Die rasante Entwicklung im Bereich der Künstlichen Intelligenz (KI) und insbesondere der großen Sprachmodelle (Large Language Models, LLMs) stellt neue Herausforderungen an Ressourcen und Hardware. Traditionell war das Training solcher Modelle auf professionellen Hochleistungssystemen mit teuren GPUs und umfangreichem Rechencluster angewiesen. TScale präsentiert sich als wegweisende Lösung, die diese Hürde auf innovative Weise adressiert und verteiltes Training auf gängigen Consumer-GPUs ermöglicht. Dadurch eröffnet sich ein völlig neuer Zugang zu großen Sprachmodellen für Entwickler, Forschende und Enthusiasten mit begrenztem Budget. TScale stellt eine opensource-basierte Plattform dar, die speziell darauf ausgerichtet ist, große Transformer-Modelle effizient auf preiswerten NVIDIA-Grafikkarten zu trainieren.
Die Software ist in C++ und CUDA entwickelt und fokussiert sich auf verschiedenste Optimierungen, insbesondere bei der Speicherverwaltung, der Präzisionsreduktion und der Verteilung der Trainingslast über mehrere Hosts. Ein entscheidendes Merkmal von TScale ist die verschlankte und angepasste Architektur des Transformers. Deren Design bietet eine schnellere Konvergenz, während die Kosten für die Aufmerksamkeitsmechanismen (Attention) halbiert werden. Dies minimiert den Rechenaufwand und den Speicherverbrauch und bringt das Training großer Modelle auch auf Consumer-Hardware in greifbare Nähe. Zusätzlich unterstützt TScale reduzierte Genauigkeiten wie fp8 (floating point 8-bit) und int8, sowohl für Modellgewichte als auch für Aktivierungen.
Solche niedrigpräzisen Darstellungen sparen massiv Speicher und Rechenzeit ein, ohne die Modellqualität nennenswert zu beeinträchtigen. Für nVidia-GPUs der Consumerklasse, wie z. B. der RTX-4000-Serie, optimiert TScale den Trainingseinfluss nochmals durch eine schnelle und reduzierte Präzisionsausführung, wodurch ein hervorragendes Verhältnis von Kosten und Leistung entsteht. Ein weiteres zentrales Feature von TScale ist das CPU-Offloading.
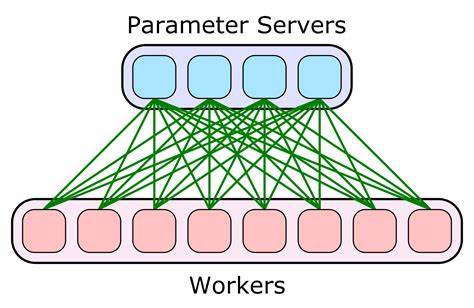
Dieses Verfahren verlagert Teile der Speicherlast vom GPU-Speicher auf die CPU, um die begrenzte GPU-Memory besser ausnutzen zu können. Da viele Consumer-GPUs „nur“ 12 bis 24 GB Speicher bieten, ist dies essentiell, um größere Modelle überhaupt handhabbar zu machen. Durch das Offloading steigt die Trainingskapazität deutlich. Darüber hinaus unterstützt TScale sowohl synchrones als auch asynchrones verteiltes Training auf mehreren Hosts – vorausgesetzt, sie besitzen identische Hardwarekonfigurationen. Synchrones Training verteilt die Arbeit auf eine potenzierte Zahl von Hosts (Pow2) und ermöglicht dadurch eine effiziente und koordinierte Skalierung.
Die besonders innovative asynchrone Variante erlaubt Trainingsläufe über geografisch weit auseinanderliegende Maschinen, wobei die Netzwerkbelastung minimal bleibt. Dies reduziert Kosten und Infrastrukturbedarf erheblich und ermöglicht etwa das Zusammenschalten von einzelnen heimischen Rechnern inklusive Verwendung einfacher Ethernet-Verbindungen dank 1-Bit Gradient Compression. Die Verwendung solcher Kompressionsmethoden reduziert den erforderlichen Durchsatz für die Netzwerkanbindung drastisch. Dabei werden die Gradienten während des Backpropagationsschrittes stark komprimiert, ohne signifikante Einbußen bei der Gradientenqualität hinzunehmen. Das Resultat sind stabile Trainings mit signifikant verminderten Kommunikationskosten.
Die Fähigkeit, selbst Modelle der Größenordnung 1,5 Milliarden Parametern auf normalen Consumer-GPUs zu trainieren, belegt die Leistungsfähigkeit der Plattform eindrucksvoll. TScale ermöglicht sogar die Verwaltung eines Modells mit einem Index von etwa einer Terabyte Größe, der zur Vorhersage genutzt wird. Durch diese Kombination aus kleinem eigentlichen Modell und großem Index lässt sich eine herausragende Performance hinsichtlich Log-Loss und Perplexity erzielen, die für viele praktische Anwendungsfälle exzellent geeignet ist. Das Training von Modellen mit über einer Million Millionen (1 Billion) Parametern in einer Heimumgebung klingt zunächst wie Science-Fiction. TScale setzt genau hier neue Maßstäbe und zeigt, wie eine clevere Aufteilung der Modellkomponenten und Indexierungsstrategien eine solch enorme Modellgröße praktisch nutzbar machen.
