Große Sprachmodelle, auch als Large Language Models (LLMs) bekannt, erleben derzeit eine rasante Entwicklung und finden zunehmend Anwendung in verschiedensten Bereichen, insbesondere auch im Gesundheitswesen. Sie bieten die Möglichkeit, medizinische Fragen zu beantworten oder erste Informationen zu Symptomen bereitzustellen. Doch trotz ihrer beeindruckenden sprachlichen Fähigkeiten haben LLMs immer wieder mit einem entscheidenden Problem zu kämpfen: der Zuverlässigkeit der Informationen und der korrekten Zitierung medizinischer Quellen. Die Frage, wie gut diese Modelle tatsächlich glaubwürdige und relevante Quellen in ihren Antworten nutzen und angeben, gewinnt angesichts der zunehmenden Nutzung in sensiblen Bereichen eine immense Bedeutung. Im Zuge dieser Herausforderung wurde ein automatisiertes Bewertungssystem mit dem Namen SourceCheckup entwickelt.
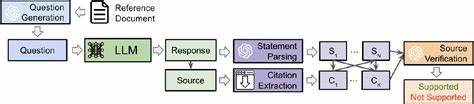
Ziel dieses Frameworks ist es, die Fähigkeit von LLMs zu analysieren und zu bewerten, ob die medizinischen Referenzen, die sie zitieren, tatsächlich die Grundlage ihrer Antworten bilden und die getätigten Aussagen stützen. Dies ist von besonderer Relevanz, da fehlerhafte oder halluzinierte Quellen nicht nur das Vertrauen der Nutzer beeinträchtigen, sondern in kritischen Situationen auch gesundheitliche Risiken mit sich bringen können. SourceCheckup verfolgt einen innovativen agentenbasierten Ansatz. Das Framework ist in mehrere Module unterteilt, die gemeinsam den gesamten Prozess von der Frage bis zur Überprüfung der Antworten und Quellen abdecken. Zunächst werden medizinische Fragen generiert oder echte Nutzeranfragen gesammelt, anschließend beantworten verschiedene LLMs diese Fragen, wobei sie Quellen angeben sollen.
Danach werden die Antworten in einzelne medizinische Aussagen zerlegt, um diese gezielt mit den angegebenen Quellen abzugleichen. Ein weiterer Bestandteil des Frameworks prüft automatisiert, ob die zitierte Quelle tatsächlich die jeweilige Aussage unterstützt. Die Validierung dieses automatisierten Verfahrens erfolgte anhand eines umfangreichen Datensatzes von 800 medizinischen Fragen mit mehr als 58.000 Paaren aus Aussagen und Quellen. Dabei zeigte sich, dass die Übereinstimmung des SourceCheckup-Systems mit der Beurteilung von Fachärzten bei annähernd 89 Prozent liegt – ein Wert, der sogar über dem durchschnittlichen Konsens zwischen Ärzten liegt.
Dies unterstreicht die hohe Zuverlässigkeit und Effizienz des Frameworks, insbesondere im Vergleich zu manuellen Überprüfungen, die deutlich zeitaufwändiger und kostenintensiver sind. Die Studie wendete das Framework auf sieben der derzeit führenden kommerziell verfügbaren LLMs an, darunter bekannte Modelle wie GPT-4o in verschiedenen Varianten, Claude v2.1, Mistral Medium und Gemini Ultra 1.0. Überraschenderweise ergab die Analyse, dass trotz der Fortschritte in der Modellarchitektur und Integration von Websuchfunktionalitäten ein erheblicher Anteil der zitierten Quellen die Aussagen nicht vollständig stützt oder teilweise sogar ihnen widerspricht.
So waren zwischen 50 und 90 Prozent der Antworten nur unzureichend oder gar nicht durch die angegebenen Quellen belegt. Selbst der leistungsstarke GPT-4o mit aktivierter Websuche zeigte, dass etwa 30 Prozent der einzelnen Aussagen nicht durch eine angegebene Quelle unterstützt wurden. Auf Ebene der gesamten Antworten konnte man nur in rund 55 Prozent der Fälle eine vollständige Quellenunterstützung feststellen. Ein wichtiger Faktor, der sich in der Untersuchung zeigte, war die Rolle der Websuche beziehungsweise des Retrieval-Augmented-Generation-Ansatzes (RAG). Modelle mit Zugriff auf aktuelle Webinhalte konnten zwar die korrekte URL-Halluzination vermeiden, lieferten aber dennoch häufig Quellen, die nicht alle präsentierten Aussagen stützten.
Die Modelle ohne Webzugriff zeigten dagegen eine teils hohe Rate an ungültigen oder frei erfundenen URLs, was ihre Glaubwürdigkeit zusätzlich beeinträchtigte. Besonders auffällig war, dass Open-Source-Modelle wie Llama 2 und Meditron kaum in der Lage waren, valide Zitate zu erzeugen. Diese Diskrepanz zwischen Zitierfähigkeit und inhaltlicher Faktenbasis stellt die praktische Umsetzbarkeit solcher Modelle in klinischen oder beratenden Szenarien infrage. Die Art der gestellten Frage beeinflusste ebenfalls maßgeblich die Qualität der Zitate und deren Relevanz. So ergaben sich deutlich bessere Werte bei Fragen, die aus standardisierten medizinischen Quellen wie der Mayo Clinic stammten, als bei Nutzeranfragen aus Foren wie Reddit.
