Die Fortschritte im Bereich der künstlichen Intelligenz haben die digitale Welt nachhaltig verändert, insbesondere im Kontext der Webautomation und der Nutzung von KI-Browseragenten. Diese Technologien ermöglichen es, komplexe Aufgaben im Internet zu automatisieren, die bisher menschliches Eingreifen erforderten. Doch wie lässt sich die Leistungsfähigkeit dieser Agenten objektiv und vergleichbar bewerten? Hier setzt Web Bench als neue Benchmark an, die eine revolutionäre Methode zum Vergleich von KI-Browseragenten vorstellt und dabei neue Maßstäbe für Genauigkeit, Vielfalt und Realitätsnähe setzt. Web Browsing Agenten haben in den letzten Jahren stark an Bedeutung gewonnen. Programme wie Skyvern, Browser-use oder OpenAI’s Operator (CUA) weisen eine bemerkenswerte Bandbreite an Anwendungsmöglichkeiten auf.
Von der Jobsuche über das Herunterladen von Rechnungen bis hin zu komplexen Steueraufgaben sind diese Agenten aktiv im Einsatz. Trotz der versprochenen Leistungsfähigkeit stehen sie vor erheblichen Herausforderungen. Besonders Aufgaben, die eine Interaktion mit geschützten Bereichen von Webseiten erfordern, wie etwa Authentifizierung, Formularausfüllung oder das Lösen von Captchas, stellen noch immer große Hürden dar. Bisher gängige Benchmarks, beispielsweise das WebVoyager-Dataset, bieten nur eine begrenzte Vergleichsbasis. Sie konzentrieren sich überwiegend auf lesebasierte Aufgaben und berücksichtigen lediglich etwas mehr als 600 Aufgaben auf 15 Websites.
Im Vergleich zur riesigen Vielfalt und Komplexität des Internets ist dies nur ein kleiner Ausschnitt. Zudem fokussieren sich viele dieser Tests auf statische Informationsabfrage statt auf dynamische Interaktionen, was die tatsächlichen Herausforderungen im Alltag unterschätzt. Web Bench geht mit einem deutlich erweiterten Ansatz an diese Problematik heran. Es wurde in Kooperation mit dem Team von Halluminate entwickelt und zeichnet sich durch den Einsatz von 5.750 Tests auf 452 verschiedenen Webseiten aus.
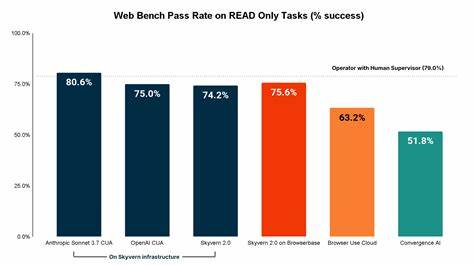
Ein erheblich größerer Datensatz, der unterschiedliche Inhaltstypen, Kategorien und Nutzungsszenarien abdeckt. Das Dataset unterscheidet dabei explizit zwischen sogenannten READ- und WRITE-Aufgaben. Während READ-Aufgaben die reine Navigation auf der Seite und das Extrahieren von Informationen umfassen, beziehen sich WRITE-Aufgaben auf das Eingeben von Daten, das Herunterladen von Dateien oder das Bewältigen von Sicherheitsbarrieren wie 2-Faktor-Authentifizierungen. Diese klare Trennung erlaubt ein differenziertes Verständnis der Stärken und Schwächen der einzelnen KI-Agenten. Die Analyse zeigt deutlich: Die meisten Browseragenten erreichen solide Ergebnisse bei der Informationsbeschaffung, während komplexere Aufgaben mit aktiver Interaktion erheblich schlechter gelingen.
Dies gilt insbesondere für kritische Anwendungen, bei denen der Agent sicherstellen muss, dass ein Formular korrekt ausgefüllt, eine Datei ordnungsgemäß heruntergeladen oder eine Login-Prozedur erfolgreich abgeschlossen wird. Zu den beliebtesten KI-Agenten im Benchmark gehören Skyvern 2.0 sowie Anthropic’s Sonnet 3.7 CUA, letzterer derzeit der Spitzenreiter bei der Gesamtleistung. Die Erkenntnisse verdeutlichen, dass insbesondere Skyvern bei write-lastigen Aufgaben die besten Ergebnisse erzielt, was auf eine robuste Architektur und ein effizientes Browser-Backend hindeutet.
