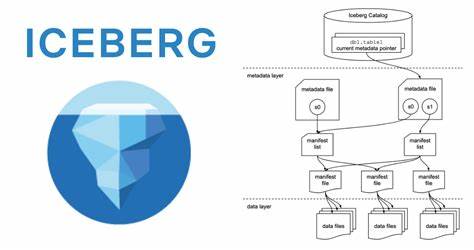
In der heutigen datengetriebenen Welt wächst das Volumen an Informationen exponentiell. Unternehmen stehen vor der Herausforderung, riesige Mengen strukturierter und unstrukturierter Daten nicht nur zu speichern, sondern auch effizient auszuwerten. Genau hier setzen moderne Lakehouse-Architekturen an, die die Vorteile von Data Lakes und Data Warehouses kombinieren. Apache Iceberg hat sich als führender Table-Format-Standard etabliert, der Ordnung und Struktur in die oftmals heterogenen Datenlandschaften bringt. Durch die kürzlich erfolgte Integration von Vortex in Apache Iceberg eröffnen sich neue Möglichkeiten zur drastischen Beschleunigung von Abfragen – Geschwindigkeitsvorteile von bis zu dem Vierfachen wurden in Benchmarks erreicht.
Doch wie funktioniert dieser Fortschritt, und warum ist er so bedeutend? Ein tieferer Blick lohnt sich. Die Bedeutung von Table-Formaten in der modernen Datenarchitektur lässt sich kaum unterschätzen. Während Data Lakes riesige Mengen roher Daten in offenen Formaten wie Parquet oder ORC speichern, fehlt oft die dringend benötigte Schicht zur Datenorganisation und Steuerung. Dieses Versäumnis führt zu Problemen bei gleichzeitigen Zugriffen, inkonsistenten Schemata und einer Flut von kleinen Dateien, die Abfragen stark verlangsamen. Table-Formate wie Apache Iceberg lösen diese Probleme durch eine Verwaltungsschicht, welche die physische Speicherung von Daten abstrahiert und sowohl Transaktionen als auch Schema-Evolution unterstützt.
Iceberg ist für seine Leistungsfähigkeit, Erweiterbarkeit und breite Branchenakzeptanz bekannt – viele große Firmen nutzen es bereits erfolgreich. Vortex erweitert diesen Ansatz durch ein modernes, in Rust entwickeltes Dateiformat, das sowohl für klassische OLAP-Workloads als auch für anspruchsvolle KI- und ML-Anwendungen optimiert ist. Im Vergleich zum etablierten Parquet-Format liefert Vortex durch seine effizienten, leichtgewichtigen Kompressionen und Arrow-kompatible In-Memory-Darstellungen signifikante Performancevorteile. Durch den Einsatz fein granuliertem Zone Map-Indexing kann Vortex Daten nicht nur auf File-Ebene, sondern bis auf einzelne Datenabschnitte intelligent überspringen, was Leseoperationen deutlich beschleunigt. Die Kombination aus besserer Komprimierung und selektiver Dekodierung trägt maßgeblich zur Geschwindigkeit von Abfragen bei.
Die technische Herausforderung bei der Integration von Vortex in die bestehende Apache Iceberg-Architektur liegt unter anderem darin, dass Iceberg traditionell nur wenige Empfängerformate unterstützt. Vortex hingegen ist eine native Rust-Bibliothek, während Iceberg hauptsächlich in Java implementiert ist. Dies führte zu einer kreativen Lösung, bei der eine Brücke über das Java Native Interface (JNI) geschlagen wurde, um die Vortex-Komponenten in Spark-Abfragen nutzen zu können. Statt Vortex vollständig in Java neu zu implementieren, was enormen Entwicklungsaufwand und Performanceeinbußen bedeutet hätte, wurde die Effizienz von Rust genutzt und durch JNI funktional eingebunden. Diese native Anbindung erlaubt einen direkten und performanten Zugriff auf Vortex-Dateien aus Spark heraus.
