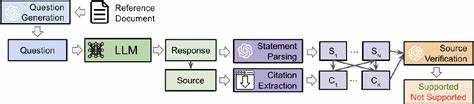
Die Nutzung großer Sprachmodelle, auch bekannt als Large Language Models (LLMs), erfährt gerade im medizinischen Bereich einen enormen Aufschwung. Das Potenzial solcher Modelle, Patientenfragen zu beantworten, Ärzte bei Diagnosen zu unterstützen oder medizinische Informationen zugänglicher zu machen, ist beachtlich. Doch eine entscheidende Herausforderung bleibt bestehen: In welchem Maße stützen diese Algorithmen ihre Aussagen auf glaubwürdige und relevante medizinische Quellen? Genau hier setzt ein automatisiertes Bewertungssystem an, das entwickelt wurde, um die Genauigkeit und Vertrauenswürdigkeit der von LLMs angegebenen medizinischen Referenzen zu prüfen.Ein solches Framework, bekannt unter dem Namen SourceCheckup, bildet die Grundlage, um Antworten von Sprachmodellen gezielt daraufhin zu untersuchen, ob und wie gut sie durch verlässliche Quellen belegt sind. Die Evaluation basiert auf einem umfangreichen Datensatz von 800 medizinischen Fragestellungen und über 58.
000 Paaren aus einzelnen Aussagen und zugehörigen Quellen. Die Auswertung mehrerer führender LLMs zeigt auf, dass häufig erhebliche Diskrepanzen zwischen den generierten Aussagen und den angegebenen Quellen vorliegen. Selbst bei Modellen mit Zugriff auf Echtzeit-Websuche, die eigentlich als besonders zuverlässig gelten, wird fast die Hälfte der vollständigen Antworten nicht vollständig durch die zitierten Quellen unterstützt.Diese Erkenntnisse werfen ein Schlaglicht auf die Problematik der sogenannten Halluzinationen von LLMs – dabei handelt es sich um generierte Inhalte, die keine Grundlage in echten Daten oder wissenschaftlichen Quellen haben. Gerade im medizinischen Zusammenhang kann dies gravierende Folgen für Patienten und Fachkräfte haben: Eine falsche oder unzureichend belegte Information kann zu Fehlentscheidungen, Vertrauensverlust oder sogar gesundheitlichen Risiken führen.
Das Fehlen zuverlässiger Quellenangaben schwächt das Vertrauen in die Technologie und stellt eine Barriere für die breite Akzeptanz in der klinischen Praxis dar.Das Framework SourceCheckup arbeitet mit einer Agentenarchitektur, in der der Prozess in mehrere Module gegliedert ist. Zunächst wird aus Referenztexten von medizinischen Webseiten, etwa der Mayo Clinic, automatisch eine präzise Frage generiert. Diese Frage stellt man dann verschiedenen LLMs, deren Antwort wiederum in einzelne medizinische Aussagen zerlegt wird. Im Anschluss werden die vom Modell angegebenen Quelleninhalte heruntergeladen, extrahiert und mit den entsprechenden Aussagen verglichen.
Eine KI-gestützte Quelle-Verifizierungsinstanz bewertet, ob die Quelle die Aussage tatsächlich unterstützt. Besonders herausragend ist, dass die automatische Quelle-Verifizierungsinstanz eine fast ebenso hohe Übereinstimmung mit medizinischen Fachärzten aufweist wie die Ärzte unter sich – ein wichtiges Indiz für die Verlässlichkeit des Ansatzes.Die Ergebnisse offenbaren zugleich eine große Bandbreite in der Leistungsfähigkeit der getesteten Sprachmodelle. Modelle ohne Zugriff auf aktuelle Webdaten neigen dazu, ungültige oder frei erfundene URLs zu generieren, deren Inhalt entweder nicht existiert oder nicht zum Thema passt. Modelle mit eingebundener Websuche reduzieren dieses Problem erheblich, erzeugen aber dennoch Antworten, deren vollständige inhaltliche Übereinstimmung mit den Quellen teilweise nur bei etwa der Hälfte aller Antworten gegeben ist.
Dies verdeutlicht, dass der bloße Zugriff auf Webinformationen nicht automatisch zum vollständigen Wegfall von Zitathaftungsfehlern führt.Neben der Validierung der Quellenangaben untersucht die Analyse auch, wie die Art der Frage die Qualität der Antworten beeinflusst. Beispielsweise zeigen Fragen von professionellen medizinischen Webseiten höhere Support-Raten für Quellen als Nutzerfragen aus sozialen Medien wie Reddit. Dies liegt daran, dass Suchanfragen von medizinischen Portalen meist klar formuliert sind und sich auf eindeutig definierte medizinische Fakten beziehen, während Nutzerfragen oft komplexer, offener und vieldeutiger sind. LLMs neigen bei letzterem dazu, spekulativ zu antworten und häufiger Aussagen zu generieren, die nicht direkt von den Quellen gestützt werden.
Ein weiteres zentrales Ergebnis ist die geografische und institutionelle Herkunft der zitierten Quellen. Der Großteil stammt aus US-amerikanischen Regierungs- oder gemeinnützigen Organisationen mit hoher Reputation, wie NIH oder CDC. Dies zeigt nicht nur die Präferenz der Modelle für etablierte Fachinhalte, sondern weist auch auf eine potenzielle Verzerrung hinsichtlich eines regional fokussierten medizinischen Wissensrahmens hin. Für eine globale Nutzung medizinischer LLMs ist die Vielfalt und Anpassung an verschiedene Gesundheitskontexte wichtig.Die Relevanz dieser Forschung zeigt sich auch in regulatorischer Hinsicht.
