Im Bereich der Künstlichen Intelligenz und des maschinellen Lernens gewinnt das Verständnis der zugrundeliegenden Daten- und Modellverarbeitungsprozesse zunehmend an Bedeutung. Insbesondere die Unterscheidung zwischen Offline- und Online-Machine-Learning-Pipelines stellt einen entscheidenden Faktor für den Erfolg von skalierbaren und robusten KI-Systemen dar. Paul Iusztin, ein erfahrener Experte im Bereich der KI-Architektur und MLOps, hebt in seinen Publikationen hervor, warum diese Trennung nicht nur theoretisch sinnvoll, sondern praktisch unverzichtbar ist. Viele Lernressourcen und Tutorials vermischen häufig die Konzepte von Offline- und Online-Pipelines, was bei Einsteigern ein verzerrtes Verständnis der tatsächlichen Abläufe in produktiven Umgebungen fördert. Während es aus didaktischen Gründen hilfreich sein kann, beide Prozesse gemeinsam in einer Notebook-Umgebung zu demonstrieren, spricht die Praxis eine völlig andere Sprache.
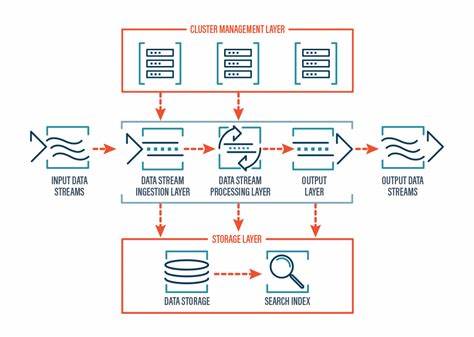
Wenn man KI-Systeme im produktiven Maßstab implementiert und betreibt, zeigt sich rasch, dass Offline- und Online-Pipelines zwei völlig unterschiedliche Anforderungen erfüllen und unterschiedlichen technischen Herausforderungen gegenüberstehen. Offline-Machine-Learning-Pipelines sind durch Batch-Verarbeitung gekennzeichnet. Sie laufen in der Regel zeitgesteuert oder werden durch spezifische Events initiiert und übernehmen hinter den Kulissen komplexe Prozesse wie die Sammlung, Bereinigung und Transformation von Daten (ETL), die Feature-Generierung sowie das Training von Modellen. Die Nutzung von MLOps-Frameworks wie ZenML unterstützt dabei die Orchestrierung und das Management dieser umfangreichen Hintergrundprozesse, die meist unabhängig vom Echtzeitbetrieb ablaufen. Diese Entkopplung trägt grundlegend zur Skalierbarkeit bei, denn sie erlaubt es den Modellen und Datenpipelines, getrennt von der unmittelbaren Nachfrage im System weiterzuarbeiten, ohne die User Experience zu beeinträchtigen.
Demgegenüber stehen die Online-Pipelines, die vor allem durch ihre Echtzeit- oder Near-Echtzeitverarbeitung charakterisiert sind. Sie bieten die direkte Schnittstelle zum Endnutzer oder zu Echtzeitanwendungen, indem sie schnelle und zuverlässige Vorhersagen bereitstellen. In der Praxis spiegeln sich Online-Pipelines oft in Formen wie RESTful APIs oder speziellen Inferenzservices wider, die 24/7 verfügbar sein müssen und sofortige Reaktionen auf Anfragen liefern. Gerade im Kontext generativer KI-Anwendungen, wie z. B.
großen Sprachmodellen (Large Language Models, LLM) oder Agenten, sind diese Pipelines essenziell, um eine bedarfsgerechte Interaktion zu gewährleisten. Der entscheidende Punkt liegt darin, dass Offline- und Online-Pipelines häufig vollkommen unabhängig voneinander sind, aber über gemeinsame Speichermechanismen wie Vektordatenbanken oder Modell-Registries gekoppelt werden. Ein gutes Beispiel hierfür ist die Implementierung eines KI-Assistenten, bei dem die Offline-Pipeline die aufwendige Aufgabe übernimmt, umfangreiche Dokumente zu verarbeiten, diese in hochwertige Datensätze umzuwandeln und schließlich trainierte Modelle oder embedding-basierte Informationen in einer Datenbank vorzuhalten. Die Online-Pipeline nutzt dann diese vorverarbeiteten Daten, um bei Nutzeranfragen schnell und effizient Antworten zu generieren, ohne selbst aufwendige Datenverarbeitungsprozesse ausführen zu müssen. Die Relevanz dieser Trennung wird besonders deutlich, wenn Systeme skaliert werden sollen.
