NumPy gilt seit langem als das Herzstück von wissenschaftlichem Rechnen mit Python. Es bietet mächtige Werkzeuge für die Arbeit mit mehrdimensionalen Arrays und ist die Grundlage vieler machine-learning Bibliotheken wie PyTorch. Doch trotz seiner Popularität und seiner grundlegenden Rolle in der Datenwissenschaft und KI-Entwicklung gibt es immer wieder ernsthafte Kritik am Design und an der Benutzbarkeit von NumPy. Ein besonders pointierter Standpunkt dazu stammt von Dynomight, einem erfahrenen Entwickler, der öffentlich seine Frustration über die Komplexitäten und Unübersichtlichkeiten von NumPy teilt. NumPy macht einfache Dinge in der Tat einfach.
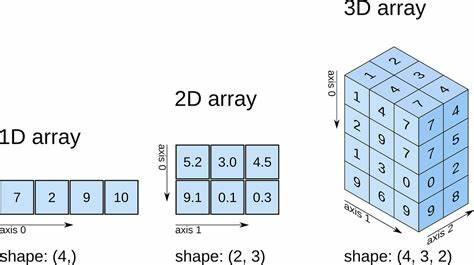
Ein typisches Beispiel ist das Lösen eines linearen Gleichungssystems Ay = x, wobei A eine quadratische Matrix und x ein Vektor ist. Mit nur einer einzigen Zeile Code löst NumPy dies elegant und effizient. Doch sobald man über einfache zwei- oder gar eindimensionale Arrays hinaus denkt und in die Welt höherdimensionaler Arrays eintaucht, entpuppt sich NumPy als ein dunkler Dschungel voller Fallstricke, die nicht nur Neulinge, sondern auch erfahrene Nutzer oft verwirren. Das Kernproblem liegt im Umgang mit Arrays mit drei oder mehr Dimensionen und der Anforderung, Operationen vektorisiert über diese Dimensionen auszuführen. Stellen Sie sich vor, man möchte 100 lineare Gleichungssysteme gleichzeitig lösen, bei denen jede Matrix A_i und jeder Vektor x_i unterschiedlich sind.
Ein naiver Weg mit einer Schleife ist in Python ineffizient und widerspricht der modernen Praxis, GPU-Beschleunigung und parallele Berechnung zu nutzen. Allerdings sind NumPys Definitionen und Dokumentationen dazu so verwirrend, dass auch Experten oft nicht wissen, wie dies korrekt umzusetzen ist. Es existiert keine einheitliche, verständliche Konvention zur Angabe von Achsen oder Dimensionen bei solchen Problemen, was zu einem trial-and-error-Verfahren führt. Diese Komplexität setzt sich auch beim Thema Broadcasting fort, einem Kernkonzept von NumPy, das kleine Arrays so erweitert, dass sie bei Operationen auf größere Dimensionen passen. Während in einfachen Beispielen dieser Mechanismus als clever und hilfreich empfunden wird, wird er bei komplexeren Manipulationen schnell undurchsichtig und zu einem der Hauptgründe für schwer lesbaren und fehleranfälligen Code.
Das Weglassen von expliziten Indizes zugunsten von implizitem Broadcasting führt oft zu tückischem Verhalten, bei dem jede Operation stark vom Kontext abhängt und ohne tiefgreifendes Verständnis nur schwer nachvollziehbar ist. Ein ähnliches Problem findet sich in der Indexierung. NumPys flexibles aber kompliziertes System, Indizes und Slices zu kombinieren, führt häufig zu unerwarteten Formen bei den Resultaten. Das Verstehen, wie sich dabei Dimensionen verschieben oder neue Dimensionen entstehen, wird zu einer Intelligenzprobe selbst für erfahrene Anwender. Beispiele wie die Kombination von vektorisierten Indizes mit Slices erzeugen Dimensionen und Formen, die nahezu unvorhersehbar sind.
Die hohe Lernkurve für diese Konzepte und die fehlende Transparenz schränken die Lesbarkeit und Wartbarkeit von Code stark ein. Ein leuchtendes Gegenbeispiel innerhalb von NumPy ist die Funktion np.einsum, die das Einstein’sche Summenkonzept verwendet, um Operationen über mehrere Dimensionen mit expliziten Indizes zu beschreiben. Zwar wirkt die entsprechende Notation am Anfang einschüchternd, aber sie bietet einen klaren, einheitlichen und mächtigen Weg, komplexe Operationen auszudrücken, ohne sich in Broadcasting-Fallen zu verlieren. Hier zeigt sich, dass eine auf Indizes basierende Syntax einer Broadcasting-basierten deutlich überlegen sein kann.
