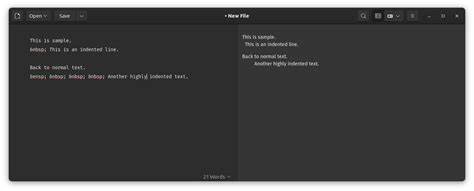
Markdown hat sich in den letzten Jahren zu einem der beliebtesten Formate für die Erstellung und Formatierung von Texten im Web und in diversen Anwendungen entwickelt. Seine einfache Syntax ermöglicht es sowohl Einsteigern als auch Profis, Inhalte schnell und klar strukturiert darzustellen. Trotz dieser Vorteile fehlt es vielen Markdown-Viewern an ausgefeilten Funktionen wie der automatischen Einrückung von Abschnitten, was besonders bei langen oder komplex verschachtelten Dokumenten die Lesbarkeit und Navigation erheblich erschwert. Benutzer müssen oft manuell auf Überschriftenebenen achten, um sich im Text zurechtzufinden. Die automatische Einrückung könnte die visuelle Struktur von Markdown-Dokumenten deutlich verbessern, indem sie unterschiedliche Ebenen klar erkennbar macht und somit das Scannen und Verstehen erleichtert.
Interessanterweise verfügen zahlreiche Textverarbeitungsprogramme bereits über solche Funktionen für Gliederungen, doch für Markdown-Editoren oder -Viewer ist dies bislang eher die Ausnahme. Die Gründe dafür sind vielfältig: Zum einen ist Markdown als leichtgewichtiger Standard konzipiert, der bewusst auf komplexe Formatierungen verzichtet. Zum anderen stellt die dynamische Einrückung im Browser oder in Desktop-Anwendungen unter Berücksichtigung der flexiblen Markdown-Syntax eine technische Herausforderung dar. Angesichts dieser Lücke haben viele Entwickler nach neuen Wegen gesucht, um den Workflow mit Markdown-Dokumenten zu verbessern. In den letzten Monaten hat sich vor allem im Bereich der künstlichen Intelligenz viel bewegt.
Große Sprachmodelle, sogenannte Large Language Models (LLMs), zeigen zunehmend beeindruckende Fähigkeiten beim Erzeugen und Verstehen von Code. Von der automatisierten Texterstellung bis zur Programmierung soll KI viele Aufgaben vereinfachen und beschleunigen. Vor diesem Hintergrund ergibt sich die Frage, ob ein LLM in der Lage ist, „on the fly“ einen funktionalen Markdown-Viewer zu entwickeln, der Abschnittsebenen automatisch erkennt und mit entsprechender Einrückung darstellt. Dies wäre ein interessantes Experiment und würde die Grenzen aktueller KI-Technologien im praktischen Einsatz aufzeigen. Anhand einer konkreten Nutzeranfrage aus der Entwickler-Community, bei der es darum geht, einen einfachen Web-basierten Markdown-Viewer mit automatischer Einrückung zu erstellen, wurde getestet, ob die führenden KI-Modelle diese Aufgabe erfüllen können.
Die Vorgabe war klar: Eine Anwendung sollte lokale Markdown-Dateien öffnen können und den Text so darstellen, dass die Überschriftenebenen visuell durch Einrückungen differenziert werden. Programmiert in TypeScript mit Node.js oder Bun als Laufzeitumgebung sollte das Tool auf macOS lauffähig sein. Die bisherigen Ergebnisse sind ernüchternd. Viele der getesteten KI-Modelle lieferten entweder gar keinen lauffähigen Code oder das Ergebnis erfüllte die Erwartungen lediglich unzureichend.
Meist fehlte es an korrekter Erkennung der Überschriftenebenen oder an der korrekten Anpassung der Einrückung im gerenderten Output. Manche Modelle erzeugten code-technisch unbrauchbare Ergebnisse oder vergaßen wichtige Komponenten wie den Dateizugriff, die Textparsing-Logik oder die eigentliche visuelle Gestaltung. Diese Erkenntnisse sind aus mehreren Gründen nicht verwunderlich. Obwohl LLMs inzwischen komplexe Programmiersprachen verstehen und generieren können, ist die Implementierung einer benutzerfreundlichen Anwendung mit spezifischen Anforderungen nach wie vor eine Herausforderung. Das Verständnis der semantischen Bedeutung verschiedener Markdown-Elemente und deren Überführung in ein visuelles Layout mit Einrückung erfordert neben syntaktischem Parsing auch Kenntnisse über die Präsentation und Benutzerführung.