Das Modell nutzt den riesigen Index als Lookup-Tabelle während der Vorhersage und arbeitet mit einem wesentlich kleineren eigentlichen neuronalen Netz. Anhand praxisnaher Beispiele wie dem „fineweb-edu“ Datensatz wird das enorme Potenzial dieser Technik demonstriert: Die Perplexity sinkt um ein Vielfaches gegenüber dem Basismodell, was sich in deutlich verbesserten Vorhersagefähigkeiten zeigt. Die Software selbst ist auf hohe Portabilität ausgelegt und unterstützt sowohl Windows- als auch Linux-Plattformen. Die nötigen Entwicklungswerkzeuge sind CUDA v12.3 und wahlweise MSVC für Windows oder CMake mit Clang unter Linux.
Ein besonderes Highlight ist die Verwendung von „fo“, einem minimalistischen Tool zur Build-Dateigenerierung, das plattformübergreifend funktioniert. Für die Benutzer ist somit ein einfacher Einstieg gewährleistet, um ihr eigenes Training aufzubauen und auszuführen. Die Trainingsbeispiele umfassen bekannte Datensätze wie enwik9, enwik8 oder Webtext-Varianten von Hugging Face. Diese Auswahl ermöglicht Forschern, bereits bewährte Daten für erste Experimente in TScale zu verwenden. Die ausführbaren Programme „gpt_train“ und „gpt_infer“ dienen dabei zum Training des Modells und zur Demonstration der Inferenz in einem einfachen HTTP-Server.
Die Zukunft des dezentralisierten Trainings großer KI-Modelle erhält durch Projekte wie TScale einen enormen Schub. Die Kombination aus kostengünstigem Equipment, effektiver Optimierung der Netzarchitektur, reduzierter numerischer Präzision und innovativem verteiltem Training öffnet die Türen für eine Demokratisierung des Modelltrainings. Dies bedeutet, dass nicht mehr nur Großunternehmen mit teuren Rechenzentren in der Lage sind, große LLMs zu erstellen und zu verbessern. Stattdessen kann eine breite Community von Entwicklern und Forschenden mit Consumer-GPUs noch effizienter und bezahlbarer an der KI-Entwicklung mitwirken. Zudem setzt TScale wichtige Impulse für Nachhaltigkeit und Ressourceneffizienz.
Reduzierter Stromverbrauch durch minimalen Hardwarebedarf, geringere Kühlkosten und eine bessere Ausnutzung vorhandener Hardwarekapazitäten leisten einen Beitrag zum umweltfreundlicheren KI-Training. Auch die Möglichkeit, Trainingsaufgaben über weite geografische Distanzen ohne enorme Netzwerkressourcen zu verteilen, unterstützt diese Entwicklung in Richtung eines nachhaltigen Einsatzes von KI-Technologien. Nicht zuletzt zeigt TScale, dass technische Innovationen in der Softwarearchitektur essenziell sind, um Hardwareeinschränkungen zu umgehen. Das zeigt einmal mehr, wie wichtig optimierte Algorithmen, intelligente Speicherverwaltung und effiziente Netzwerkprotokolle für zukunftsfähiges Machine Learning sind. Die Open-Source-Basis lädt die Community ein, sich aktiv an der Weiterentwicklung zu beteiligen und das Potenzial der Plattform stetig auszubauen.
Für Interessierte, die sich auf das Abenteuer einlassen möchten, eigene große Sprachmodelle zu trainieren, stellt TScale eine attraktive und effektive Option dar. Der Aufbau erfordert zwar ein gewisses Maß an technischem Verständnis, wird jedoch durch die detaillierte Dokumentation und die Beispiele im Repository stark erleichtert. Insbesondere im Vergleich zu proprietären, Cloud-basierten Lösungen können die Kosten drastisch reduziert werden – ein entscheidender Vorteil für experimentelle Forschung und Lernen. Zusammenfassend bringt TScale eine innovative Verteilung und Trainingstechnologie für Transformer-Modelle auf den Markt, die speziell auf Consumer-Hardware zugeschnitten ist. Die Plattform überzeugt durch technische Raffinesse, praktische Einsatzmöglichkeiten und ein zukunftsweisendes Konzept, das die Kluft zwischen Großrechnern und Heimcomputern im Bereich der KI schrittweise überbrückt.
In einer Welt, in der KI zunehmend unser Leben beeinflusst, kann solch ein Fortschritt einen wichtigen Beitrag zur breiten, demokratisierten Nutzung von Intelligenzwerkzeugen leisten.