Sprache als natürliche Kommunikationsform zunehmend mit künstlicher Intelligenz (KI) zu verbinden, gehört zu den spannendsten Herausforderungen der heutigen Technologieentwicklung. Große Sprachmodelle, auch als Large Language Models (LLMs) bekannt, spielen hierbei eine zentrale Rolle, vor allem bei Anwendungen, die lange und komplexe Interaktionen ermöglichen sollen. Ob in mehrstufigen Dialogen, beim Verfassen ausgedehnter Texte oder im Echtzeit-Streaming von Inhalten – die Anforderungen an diese Modelle wachsen stetig, damit sie auch mit sehr langen Textsequenzen effizient umgehen können. Der Einsatz klassischer Modelle stößt jedoch schnell an Grenzen, insbesondere was Speicherverbrauch und Leistungsfähigkeit bei wiederkehrender Verarbeitung betrifft. Eine innovative Lösung für diese Herausforderung liegt in der jüngsten Forschung rund um effiziente Streaming-Sprachmodelle mit sogenannten Attention Sinks.
Dieses Konzept stellt einen bedeutenden Fortschritt dar, um die gewaltigen Speicheranforderungen bei der Handhabung von langen Textsequenzen erheblich zu reduzieren, ohne dabei die Qualität oder Genauigkeit der Resultate zu beeinträchtigen. Dabei wird nicht mehr der gesamte Kontext erfasst oder gespeichert, sondern mittels intelligenter Mechanismen ein „Aufmerksamkeits-Senker“ – der Attention Sink – geschaffen, der wesentliche Teile des Kontextes dauerhaft referenziert, während weniger relevante Bereiche flexibel gehandhabt werden. Ein Kernproblem beim Streaming mit LLMs ist das Caching beziehungsweise Zwischenspeichern von Schlüssel- und Wert-Darstellungen (Keys und Values) für Tokens, die bereits verarbeitet wurden. Diese Daten sind essenziell, um bei jedem neuen Token die Aufmerksamkeit dynamisch anzupassen und somit Kontextinformationen fließend einzubeziehen. Das Caching der vollständigen Sequenz kann jedoch enormen Speicherbedarf erzeugen, insbesondere wenn sehr lange Texte verarbeitet werden.
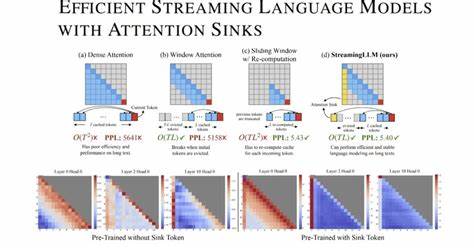
Abhilfe schafft die sogenannte Fensteraufmerksamkeit (Window Attention), die nur die letzten K-KV-Werte speichert. Hierbei wird allerdings schnell klar, dass diese Methode an ihre Grenzen stößt, sobald der Text die Größe dieses Fensters überschreitet und wichtige Informationen aus dem Anfang des Textes verloren gehen. Interessanterweise fand das Forschungsteam um Guangxuan Xiao und andere heraus, dass es gerade das Beibehalten der KV-Werte ganz am Anfang der Sequenz ist, das die Leistung stabilisiert – selbst dann, wenn diese Anfangstokens nicht semantisch besonders wichtig sind. Dieses Phänomen wurde als Attention Sink bezeichnet, weil die Aufmerksamkeit des Modells tendenziell stark auf diese frühen Positionen gelenkt wird, wodurch sie als eine Art „Aufmerksamkeits-Senker“ funktionieren. Dieses Verhalten war bis dahin nicht ausreichend untersucht oder genutzt worden.
