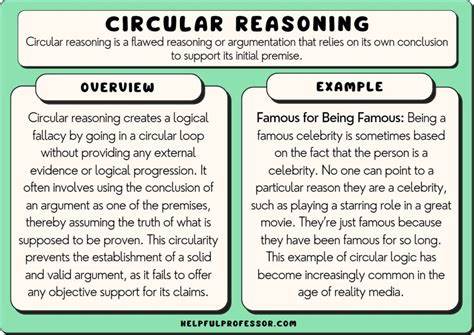
Unit Tests gelten als eine der wichtigsten Methoden zur Sicherstellung der Qualität und Zuverlässigkeit von Software. Sie sind kleine Prüfungen, die einzelne Komponenten oder Funktionen eines Programms isoliert überprüfen. Doch was, wenn die Tests selbst fehlerhaft aufgebaut sind? Ein häufiger, aber wenig beachteter Fehler in Unit Tests ist zirkuläres Denken – das heißt, die Ergebnisse der getesteten Funktion werden im Test mit genau derselben Logik oder einem identischen Ausdruck überprüft. Dieser Fehler verwandelt Testcode in eine Art Selbstbestätigungsschleife, die kaum Aussagekraft besitzt und Fehler leicht übersehen lässt. Ein anschauliches Beispiel ist die Implementierung einer Funktion zur Berechnung des Halbgeburtstages, also des Tages, der genau sechs Monate nach dem Geburtstagsdatum liegt.
Eine typische Funktion in Python könnte so aussehen: Sie addiert dem Geburtstagsdatum eine halbe Anzahl von Tagen, beispielsweise 365 durch 2. Ein Entwickler, der nun einen Unit Test schreibt, könnte versucht sein, die Gleichheit der Funktionsergebnisse mit demselben Ausdruck – dem Geburtstag plus 365 durch 2 Tage – zu vergleichen. Auf den ersten Blick mag das logisch erscheinen. Doch genau hier liegt das Problem: Der Test vergleicht den Code mit sich selbst, anstatt das erwartete Ergebnis mit einer unabhängigen Referenz zu prüfen. Um diese Problematik besser zu verstehen, lohnt sich ein Vergleich mit wissenschaftlichen Methoden.
Wissenschaft beruht darauf, eine Hypothese anhand angemessener und unabhängiger Daten zu testen. Wenn man eine Theorie anhand ihrer eigenen Vorhersagen überprüft, ohne sie mit tatsächlichen, unabhängigen Daten abzugleichen, handelt es sich um eine zirkuläre Beweisführung, die nicht zulässig ist. So wie in der Wissenschaft, sollten auch Unit Tests als kleine Experimente gestaltet sein, in denen die behauptete Funktionalität unabhängig validiert wird. Das von vielen Entwicklern unvermeidlich hingenommene Verlangen, möglichst wenig harte Kodierung von erwarteten Werten in Tests zu verwenden, führt oft zu diesem Fehler. Die Strategie, alles ausschließlich dynamisch zu berechnen, ist zwar im Code selbst sinnvoll, spiegelt sich jedoch im Testcode nicht wider.
Ein solide konzipierter Test benötigt Referenzwerte, die unabhängig vom zu testenden Code erstellt wurden. Diese Werte können von Hand berechnet oder aus vertrauenswürdigen Quellen bezogen werden. Nur so gewährleisten Tests, dass die Funktion wirklich funktioniert und nicht nur den gleichen Code an zwei Stellen parallel ausführt. Nehmen wir den Halbgeburtstag zurück als Beispiel: Statt in der Testfunktion einen Ausdruck zu verwenden, der identisch mit der Implementierung ist, sollte das erwartete Datum per Hand bestimmt und hardcodiert werden. Das mag anfangs mühsam erscheinen, garantiert jedoch, dass Fehler und Abweichungen aufgedeckt werden.