Doch das Problem bleibt: np.einsum ist sehr spezialisiert und unterstützt keine allgemeinere Funktionalität oder alle numpy-typischen Operationen. Eine weitere Schwäche von NumPy ist die Schwierigkeit, eigene Funktionen zu schreiben, die sich nahtlos auf beliebige Dimensionen höherdimensionaler Arrays anwenden lassen. Die Praxis zeigt, dass häufig bestehende Funktionen komplett neu geschrieben werden müssen, um sie für andere Dimensionen oder Formen anzupassen. Das widerspricht fundamentalen Prinzipien von Softwareentwicklung wie Abstraktion, Wiederverwendbarkeit und Modularität.
Viele Versuche, das zu umgehen, führen zu komplexen Konstruktionen, die den Code noch schwerer verständlich und wartbar machen. Ein gutes Beispiel für diese Problematik liefern Attention-Mechanismen, wie sie in modernen Sprachmodellen verwendet werden. Während ein einfacher Self-Attention-Mechanismus in NumPy mit wenigen Zeilen recht klar bleibt, gestaltet sich die Umsetzung von Multi-Head-Attention als schwer nachvollziehbares, undurchsichtiges Wirrwarr aus Transpositionen, Vektor-Operationen und verschachtelten np.einsum-Aufrufen. Ein simpler Ansatz mit Schleifen, der konzeptionell leicht verständlich wäre, ist in der NumPy-Welt ineffizient oder sogar unerwünscht.
Durch diese Komplexität leidet die Zugänglichkeit für Entwickler und das Risiko, Fehler einzubauen, steigt stark an. Die Fragen, die sich daraus ergeben, sind grundlegend: Liegt das Problem in Python und seiner Performance bei Schleifen? Oder ist NumPy konzeptionell unzureichend für die Herausforderungen moderner numerischer Berechnungen mit mehrdimensionalen Arrays? Offenbar ist Letzteres der Fall. Alternative Sprachen wie Julia bieten hier oft einen schonenderen Umgang mit Schleifen und erlauben Konzepte, die NumPy vor Schwierigkeiten stellen. Dynomight bringt es auf den Punkt, wenn er sagt, dass NumPy grundlegend einen konzeptionellen Fehler gemacht hat. Die Entscheidung, Indizes durch Broadcasting zu ersetzen, habe das Werkzeug in eine Ecke gedrängt, aus der es mit wachsender Komplexität und Anforderungen nicht mehr herausfindet.
Broadcasting funktioniert für einfache Anwendungen, doch sobald mehrere Dimensionen zu koordinieren sind, entsteht ein unüberschaubarer und fehlerträchtiger Zustand. Die Konsequenz dieser Schwächen ist, dass viele NumPy-Anwender gezwungen sind, unübersichtlichen, fehleranfälligen Code zu schreiben oder auf viele Workarounds und Drittbibliotheken zurückzugreifen. Die in Teilen überaus kraftvolle und elegante Logik von NumPy droht im Gebrauch durch unklare Dokumentationen, fehlende einheitliche Standards und die Komplexität der Verwendung von Indizes, Achsen und Dimensionen verloren zu gehen. Dennoch gibt es Hoffnung. Werkzeuge wie np.
einsum zeigen, wie man präzise und mit klaren Regeln über Dimensionen operieren kann. Außerdem gibt es Versuche und Prototypen, moderner und zugleich mächtiger zu sein, ohne die Nachteile von Broadcasting und komplexen Indexierungsregeln zu übernehmen. Die Zukunft liegt vermutlich in einer Ausweitung der Konzepte hinter np.einsum auf allgemeinere Operationen, kombiniert mit einer einfacheren, klareren Syntax und besseren Unterstützung für parallele und vektorielle Berechnungen. Es ist wichtig, den Wert von NumPy anzuerkennen.
Ohne es wären viele moderne Data-Science- und KI-Werkzeuge heute nicht vorstellbar. Doch genau wie bei jeder etablierten Technologie zeigen sich mit der Zeit Grenzen, die es zu überwinden gilt. Die kritische Auseinandersetzung mit NumPys Unzulänglichkeiten ist ein Weg, um Raum für Entwicklung und Innovation zu schaffen und dadurch Werkzeuge zu ermöglichen, die die Arbeit mit mehrdimensionalen Arrays wirklich intuitiv und effizient machen. Für Programmierer, Wissenschaftler und Entwickler bedeutet dies, auch jenseits von NumPy alternative Bibliotheken, Sprachen und Paradigmen zu prüfen. Julia etwa ermöglicht effiziente Schleifen und besitzt leistungsfähige Batterie-Management für lineare Algebra, welches den Anforderungen moderner numerischer Berechnungen besser gerecht wird.