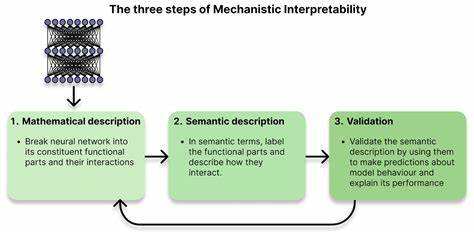
Mechanistic Interpretability, zu Deutsch etwa „mechanistische Interpretierbarkeit“, ist ein dynamisch wachsendes Feld, das sich auf das Verstehen und Erklären der inneren Funktionsweise von komplexen Künstlichen Intelligenzen konzentriert. Insbesondere bei großen Sprachmodellen wie Transformers gewinnt dieser Forschungszweig zunehmend an Bedeutung. Wer sich intensiver mit der Funktionsweise von KI-Modellen auseinandersetzen will, erkennt schnell, dass Mechanistic Interpretability weit mehr als nur ein theoretisches Konzept ist. Es verlangt interdisziplinäre Kompetenzen, eine hohe technische Versiertheit und eine Leidenschaft für das Forschen im Grenzbereich zwischen Informatik, Neurowissenschaft und Systemtechnik. Für viele, die bereits in der Technologiebranche oder der Forschung tätig sind, bietet sich Mechanistic Interpretability als attraktives Karriereziel an.
Die zentrale Motivation dahinter ist der Wunsch, nicht nur oberflächlich zu verstehen, was KI tut, sondern detailliert zu entschlüsseln, wie und warum sie bestimmte Entscheidungen trifft, welche Algorithmen und neuronalen Schaltkreise sie intern aktiviert und wie sich diese Mechanismen sicherer, effizienter und transparenter gestalten lassen. Wer einen Einstieg in dieses Feld sucht, sollte zunächst eine solide Basis in den Grundlagen des maschinellen Lernens besitzen. Viele der in der Praxis verwendeten Modelle basieren auf neuronalen Netzwerken, insbesondere auf Transformer-Architekturen, die den Kern moderner Sprach-KIs bilden. Es ist wichtig, nicht nur theoretisches Wissen aufzubauen, sondern auch praktische Erfahrung bei der Modellimplementierung, dem Training und der Fehlersuche zu sammeln. Schon das Trainieren eines einfachen Modells, das Optimieren von Hyperparametern und die Interpretation von Lernkurven können helfen, die Mechanismen hinter den Algorithmen besser zu verstehen.
Für erfahrene Ingenieure ist Mechanistic Interpretability eine spannende Erweiterung ihres beruflichen Profils. Ihre Fähigkeiten im Umgang mit komplexen Codebasen, die Arbeit mit verteilten Systemen, GPU-Programmierung oder das Entwickeln robuster Visualisierungen zur Verständnissanalyse sind enorm wertvoll. Gleichzeitig raten Experten, gezielt jene Kompetenzen zu entwickeln, die in der Grundlagenforschung gefragt sind. Arbeitsweisen werden sich von typischen Industrieprojekten unterscheiden, da es verstärkt um exploratives Forschen, Experimentieren und das Entwickeln neuer wissenschaftlicher Methoden geht. Die Fähigkeit, eigenständig wissenschaftliche Hypothesen zu formulieren, Daten akkurat zu interpretieren und experimentelle Ergebnisse klar zu kommunizieren, ist hier unverzichtbar.
Wer aus der Forschung kommt und einen Karrierewechsel zu Mechanistic Interpretability anstrebt, muss häufig lernen, sich in industrielle Entwicklungsumgebungen zu integrieren. Während akademische Forschung oft theoretisch und isoliert betrieben wird, verlangt die Arbeit in Industrieprojekten nicht nur fundiertes wissenschaftliches Verständnis, sondern auch Erfahrung im Umgang mit großen und oft verteilten Softwareprojekten. Das Schreiben lesbaren, performanten Codes, die Integration von Testverfahren sowie der Umgang mit modernen Tools zur Versionskontrolle und kontinuierlichen Integration sind wichtige Fähigkeiten. Der Wandel von der Forschung zu angewandter Mechanistic Interpretability erfordert auch die Bereitschaft, neue Arbeitsstile und Teamkulturen zu adaptieren. Hierbei hilft es, aktiv an Open-Source-Projekten teilzunehmen, sich in der Community zu engagieren und von erfahrenen Entwicklerinnen und Entwicklern Feedback einzuholen.