Die letzteren beinhalten oft komplexere, mehrdeutige oder offene Fragestellungen, die eine differenziertere Behandlung erfordern. Dies lässt vermuten, dass die Sprachmodelle bei einfach zu beantwortenden, dokumentbasierten Fragen ihre Quellen besser einbetten können, während offene Diskussionen und seltenere Fragestellungen starkere Defizite offenbaren. Das Thema der Quellenqualität ist untrennbar verbunden mit dem gesellschaftlichen Vertrauen und der Sicherheitsdebatte im Einsatz von Künstlicher Intelligenz in sensiblen Feldern wie dem Gesundheitswesen. Ein falsch zitierendes Modell kann leicht Fehlinformationen verbreiten, was gerade in der medizinischen Beratung gravierende Folgen haben kann. Darüber hinaus spielt die regulatorische Dimension eine erhebliche Rolle: Behörden wie die US Food and Drug Administration (FDA) fordern zunehmend, dass KI-Systeme, die medizinische Entscheidungshilfen liefern, transparent und auditierbar sein müssen.
Dabei ist das Nachweisen von echten und sinnvollen Quellen ein Teil der Compliance und Vertrauensbildung gegenüber Ärzten und Patienten. Die automatisierte Bewertung durch SourceCheckup ermöglicht somit nicht nur einen besseren Einblick in die gegenwärtigen Stärken und Schwächen von LLMs, sondern schafft auch eine Grundlage für die Weiterentwicklung und Regulierung. Die Möglichkeit, die Zitiertreue in großen Maßstäben und objektiv zu beurteilen, hilft Entwicklern dabei, gezielt Verbesserungen anzustoßen und Fehlentwicklungen zu vermeiden. Ein weiterer spannender Aspekt der Studie befasste sich mit der Nachbearbeitung der Modellantworten. Mit einem sogenannten SourceCleanup-Agenten wurden nicht unterstützte Aussagen entweder entfernt oder so modifiziert, dass sie nachträglich mit den Quellen harmonieren.
Diese Reparaturen erfolgten automatisiert durch ein weiteres LLM, das die Aufgabe hatte, Inhalte in Einklang mit den tatsächlichen Quellen zu bringen. Die Ergebnisse zeigten, dass mehr als 85 Prozent der bearbeiteten Aussagen nach der Modifikation durch den Agenten tatsächlich vollständig durch die Quellen unterstützt wurden. Dieses Verfahren birgt großes Potenzial, um in Zukunft die Glaubwürdigkeit von automatisch erzeugten medizinischen Texten zu erhöhen und den praktischen Einsatz zu fördern. Die Verteilung der Quellen selbst zeigte ebenfalls interessante Muster. Die meisten URLs kamen von etablierten Gesundheitswebseiten wie der Mayo Clinic oder von Regierungsseiten wie NIH oder CDC.
Zudem wurden überwiegend US-amerikanische Quellen angegeben, was auf einen kulturellen und regulatorischen Fokus der Modelle schließen lässt. Dies könnte jedoch bedeuten, dass medizinische Informationen aus anderen Regionen oder Kontexten weniger repräsentiert werden, was für globale Nutzerschaften eine Herausforderung darstellt. Zusammenfassend verdeutlichen die Ergebnisse, dass trotz großer Fortschritte bei der Leistungsfähigkeit von LLMs weiterhin eine signifikante Lücke in der zuverlässigen und nachvollziehbaren Zitierung von medizinischen Quellen besteht. Dies gefährdet die Vertrauenswürdigkeit der Modelle im klinischen Umfeld und zeigt den Bedarf an gezielten Maßnahmen zur Verbesserung der Quellenauthentifizierung und Faktenpräsentation. Automatisierte Frameworks wie SourceCheckup bieten hierfür eine effektive Methode, sowohl Entwickler als auch Anwender dabei zu unterstützen, die Qualität von KI-generierten medizinischen Texten besser zu bewerten und weiterzuentwickeln.
Der Einsatz von LLMs in der Medizin sollte daher stets mit einem kritischen Blick auf die Qualität und Überprüfbarkeit der Quellen erfolgen. Gleichzeitig eröffnen solche Technologien die Möglichkeit, Wissenschaft und Gesundheitsversorgung durch schnelle und gut belegte Informationsbereitstellung zu bereichern – vorausgesetzt, dass die Modelle ausreichend kontrollierbar und vertrauenswürdig sind. Die Verbindung von automatisierten Bewertungssystemen, menschlicher Expertenkontrolle und verbesserten Trainingsmethoden wird in den kommenden Jahren entscheidend sein, um das volle Potenzial der KI im medizinischen Bereich verantwortungsvoll und sicher zu nutzen. Die Zukunft medizinischer AI-Systeme wird maßgeblich davon abhängen, wie gut wir Vertrauen schaffen können. Die Fähigkeit, medizinisch relevante Quellen korrekt und nachvollziehbar zu zitieren, ist ein zentraler Aspekt dieses Vertrauens.
Forschung wie die Entwicklung von SourceCheckup ebnet den Weg, um dieses Vertrauen durch systematische Prüfung und Verbesserung technischer Modelle zu realisieren – ein entscheidender Schritt, um KI-gestützte medizinische Anwendungen zur verlässlichen Unterstützung von Patienten und Fachpersonal zu machen.