Die stetig wachsenden Anforderungen an moderne Softwarelösungen verlangen nach Systemen, die nicht nur funktional robust, sondern auch hoch performant sind. Valkey, ein vielseitiger Echtzeit-Datenbank-Service, steht exemplarisch für diese Herausforderung. Besonders im Kontext von Hochleistungsanwendungen wird die effiziente Nutzung der verfügbaren Hardware-Ressourcen zum entscheidenden Erfolgsfaktor. Die Performance-Optimierung von Valkey am CPU-Level zeigt beispielhaft, wie gezielte Strategien und technische Innovationen dabei helfen können, erhebliche Geschwindigkeitssteigerungen zu erzielen und die Ressourcenoptimalität nachhaltig zu sichern. Grundlegend lassen sich zwei primäre Ansätze bei der Optimierung der CPU-Performance unterscheiden: Zum einen das Maximieren der Parallelität und zum anderen das Steigern der Effizienz einzelner CPU-Kerne.
Während die erste Strategie die Architektur darauf ausrichtet, möglichst viele CPU-Kerne gleichzeitig zu nutzen, zielt die zweite darauf ab, innerhalb begrenzter CPU-Ressourcen die Ausführung so effizient wie möglich zu gestalten. Valkey nutzt ein innovatives I/O-Threading-Modell, das dabei hilft, den ersten Ansatz zu realisieren. Dieses Modell entlastet den Hauptprozess, indem es Aufgaben an dedizierte Threads delegiert. So wird eine nahezu lineare Skalierung mit zunehmender Kernanzahl möglich, was sich gerade bei hoher Zugriffszahl als großer Vorteil erweist. Die Verteilung der Last auf verschiedene Kerne vermeidet Flaschenhälse und ermöglicht eine signifikante Erhöhung der Durchsatzrate.
Doch reines Parallelisieren reicht nicht aus. Die zweite Strategie, nämlich die Verbesserung der Effizienz der einzelnen CPU-Kerne, ist für eine nachhaltige Performance-Optimierung mindestens ebenso wichtig. Hierzu gehört das Reduzieren von unnötigen Anweisungen und das Optimieren der Instruction-Per-Cycle (IPC)-Leistung. Letzteres bedeutet, dass der Prozessor so viele Befehle wie möglich pro Taktzyklus ausführt, was durch die Minimierung von Cache-Fehlzugriffen, branch mispredictions und ineffizienten Speicherzugriffsmustern unterstützt wird. Eine der zentralen Maßnahmen von Valkey bestand darin, redundanten Code zu eliminieren.
Besonders in Hotpaths, also Codeabschnitten, die besonders häufig und intensiv genutzt werden, führt jedes unnötige Berechnungselement zu spürbaren Leistungsverlusten. Indem mehrfach ausgeführte Funktionaufrufe, die keinen zusätzlichen Nutzen bringen, entfernt oder außerhalb von Schleifen verlegt wurden, konnte Valkey eine spürbare Verminderung des CPU-Bedarfs erreichen. Dies zeigt exemplarisch, dass schon geringe Änderungen in kritischen Pfaden die Performance erheblich verbessern können. Ein weiterer wichtiger Punkt war die Minimierung von Lock-Contention. Locks schützen gemeinsam genutzte Daten vor gleichzeitigen Zugriffen, können aber den Durchsatz beeinträchtigen, sobald viele Threads aufeinander warten müssen.
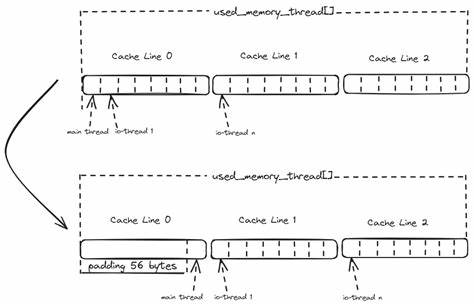
Valkey setzt dabei bevorzugt auf atomare Operationen, die zwar schneller als klassische Mutex-Locks sind, aber dennoch Overhead verursachen können. Ein cleverer Ansatz war hier die Nutzung von Thread-Local Storage. Indem Speichermetriken nicht zentral, sondern threadweise lokal erfasst und nur bei Bedarf aggregiert werden, konnte unnötiger Synchronisationsaufwand vor allem bei häufigen Schreiboperationen vermieden werden. Eine oft unterschätzte Ursache für Performanceverluste ist das sogenannte "False Sharing". Dabei greifen unterschiedliche Threads auf Variablen zu, die zwar logisch getrennt sind, aber physisch in derselben CPU-Cacheline liegen.