Gleichzeitig offenbaren die Daten jedoch auch, wie sehr die zugrundeliegende Infrastruktur den Erfolg beeinflusst. Probleme bei der Zugänglichkeit von Webseiten, Captcha-Lösungen oder Einschränkungen durch Proxys sind häufige Ursachen für Misserfolge, die unabhängig von der KI-Intelligenz bestehen bleiben. Die Entwicklung von Web Bench beinhaltet darüber hinaus die umfassende Auswahl von Webseiten, die mindestens in englischer Sprache verfügbar sind und keine Zugangsbarrieren wie Paywalls besitzen. Die dadurch entstandene Auswahl der Websites orientiert sich an weltweit reichweitenstarken Domains, was eine realistische Abbildung alltäglicher Web-Nutzung gewährleistet. Die Besonderheit liegt darin, dass diese Vielzahl an Webseiten ein breites Spektrum von Branchen und Funktionalitäten umfasst – von Online-Shops über Nachrichtenseiten bis hin zu Regierungsportalen.
Ein weiterer wichtiger Aspekt von Web Bench ist die menschliche Überprüfung der Resultate. Trotz des hohen Automatisierungsgrades bleibt die Qualitätssicherung durch menschliche Evaluatoren ein bedeutender Faktor, der sicherstellt, dass die Ergebnisse valide und aussagekräftig sind. Dies erhöht die Verlässlichkeit der Daten und macht den Benchmark zu einer aussagekräftigen Referenzquelle. Die Veröffentlichung des Benchmarks als Open-Source-Projekt ist zudem ein wichtiger Schritt in Richtung Transparenz und Kollaboration. Entwickler und Forscher sind dazu eingeladen, ihre eigenen KI-Browseragenten über Web Bench testen zu lassen und so ihre Systeme an einem breit gefächerten und anspruchsvollen Datensatz zu messen.
Diese Offenheit schafft eine Community rund um die Weiterentwicklung der Webautomation und fördert den Innovationsdruck. Die Erkenntnisse aus Web Bench haben weitreichende Implikationen. Zum einen zeigen sie das enorme Potenzial zur Verbesserung der KI-Webagenten bei der Bewältigung interaktiver Aufgaben. Während reine Informationsbeschaffung bereits gut funktioniert, ist das Handling von Formularen, Logins und Downloads ein Bereich mit beträchtlichem Wachstumspotenzial. Die Forschung kann sich dadurch gezielter auf die Entwicklung verbesserter Algorithmen und stabilerer Browser-Infrastrukturen konzentrieren.
Zum anderen wirft Web Bench ein Licht auf die Herausforderungen, die durch die Architektur moderner Webseiten entstehen. Dynamische Inhalte, Popups, Captchas und Anti-Bot-Mechanismen erschweren die Automatisierung erheblich. Die KI-Agenten müssen sich nicht nur inhaltlich präzise verhalten, sondern auch auf komplexe Nutzerschnittstellen flexibel reagieren können. Dieses Zusammenspiel zwischen intelligentem Agenten und stabiler technischer Grundlage ist entscheidend für den künftigen Erfolg. Ein zusätzlicher Fokus liegt auf Effizienz und Kostenaspekten.
Die Bewertung der Laufzeit und der Anzahl der notwendigen Schritte eröffnet Einblicke in die praktische Umsetzbarkeit der Agenten. Gerade für Anwendungen, die auf geringe Latenz angewiesen sind, etwa interaktive Assistenten oder Echtzeit-Informationsdienste, sind Geschwindigkeit und Ressourcenschonung fundamentale Kriterien. Web Bench liefert hier wichtige Kennzahlen, die in Folgeentwicklungen einfließen können. Die Zukunft von Web Bench sieht eine kontinuierliche Erweiterung vor. Geplant sind unter anderem weitere Sprachvarianten, um die Mehrsprachigkeit des Webs besser abzubilden.
Auch die Integration zusätzlicher Kategorien und eine Ausweitung auf weniger populäre, aber dennoch relevante Webseiten stehen auf der Agenda. Ebenso ist die Einbindung neuer Agenten und das Benchmarking weiterer moderner Modelle vorgesehen, etwa Claude 4 oder Mariner API. Web Bench markiert einen bedeutenden Schritt in der professionellen Evaluation von KI-Webagenten. Es schafft erstmals eine belastbare Vergleichsbasis, die sowohl die Breite des modernen Webs als auch die Komplexität interaktiver Aufgaben berücksichtigt. Für Entwickler, Anwender und Forscher bietet dieses Instrument wertvolle Einblicke und Orientierung.
Die Herausforderungen sind groß, doch auch der Innovationsgeist und die technologischen Ressourcen. In einer Welt, in der die Automatisierung immer zentraler wird, hilft Web Bench dabei, Chancen und Schwächen objektiv zu erfassen und gezielt Fortschritt zu erzielen. Damit ebnet es den Weg zu intelligenteren, verlässlicheren und effizienteren KI-Browseragenten, die das Potential haben, zahlreiche Bereiche unseres digitalen Alltags zu transformieren.