Das Mischen von Batch- und Echtzeitarbeiten in einer einzigen Pipeline führt schnell zu Engpässen, die Evaluierung und Wartung werden komplexer und die Systemstabilität leidet. Wer hingegen die Pipelines logisch trennt und entsprechend orchestriert, kann flexibel auf unterschiedliche Anforderungen reagieren, Updates isoliert ausrollen und die Wartbarkeit verbessern. Zudem ermöglicht die Nutzung von Tools wie ZenML die Versionierung und Rückverfolgbarkeit von Pipeline-Durchläufen und Datenversionen, was gerade bei der Weiterentwicklung und dem Monitoring von Produktionssystemen unverzichtbar ist. Ein weiterer thematischer Schwerpunkt von Paul Iusztin ist das Design von Feature-Pipelines zur Dataset-Generierung für das Fine-Tuning spezialiserter Sprachmodelle. Das Erzeugen qualitativ hochwertiger Datensätze aus Rohdaten ist eine fundamentale Voraussetzung, um maßgeschneiderte Modelle mit optimierten Kosten, geringerer Latenz und besserer Domänenanpassung zu realisieren.
Seine Erfahrungen zeigen, dass ein strukturierter Ablauf von der Extraktion über Qualitätsanalyse und -filterung bis hin zur Datenaufteilung und Veröffentlichung in Beispielregistern wie Hugging Face essenziell ist. In diesem Kontext spielen Offline-Pipelines die zentrale Rolle, da sie sowohl die Datenaufbereitung als auch die eigentliche Dataset-Produktion verantworten. Die einzelnen Schritte innerhalb solcher Pipelines umfassen das Sammeln und Normalisieren von Dokumenten, statistische Analysen zur Bewertung der Datenqualität, das Entfernen minderwertiger Inhalte, sowie – besonders im Bereich der Generativen KI – das Erzeugen vielfältiger Zusammenfassungen durch Variation von Parametern wie Temperatur und Sampling. Anschließend folgen eine rigorose Qualitätskontrolle, die Aufteilung der Daten in Trainings-, Validierungs- und Testsets sowie die abschließende Versionierung und Veröffentlichung des Datensatzes. Dank Frameworks wie ZenML können diese Prozesse reproduzierbar, konfigurierbar und transparent gestaltet werden.
Die Kombination aus differenzierten Offline- und Online-Pipelines trägt somit maßgeblich dazu bei, produktionsreife KI-Anwendungen zu schaffen. Durch die saubere Trennung und die Nutzung spezialisierter Tools lassen sich sowohl Leistung als auch Wartbarkeit optimieren und werden Skalierbarkeitsprobleme elegant umgangen. Für Praxisentwickler von KI-Systemen ist es deshalb essenziell, diese Paradigmen frühzeitig zu verstehen und umzusetzen. Zusammenfassend lässt sich festhalten, dass die Abgrenzung zwischen Offline- und Online-ML-Pipelines nicht nur organisatorisch, sondern auch technisch von hoher Bedeutung ist. Sie ermöglicht professionelles MLOps-Management, sorgt für stabile und schnelle Inferenzsysteme und sichert die Qualität der Datengrundlage für Modelltrainings.
Inspiration für konkrete Implementierungen und tiefere Einblicke bietet Paul Iusztins Arbeit sowie seine praxisnahen Kurse, die explizit auf die Herausforderungen moderner KI-Infrastrukturen eingehen. Wer sich also in Richtung production-grade KI-Anwendungen bewegt, sollte bewusst auf die Trennung und effektive Gestaltung beider Pipelines achten. Nur so lassen sich die vielfältigen Anforderungen an moderne AI-Systeme erfüllen und nachhaltige Lösungen entwickeln, die allen Beteiligten echten Mehrwert bieten.