In der Praxis zeigt sich, dass die einfache Addition der Hälfte der Tage im Jahr zu einem kleinen aber entscheidenden Fehler führen kann. Die Division von 365 durch 2 als Fließkommazahl erzeugt eine halbe Tageszeit, die bei Zeitstempeln relevant ist. Die so berechnete Zeit weicht minimal vom erwarteten Datum ab, was besonders in Anwendungen mit hohen Anforderungen an Genauigkeit gravierend sein kann. Darüber hinaus sollte ein durchdachtes Testset über einfache „Happy Path“-Fälle hinausgehen. Edge Cases wie Schaltjahre, unterschiedlich lange Monate und Übergänge zwischen Jahrhunderten gehören unbedingt in die Testabdeckung.
Nur so lässt sich die Zuverlässigkeit der Software auf breiter Basis sicherstellen. Die wachsende Bedeutung von Codequalität und Testabdeckung hat auch Schattenseiten. Oft geraten Entwickler unter Zeit- und Leistungsdruck, der sie dazu verleitet, Tests als reine Formalität abzuhandeln. Dies führt zu weniger belastbaren Tests und kann im schlimmsten Fall falsche Sicherheit vorgaukeln. Ein grüner Testbalken in der Continuous Integration Pipeline zum Beispiel sagt nicht zwingend aus, dass die Funktionalität korrekt ist.
Die dahinterliegenden Tests müssen deshalb sorgfältig konzipiert und auf wissenschaftliche Prinzipien basierend formuliert werden. In der Praxis bedeutet das für Entwickler: Mut zur harten Kodierung von erwarteten Ergebnissen in Tests. Trotz des vermeintlich zusätzlichen Aufwands lohnt sich diese Mühe, weil sie unentdeckte Fehler aufdeckt, die sonst zu unerwarteten Problemen in Produktion führen können. Gleichzeitig fördert dieser Ansatz ein tieferes Verständnis der zugrundeliegenden Logik und der Besonderheiten der verwendeten Datentypen. Auch aus organisatorischer Perspektive sind Tests ohne zirkuläres Denken wertvoller.
Sie erleichtern das Onboarding neuer Teammitglieder, die sich schneller ein Bild über die erwartete Funktionalität machen können. Zudem verbessern sie die Wartbarkeit und Erweiterbarkeit der Software, da Tests Veränderungen an der Logik objektiv überprüfen. Schließlich lohnt sich ein Blick auf Tools und Methoden, die Entwickler unterstützen, fehlerfreie Unit Tests zu schreiben. Automatisierte Testgenerierung, statische Codeanalyse und Peer Reviews können helfen, zirkuläres Denken frühzeitig zu erkennen und zu vermeiden. Ebenso können Dokumentationen und Richtlinien im Team ein Bewusstsein für gute Testpraktiken schaffen.
Insgesamt zeigt sich, dass zirkuläres Denken in Unit Tests ein ernstzunehmendes Problem darstellt, das häufig unterschätzt wird. Effektive Tests müssen unabhängig von der Funktion unter Test sein und auf nachvollziehbaren, validen Erwartungen basieren. Dabei ist die Bereitschaft, auch mal etwas mehr Aufwand für manuell berechnete Werte oder externe Referenzen im Testcode zu investieren, entscheidend für Qualität und Zuverlässigkeit der Software. Unit Testing ist mehr als nur das Streben nach möglichst hoher Testabdeckung. Es ist ein Prozess des wissenschaftlichen Experimentierens, bei dem das Ziel darin besteht, valide Aussagen über das Verhalten des Codes zu treffen.
Nur so vermeiden Teams, dass ihre Tests zu einer endlosen, sich selbst bestätigenden Schleife werden, deren grüner Haken trügerische Sicherheit vermittelt. Für Entwickler, die hochwertige Software liefern möchten, empfiehlt sich daher eine kritische Hinterfragung der eigenen Tests und ein Fokus auf unabhängige Validierung der erwarteten Ergebnisse. Dies schafft Vertrauen in die Softwarequalität und schützt vor unentdeckten Fehlern, die kostspielige Folgen haben können. Mit dem richtigen Bewusstsein und Werkzeugen entspringt aus gut geschriebenen Unit Tests ein echtes Fundament für stabilen und wartbaren Code.