Aktuell gibt es keine FDA-Zulassung für die Nutzung von LLMs als medizinische Entscheidungsunterstützungstools. Die FDA zeigt jedoch erhebliches Interesse an der Schaffung von Regeln, die sicherstellen sollen, dass medizinische KI-Modelle vertrauenswürdige und nachvollziehbare Informationen liefern. Insbesondere die Fähigkeit, Auskünfte mit nachvollziehbaren Quellen zu belegen, ist aus Sicht der Zulassung und Haftbarkeit ein wichtiges Kriterium. Daher können automatisierte Frameworks wie SourceCheckup wertvolle Werkzeuge sein, um sowohl Modellherstellern als auch Regulierern eine objektive Bewertung der Quellenqualität zu ermöglichen.Darüber hinaus eröffnen sich durch die automatisierte Auswertung und Bearbeitung von Antworten neue Möglichkeiten, die Zuverlässigkeit von LLM-Antworten zu verbessern.
Das hier vorgestellte Agentensystem SourceCleanup beispielsweise bearbeitet nicht unterstützte oder fehlerhafte Aussagen, entfernt sie oder passt sie innerhalt des Rahmens der Quellen an. Erste Tests zeigen eine hohe Erfolgsquote bei der Korrektur. Dies deutet darauf hin, dass integrierte Editoren für Quellen-Herstellung in der Zukunft zahlreiche Fehler verhindern könnten.Aus methodischer Sicht ist die Nutzung von KI, insbesondere von GPT-4o, sowohl für die Bewertung als auch für die Erzeugung von Fragen und die Zerlegung der Antworten ein Meilenstein. Dabei wurde aber auch der mögliche Bias analysiert, indem alternative Modelle wie Claude Sonnet eingesetzt wurden.
Die Ergebnisse bestätigen, dass die Automatisierung der Bewertung nicht zugunsten eines speziellen Modells verzerrt ist, sondern objektiv funktioniert.Die technische Grundlage des Frameworks beruht auf dem Vergleich von Aussagen mit der gesamten Bandbreite der angegebenen Quellen, ohne dass eine direkte Verknüpfung zwischen einzelnen Aussagen und spezifischen Quellen zwingend vorausgesetzt wird. Dies erlaubt eine realistischere Bewertung, da Modelle häufig eine Liste von Quellen am Ende der Antwort liefern, ohne diese präzise einzelnen Teilen zuordnen zu können. Dennoch zeigt eine Analyse, dass auch bei Berücksichtigung mehrerer Quellen zur Unterstützung einer Aussage der Anteil der tatsächlich fundierten Aussagen weiterhin begrenzt bleibt, was den Handlungsbedarf unterstreicht.Die Herausforderungen dieser Art von automatisierter Quellenbewertung liegen vor allem in der Komplexität medizinischer Informationen, welche vielfältige Interpretationen zulassen.
Unterschiedliche Studien oder Quellen können leicht variierende Daten präsentieren, die dennoch valide sind. Beispielsweise finden sich unterschiedliche Altersgruppenangaben bei der Prävalenz einer Erkrankung, ohne dass sich eine Aussage per se als falsch erweisen muss. Ein automatischer Verifizierungsprozess muss daher auch die Variabilität und subjektiven Aspekte medizinischer Aussagen mit berücksichtigen, ohne zu hart zu werten.Als zukunftsweisend ist die Verfügbarkeit des Datensatzes mit den 800 medizinischen Fragen und den mehr als 58.000 Aussage-Quellen-Paaren zu sehen.
Diese Ressource wird es ermöglichen, die Leistungsfähigkeit von LLMs über Zeit hinweg vergleichbar zu messen und Weiterentwicklungen besser zu bewerten. Geschlossene Modelle können so mit offenen Alternativen verglichen und trainiert werden, um eine höhere medizinische Zuverlässigkeit zu erreichen.Nicht zuletzt hat die Untersuchung auch eine gesellschaftliche Dimension: Die Verlässlichkeit von medizinischen Quellenangaben bei LLMs beeinflusst direkt das Vertrauen von Medizinern, Patienten und Regulatoren in die Technologie. Falsche oder nicht belegbare Auskünfte haben nicht nur das Potenzial, gesundheitlichen Schaden zu verursachen, sondern können auch dazu führen, dass vielversprechende Innovationen weniger schnell adaptiert werden. Eine transparente, automatisierte und skalierbare Bewertung der Quellenqualität ist damit eine wichtige Grundlage für die verantwortungsvolle Integration großer Sprachmodelle in den medizinischen Alltag.
Zusammenfassend lässt sich festhalten, dass automatisierte Frameworks zur Überprüfung der Quellenangaben von LLM-Antworten essentiell sind, um die wissenschaftliche Fundierung, Transparenz und Sicherheit bei der Nutzung von KI im Gesundheitswesen sicherzustellen. Die Ergebnisse zeigen gleichzeitig den aktuellen Stand der Technik, weisen auf bestehende Defizite und geben zugleich wichtige Impulse für zukünftige Verbesserungen. Vor allem die Kombination aus automatisierter Erkennung, menschlicher Expertendienste und begleitender Modelloptimierung wird langfristig den medizinischen Sprachmodellen zur notwendigen Vertrauenswürdigkeit verhelfen. Die Vision eines medizinisch kompetenten, transparenten und zuverlässigen KI-Assistenten rückt damit ein gutes Stück näher.