Das Tragen einer sichtbaren Stimme durch Blogbeiträge oder Twitter-Threads über eigene Experimente und Erkenntnisse stärkt zusätzlich die Expertise und den Austausch im Feld. Eine der Hauptbeschäftigungen in Mechanistic Interpretability ist das Erstellen von Modellen und Werkzeugen, die das Innenleben von KI visualisieren und analysieren können. Open-Source-Lösungen wie TransformerLens, Neuronpedia oder NNSight bieten eine hervorragende Grundlage, um erste eigene Experimente durchzuführen. Das Erlernen, wie man komplexe neuronale Aktivierungen decomposiert, einzelne Mechanismen in Transformern – oft als „Circuits“ bezeichnet – isoliert und analysiert, ist essenziell. Sprachmodelle, insbesondere Transformer, legen verborgene Strukturen und Muster offen, die Forscher aus verschiedenen Blickwinkeln betrachten.
Die Methoden reichen von klassischen Attributionsanalysen über Aktivierungsvisualisierung bis hin zu komplexen graphbasierten Repräsentationen, mit denen Zusammenhänge im Modell abgebildet werden. Mechanistic Interpretability strebt es an, diese Strukturen nicht nur zu verstehen, sondern auch zu wirken, um das Verhalten von KI kontrollierbarer und vorhersagbarer zu machen. Die Herausforderungen in diesem Gebiet sind groß, da viele fundamentale Fragen noch offen sind. Es besteht Unsicherheit darüber, wie genau die Modelle lernen und welche internen Abläufe in den verborgenen Schichten stattfinden. Dies macht die Arbeit besonders spannend, da sie stark exploratorisch ist und Raum für innovative Lösungsansätze lässt.
Wer sich mit diesen Unsicherheiten wohlfühlt, besitzt eine wichtige Eigenschaft für den Erfolg in diesem Forschungsbereich. Zusätzlich zur fachlichen Expertise sind Kommunikationsfähigkeiten ein wichtiger Bestandteil. Mechanistic Interpretability bewegt sich an der Schnittstelle von Technologie, Forschung und Gesellschaft. Die Fähigkeit, komplexe Erkenntnisse verständlich aufzubereiten, ist entscheidend, um das Vertrauen in KI-Systeme zu stärken und Lösungen gemeinsam mit Stakeholdern zu entwickeln. Eine Karriere in Mechanistic Interpretability eröffnet zudem Zugang zu einem lebendigen, globalen Netzwerk von Forschenden, Entwicklerinnen und Ingenieuren.
Es gibt zahlreiche Communities, Foren und Diskussionsplattformen, die den interdisziplinären Austausch fördern. Hier bieten sich Möglichkeiten zum Lernen, zur Zusammenarbeit an Open-Source-Projekten und zur Teilnahme an Konferenzen wie der NeurIPS oder speziellen Workshops zur Interpretierbarkeit. Unternehmen wie Anthropic oder OpenAI treiben die Forschung in Mechanistic Interpretability aktiv voran. Wer sich für eine Anstellung interessiert, sollte sich mit aktuellen Forschungsarbeiten vertraut machen und eigene kleine Projekte vorweisen können. Das Einbringen eigener Ideen in Form von Blogbeiträgen oder Beiträgen in der Community wird häufig positiv bewertet.
Es lohnt sich ebenso, die Karrierewebseiten dieser Firmen zu beobachten und sich frühzeitig mitbewerben. Für Einsteiger sind online verfügbare Tutorials, Mini-Projekte und interpretierbare Beispielmodelle eine ausgezeichnete Möglichkeit, praktische Erfahrungen zu sammeln. Unterstützt werden diese Ressourcen von aktiven Gemeinschaften und Mentoringprogrammen, in denen erfahrene Forschende ihr Wissen weitergeben. Dabei ermöglichen englischsprachige und deutschsprachige Angebote den Zugang für unterschiedliche Zielgruppen. Mechanistic Interpretability ist mehr als nur ein vager Trend, sondern ein Schlüsselbereich, der dazu beitragen wird, die nächste Generation von KI-Systemen sicherer, transparenter und vertrauenswürdiger zu machen.