Aufgrund der Cache-Kohärenzmechanismen führt dies zu häufigem Cache-Invalidierungen und somit zu Verzögerungen. Valkey hat mit gezieltem Data-Padding und einer bewussten Neustrukturierung der Speicherbereiche das False Sharing zwischen Hauptthread und I/O-Threads adressiert. Dabei wurde ein intelligenter Kompromiss gewählt, um die Performance nicht durch zu viel Overhead bei der Speicherverteilung zu verschlechtern. Dies zeigt exemplarisch, dass nicht jede theoretisch perfekte Lösung in der Praxis gleich effizient ist, sondern immer eine pragmatische Abwägung erforderlich ist. Die Grundlage jeder erfolgreichen Optimierung ist ein aussagekräftiges Benchmarking.
Nur mit reproduzierbaren und präzisen Messungen lässt sich einschätzen, ob eine Veränderung im Code tatsächlich zu besseren Ergebnissen führt oder möglicherweise negative Nebeneffekte auslöst. Valkey setzt hier auf eine sorgfältig kontrollierte Testumgebung mit Bare-Metal-Servern, Core-Affinitäten über process pinning und lokalen Netzwerkverbindungen, um externe Einflüsse auf die Messergebnisse zu minimieren. Dies erlaubt eine eindeutige Zuordnung von Performance-Verbesserungen direkt zu den vorgenommenen Code-Optimierungen. Zusätzlich zur eigentlichen Optimierung sind fundierte Analysen mit Profiling-Tools wie perf und Intel® VTune™ genauso unverzichtbar. Diese Werkzeuge geben detaillierte Einblicke in Hotspots, Instruktionsmuster, Cache-Verhalten und Synchronisationsprobleme.
Basierend darauf wurden bei Valkey systematisch Engpässe identifiziert und angegangen. Das Zusammenspiel von Parallelität und Effizienz macht die Stärke von Valkey aus. Während die Skalierung der Threads ermöglicht, mit mehr Hardware-Ressourcen eine höhere Last zu bewältigen, sorgen die Effizienzmaßnahmen dafür, dass die CPU-Kerne ihre Aufgaben so schnell und ressourcenschonend wie möglich erledigen. Letztlich bedeutet dies eine bessere Ausnutzung der vorhandenen Infrastruktur bei gleichzeitig niedrigerer Latenz und höherem Datendurchsatz. Valkey zeigt damit auf eindrucksvolle Weise, dass Performance-Optimierung ein vielschichtiger Prozess ist, der neben der reinen Softwareentwicklung auch ein tiefes Verständnis der Hardwarearchitektur und systemnaher Abläufe erfordert.
Kleine Verbesserungen an kritischen Stellen können in Kombination mit intelligentem Systemdesign und präzisem Benchmarking zu signifikanten Leistungsgewinnen führen. Die Arbeit an Valkey ist ein lebendiges Beispiel dafür, wie Entwickler durch innovative und durchdachte Optimierungsstrategien selbst bei bereits ausgereiften Systemen noch ungenutztes Potenzial erschließen können. Die bewusst gewählten Kompromisse und Priorisierungen zeigen, dass Performance nicht nur durch technische Finessen, sondern auch durch strategisches Denken erreicht wird. Abschließend lässt sich sagen, dass die Performance-Optimierung bei Valkey weit über einfache Codeverbesserungen hinausgeht und ein systematisches Vorgehen mit tiefgreifenden Kenntnissen von Hardware und Software erfordert. Sowohl maximale Parallelität als auch CPU-Effizienz müssen im Einklang weiterentwickelt werden, um zukunftssichere, schnelle und stabile Systeme zu schaffen.
Die gewonnenen Erkenntnisse bieten wertvolle Impulse für Entwickler und Unternehmen, die ihre Anwendungen auf ein neues Leistungsniveau heben möchten.