In der heutigen digitalen Welt spielt die Technologie der Sprachsynthese eine immer bedeutendere Rolle. Anwendungen von assistiven Technologien über Hörbücher bis hin zu automatisierten Kundendienstsystemen profitieren immens von qualitativ hochwertigem Text-zu-Sprache (TTS). Besonders anspruchsvoll wird es, wenn große Textdateien schnell und effizient in Sprache umgewandelt werden sollen. Genau an dieser Stelle setzt die Kombination aus Piper TTS und einer eigens entwickelten GUI/API-Lösung an, die speziell für die Bewältigung umfangreicher Textmengen optimiert wurde. Piper TTS ist ein moderner, leistungsfähiger und quelloffener Text-zu-Sprache-Generator, der für präzise und natürliche Sprachsynthese bekannt ist.
Die Herausforderung besteht darin, große Textdaten so zu verarbeiten, dass die Synthese nicht nur qualitativ hochwertig bleibt, sondern auch zeitlich effizient abläuft. Die realisierte Lösung verknüpft die Robustheit von Piper mit einer API, die von einem Flask-Server bereitgestellt wird, und einer benutzerfreundlichen GUI basierend auf PySide6. Dieses Konzept ermöglicht es, größere Textdateien in handhabbare Stücke aufzuteilen, parallel zu verarbeiten und letztlich zu einem einheitlichen Audioausgang zusammenzufügen. Das Kernprinzip beruht auf dem sogenannten Chunking, bei dem der gesamte Text automatisch in kleinere Abschnitte untergliedert wird. Diese Aufsplittung ermöglicht es, die Segmente unabhängig voneinander zu den Sprachsynthese-Modellen zu schicken.
Durch die parallele Bearbeitung, realisiert über moderne Multi-Threading-Technologien wie Python's ThreadPoolExecutor, reduzieren sich die Gesamtverarbeitungszeiten erheblich. Ein weiterer Vorteil ist die Skalierbarkeit – egal ob der Server lokal, in der Cloud oder auf einem GitHub Codespace läuft, die Architektur erlaubt flexible Ressourcen-Nutzung. Der API-Server wurde mit Flask entwickelt und dient als Bindeglied zwischen Piper TTS und dem grafischen Interface. Er akzeptiert Textinput über HTTP-Anfragen, verarbeitet diesen mit Piper und liefert das Ergebnis als WAV-Audiodatei zurück. Besonderer Wert wurde auf die einfache Konfiguration gelegt: Der Betreiber muss lediglich die Pfade für den Piper-Executable, das Sprachmodell und die zugehörige Konfigurationsdatei anpassen.
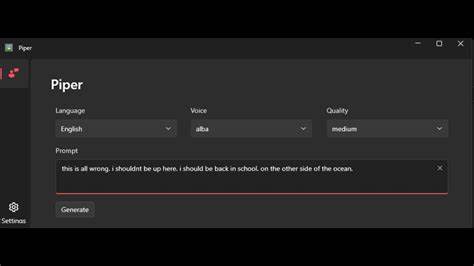
Für den produktiven Einsatz empfiehlt sich, den Server mittels Gunicorn zu betreiben, um mehrere Worker-Prozesse zu ermöglichen und damit die Anfragenverarbeitung zu optimieren. Das Gegenstück zum Server ist die GUI-Anwendung, die mit PySide6 realisiert wurde und eine intuitive Benutzeroberfläche für Endanwender bietet. Über diese Schnittstelle lässt sich der API-Endpunkt definieren, eine Eingabedatei auswählen und ein Zielpfad für die Ausgabedatei bestimmen. Sobald der Anwender den Syntheseprozess startet, erfolgt die Datenaufteilung, parallele API-Anfragen zur Sprachsynthese und das anschließende Zusammenfügen der Audiofragmente vollautomatisch und transparent. Fortschrittsanzeigen und Statuslogs vermitteln dabei jederzeit nachvollziehbare Transparenz über den Ablauf.
Die Entwicklung dieser integrierten Lösung bringt zahlreiche Vorteile mit sich. Zum einen wird der Zeitaufwand gemäß der Textgröße drastisch reduziert, weil parallele Abläufe den Engpass der sequenziellen Verarbeitung aufbrechen. Zum anderen wird die Bedienbarkeit vereinfacht, da Nutzer nicht mehr mit komplexen Kommandozeilen oder manuellen Dateiverwaltungen kämpfen müssen. Die Kombination aus Server-Backend und Desktop-GUI macht die Technologie außerdem zugänglich für ein breiteres Publikum, vom Entwickler bis zum Anwender ohne tiefgehendes technisches Know-how. Technisch gesehen ermöglicht die Verwendung von vortrainierten ONNX-Modellen innerhalb von Piper TTS eine überaus effiziente Sprachgenerierung.
Die API vermittelt eine moderne Microservice-Struktur, die nicht nur IP-basiert erreichbar ist, sondern sich auch problemlos in bestehende Systeme über REST-Calls integrieren lässt. Dies eröffnet Möglichkeiten für Unternehmenslösungen, bei denen sprachbasierte Automatisierung und Barrierefreiheit unabdingbar sind. Ein wichtiger Punkt, der bei der Einrichtung der Lösung beachtet werden muss, ist die Sicherheit. Da der API-Server standardmäßig ohne Authentifizierungs- oder Sicherheitsmechanismen ausgeliefert wird, sollte er keinesfalls ungeschützt im offenen Internet betrieben werden. Stattdessen empfiehlt sich ein geschützter Betrieb in vertrauenswürdigen Netzwerken oder die Implementierung zusätzlicher Sicherheitsschichten wie API-Keys, Authentifizierungsmiddlewares oder HTTPS-Verschlüsselung.
Die Kombination von Piper TTS mit einer darauf aufbauenden API und GUI stellt somit eine ideale Herangehensweise dar, um Text-zu-Sprache-Prozesse vor allem bei großen Textmengen performant und benutzerfreundlich zu realisieren. Das Projekt zeigt, wie Open-Source-Technologien effizient genutzt und durch clevere Software-Architekturen ergänzt werden können, um leistungsfähige, praxisgerechte Lösungen zu schaffen. Für zukünftige Erweiterungen bieten sich unter anderem Funktionen wie die Integration multipler Stimmen, die direkte Ausgabe an Lautsprecher oder eine Cloud-basierte Version an, die elastic skalierbar ist und beliebig große Dateien ohne lokale Hardwarebegrenzungen verarbeiten kann. Auf lange Sicht könnte sich eine weitergehende Automatisierung durch KI-gesteuerte Textanalyse etablieren, die die Textaufteilung und Intonation noch natürlicher gestaltet. Insgesamt verdeutlicht dieses Projekt, wie technische Innovation und pragmatische Softwareentwicklung gemeinsam dazu beitragen, Komfort und Effizienz in der Sprachsynthese deutlich zu steigern.
Die kombinierte Nutzung von Piper TTS mit einer RESTful API und einer benutzerfreundlichen GUI bietet sowohl für Entwickler als auch Endanwender eine attraktive Lösung zur Sprachgenerierung auf hohem Niveau und mit optimiertem Workflow.