Auf Basis dieser Erkenntnis wurde das Framework StreamingLLM entwickelt, das es ermöglicht, bereits trainierte LLMs mit begrenzter Kontextgröße effizient und stabil für unbegrenzt lange Eingabesequenzen einzusetzen. Ohne zusätzliches Fine-Tuning kann StreamingLLM Modelle wie Llama-2, MPT, Falcon und Pythia befähigen, stabile Ergebnisse bei der Bearbeitung von Millionen Texteinheiten zu liefern. Dies ist insbesondere für Anwendungen mit kontinuierlichem Dialog oder längeren Textanalysen revolutionär. Ein weiterer bemerkenswerter Aspekt von StreamingLLM besteht darin, dass während der Trainingsphase ein Platzhalter-Token als dedizierter Attention Sink eingebaut werden kann. Dieser spezielle Token wird metaaufmerksam für das Modell und fungiert als effektiver Fixpunkt, an dem ältere Kontexte und Informationen ankommen.
Dieses Vorgehen sorgt für noch stabilere und effizientere Streaming-Anwendungen, da die Modelle bereits bei der Entstehung auf dieses Attention Sink-Verhalten vorbereitet werden. Im Vergleich zu bisherigen Methoden wie der vollständigen Neu- oder Teilberechnung der Fensteraufnahme bietet StreamingLLM dramatische Performancevorteile. Anstatt mehrfach umfangreiche Berechnungen für sich überschneidende Textbereiche durchzuführen, nutzt das Framework das Konzept des Attention Sinks, um den Aufwand zu minimieren und dennoch hohe Genauigkeit und Kontextverständnis in der Verarbeitung zu gewährleisten. Die Geschwindigkeit kann hierbei um den Faktor 22,2 im Vergleich zu klassischen Rechenmethoden gesteigert werden. Die praktische Bedeutung dieser Forschung ist enorm.
Für den Einsatz in realen Systemen, etwa intelligenten Chatbots, automatisierten Übersetzern oder Sprachassistenten, bedeutet sie eine deutliche Verbesserung der Nutzererfahrung und der Systemressourcen. Auch bei der Verarbeitung von langen Dokumenten oder beim Umgang mit sehr umfangreichen Konversationen können diese Streaming-Sprachmodelle eine neue Ära einläuten, in der Echtzeitkommunikation und detaillierte Textanalyse ohne Leistungseinbußen möglich sind. Die Offenlegung des Codes und der Datensätze unterstreicht zudem die Bereitschaft der Forscher, diese Innovation breit zugänglich zu machen und die Community in der Weiterentwicklung zu fördern. Unternehmen und Entwickler haben somit die Chance, leistungsstarke Tools für ihre individuellen Anforderungen zu nutzen und gleichzeitig von den neuesten Fortschritten im Bereich der KI-gestützten Sprachmodelle zu profitieren. Zukunftsgerichtet zeigt die Idee der Attention Sinks einen vielversprechenden Weg, um weitere Skalierungseffekte zu erzielen.
Die Kombination aus intelligentem Kontextmanagement und effizienten Speicherstrategien ist entscheidend, um die immer komplexeren Ansprüche an Sprachmodelle nachhaltig zu erfüllen. Dabei entstehen neue Optionen, um die Modelle nicht nur länger laufen zu lassen, sondern auch in puncto Genauigkeit und Robustheit weiterzuentwickeln. Abschließend lässt sich sagen, dass die Einführung von Attention Sinks bei Streaming-Sprachmodellen einen fundamentalen Paradigmenwechsel in der Handhabung langer, kontinuierlicher Texte markiert. Durch Optimierung von Speicher und Rechenleistung wird die Tür für eine Vielzahl neuer Anwendungen im Bereich natürlicher Sprache geöffnet, die bislang aus technischen Gründen eingeschränkt waren. Die Kombination aus theoretischer Analyse, praktischer Umsetzung und beeindruckender Performance macht dieses Forschungsgebiet besonders spannend und zukunftsträchtig.
Im dynamischen Umfeld der KI-Sprachverarbeitung werden solche effizienten Streaming-Methoden eine Schlüsselrolle spielen, wenn es darum geht, komplexe menschliche Kommunikation in Echtzeit präzise abzubilden und interaktive Systeme mit enormer Kapazität zu realisieren. Die Fortschritte, die das Konzept der Attention Sinks ermöglicht, sind ein großer Schritt auf dem Weg zu immer intelligenteren, ressourcenschonenderen und vielseitigeren Sprachmodellen.