Zudem variieren Anforderungen je nach Kontext, sodass eine vorgefertigte Lösung nicht unmittelbar auf Anhieb aus einer einzigen Eingabe erzeugt werden kann. Das Fehlen von automatischer Einrückung in den meisten Markdown-Viewern spiegelt möglicherweise auch ein geringeres Nutzerinteresse oder die Komplexität der Umsetzung wider. Für Entwickler liegt der Fokus oft eher auf der korrekten Interpretation von Markdown-Syntax und der Darstellung der Grundelemente wie Fettdruck, Listen oder Codeblöcke. Funktionalitäten wie Abschnittsfaltung oder Einrückung von Ebenen, die im professionellen Textverarbeitungsbereich üblich sind, sind für viele Anwendungen noch Zukunftsmusik. Die Entwicklung eines solchen Features erfordert eine präzise Analyse des Dokumentinhalts, um die richtige Einrückung je nach Überschriftenebene dynamisch anzuwenden.
Technisch kann dies durch Parsen des Markdown-Codes in eine strukturierte Baumstruktur erfolgen, anschließend muss die visuelle Komponente entsprechend angepasst werden. Im Web-Umfeld stellen sich hierbei Fragen der Performance, der Benutzerfreundlichkeit und der Darstellung auf verschiedenen Geräten. Große Sprachmodelle können bei der automatischen Generierung von Code helfen, etwa um Basisfunktionen oder Prototypen zu erstellen. Dass sie auf Anhieb eine vollständig funktionale und benutzerfreundliche Anwendung erstellen, bleibt jedoch vorerst eine Ausnahme. Die menschliche Feinabstimmung ist nötig, um Fehler auszumerzen, Logik zu implementieren und Usability-Aspekte zu berücksichtigen.
Die nächste logische Stufe der Entwicklung wäre die Integration solcher KI-Lösungen in bestehende Entwicklungsumgebungen, sodass sie Entwicklern als intelligente Assistenten zur Seite stehen. Sie könnten zügig Grundgerüste erstellen und repetitive Aufgaben übernehmen, während die endgültige Umsetzung in menschlicher Hand bleibt. Die Herausforderung beim Aufbau eines Markdown-Viewers mit automatischer Einrückung bleibt daher aktuell vor allem ein Programmier- und Designproblem. KI kann hierbei unterstützend wirken, doch der Mensch behält die Kontrolle über die Details. Die Vision jedoch ist vielversprechend: Intelligente Editor-Lösungen, die Inhalte nicht nur formatieren, sondern semantisch analysieren und visuell optimieren, würden das Arbeiten mit Markdown und anderen Textformaten deutlich verbessern.
Ein weiterer spannender Aspekt ist die Möglichkeit, neben der Einrückung eine dynamische Abschnittsfaltung zur Verfügung zu stellen. Diese Funktion ist aus der Softwareentwicklung und umfangreichen Textverarbeitungsprogrammen bekannt und ermöglicht es, längere Dokumente kompakt darzustellen. Auch hier könnten KI-basierte Ansätze helfen, die Umsetzung zu beschleunigen und intuitivere Werkzeuge zu schaffen. Die Kombination aus automatischer Einrückung und Abschnittsfaltung würde das Lesen und Navigieren großer Markdown-Dokumente revolutionieren. Betrachtet man den aktuellen Stand, so befindet sich die Technik erst am Anfang dieser Entwicklung.
Die Nachfrage und das Interesse in der Community sind vorhanden, doch die Integration komplexer Features in leichtgewichtige Markdown-Tools erfordert Zeit und Engagement. Der Einsatz von KI-unterstützter Programmierung könnte diese Entwicklung künftig entscheidend beschleunigen. Zusammenfassend lässt sich festhalten, dass die automatische Einrückung in Markdown-Viewern ein wichtiger Schritt zur besseren Lesbarkeit und Strukturierung von Dokumenten wäre. Die derzeit genutzten KI-Modelle sind noch nicht in der Lage, diese Herausforderung auf Anhieb vollständig zu lösen. Sie können als hilfreiche Werkzeuge dienen, um die Grundfunktionen zu programmieren oder Impulse zu geben, doch die finale Umsetzung benötigt nach wie vor menschliche Expertise.
Die Zukunft liegt vermutlich in einer Symbiose aus KI-Unterstützung und Entwickler-Know-how. Die anstehende Weiterentwicklung von Markdown-Editoren mit intelligenten Funktionen wie automatischer Einrückung und Abschnittsfaltung könnte die Produktivität und das Leseerlebnis für Anwender maßgeblich verbessern. Entwickler und Nutzer dürfen gespannt sein, welche innovativen Lösungen in den nächsten Jahren entstehen.