten berücksichtigt werden sollen.
Zudem sind Two-Tower-Modelle prädestiniert für moderne Hardware-Beschleuniger und parallele Berechnungen. Die unabhängige Verarbeitung von Dokumenten- und Query-Embeddings lässt sich leicht parallelisieren, was die Leistungsfähigkeit der gesamten Sucharchitektur weiter steigert. In Kombination mit schnellen Vektor-Indexstrukturen wie Faiss oder Annoy können Unternehmen dadurch auch bei riesigen Katalogen von Millionen von Einträgen schnelle und präzise Suchergebnisse liefern. Natürlich ist die Einführung von Two-Tower-Architekturen nicht ohne Herausforderungen. Das Training solcher Modelle erfordert ausreichend hochwertige Trainingsdaten mit klar definierten relevanten und irrelevanten Paaren, um den kontrastiven Lernprozess effektiv zu gestalten.
Außerdem müssen Unternehmen Expertise im Bereich Deep Learning und Natural Language Processing mitbringen oder entsprechende Partner einbinden. Dennoch überwiegen die langfristigen Vorteile in Bezug auf Suchqualität, Performance und Flexibilität deutlich. Abschließend lässt sich sagen, dass Two-Tower-Modelle eine vielversprechende Weiterentwicklung der Suchtechnologie darstellen, die es ermöglicht, die klassischen Probleme der Hybrid-Suche zu überwinden und Suchprozesse intelligenter, schneller und anwenderspezifischer zu gestalten. Durch die enge Verzahnung von lexikalischen und semantischen Informationen in einem gemeinsamen Embedding-Raum entstehen bessere Grundlagen für eine nutzerzentrierte Informationsfindung. Unternehmen, die diese Technologie adaptieren, schaffen somit einen Wettbewerbsvorteil und heben die Nutzererfahrung der Suche deutlich auf ein neues Level.
Die Zukunft der Suche wird von solchen innovativen Modellen geprägt sein, die weit über einfache Schlagwortfilter hinausgehen und echte Bedeutung und Kontext erfassen können. Two-Tower-Modelle sind nicht nur ein technischer Fortschritt, sondern auch ein strategischer Schlüssel, um in einer Welt immer komplexerer Datenmengen relevant, schnell und effizient zu bleiben.