Dabei wurde ein schlanker Wrapper entwickelt, der Vortex-Dateien als Java-Objekte repräsentiert und die Speicherverwaltung über das AutoCloseable-Pattern sicherstellt. So wird verhindert, dass Speicherlecks oder unsichere Zugriffe entstehen – ein kritischer Faktor bei Anwendungen mit hohem Datendurchsatz und langer Laufzeit. Ein weiteres wesentliches technisches Hindernis war die sogenannte "Splittbarkeit" von Dateien in Iceberg. Parquet-Dateien lassen sich bytegenau in Segmente unterteilen, die gleichzeitig von mehreren Tasks gelesen werden können. Vortex nutzte hingegen ein flexibleres Layout, das keine zusammenhängenden Bytebereiche für parallele Verarbeitung garantierte.
Anfangs führte dies dazu, dass Vortex-Dateien im Iceberg-Ökosystem nicht optimal gesplittet wurden, was die Parallelität bei der Datenverarbeitung einschränkte und die Leistung stark beeinträchtigte. Um diesen Nachteil zu beheben, wurde das Konzept der "row-splittability" eingeführt, bei dem Iceberg anstelle von Byte-Bereichen für die Parallelisierung Datenbereiche auf Basis von Zeilen angibt. Dies ermöglichte eine deutlich bessere Lastverteilung und parallele Verarbeitung auch von Vortex-Dateien in Spark. Die Folgewirkung war eine erhebliche Steigerung der Abfragegeschwindigkeit mit vergleichbarer Task-Verteilung wie bei Parquet-Dateien. Benchmark-Tests auf Azure mit einer konventionellen Spark-Einzelknoten-Konfiguration zeigten beeindruckende Resultate.
So konnten bei Analysen auf dem TPC-H Datensatz (Scale Factor 100) durch den Einsatz von Vortex gegenüber Parquet bei einigen komplexen Abfragen, beispielsweise bei Joins, Geschwindigkeiten von bis zu 4x erreicht werden. Die effektive Nutzung von Zone Maps, Arrow-kompatibler Vektor-Verarbeitung und der native Umgang mit Kompressionstechniken sorgten dafür, dass nicht nur Daten schneller gelesen, sondern auch effizienter verarbeitet wurden. Die reduzierte CPU-Belastung durch optimierte Dekodierung trug zusätzlich zur besseren Gesamteffizienz bei. Diese Integration steht exemplarisch für die aktuelle Entwicklung in der Datenverarbeitungslandschaft, die sich durch modularere Architekturen, plattformübergreifende Komponenten und native Performance-Optimierungen auszeichnet. Insbesondere Unternehmen, die vielfältige Workloads – von klassischen BI-Abfragen bis zu KI/ML-Modellen – parallel durchführen wollen, profitieren maßgeblich von solchen Innovationen.
Die Zusammenarbeit mit Partnern wie Microsofts Gray Systems Lab spielt dabei eine entscheidende Rolle. Gemeinsam wurde die Iceberg-Plattform noch anpassungsfähiger gemacht und die Grundlage für eine bessere Unterstützung zukünftiger Dateiformate gelegt. Zudem trägt die geplante Standardisierung von APIs für neue File-Formate in Iceberg zur Förderung einer lebendigen Open-Source-Community bei, die die schnelle Implementierung neuer Technologien und Features ermöglicht. Ein weiterer spannender Entwicklungszweig ist die Unterstützung von sogenannten Deletion Vectors in Vortex, die Merge-on-Read-Verfahren mit differenzierten Löschoperationen erlauben. Dies erhöht die Effizienz bei inkrementellen Datenaktualisierungen und integriert sich nahtlos in die Transaktionssteuerung von Iceberg.
Nebenbei ist die Umsetzung von Iceberg-kompatibler Verschlüsselung geplant, um auch im Bereich Datensicherheit und Compliance state-of-the-art Lösungen anzubieten. Für datengetriebene Unternehmen ergeben sich daraus zahlreiche Vorteile. Die Möglichkeit, Abfragen bis zu viermal schneller durchzuführen, bedeutet kürzere Zeit bis zur Erkenntnis, schnellere Reaktionszeiten im Geschäft und effizienteren Ressourceneinsatz. Gleichzeitig bleiben Flexibilität und Erweiterbarkeit bestehen, da Vortex als offenes Format kontinuierlich weiterentwickelt wird und sich gut in bestehende Ökosysteme einfügt. Wer heute mit Apache Iceberg arbeitet oder den Einstieg plant, sollte die Möglichkeiten von Vortex genau beobachten und bei passenden Anwendungsfällen erwägen.